Introduction
Between the years 2009 to 2013, one of us (hereafter referred to as the modeller) developed a so-called nutrient export coefficient model (ECM) in a Bayesian framework as part of an analytic-deliberative management project for the Tamar river catchment (UK). Modelling aimed to help stakeholders–land owners and land managers, government agencies, water companies, civil society organisations–assess nutrient pollution in the catchment, identify responsible sectors, and explore mitigation options. The model was tailored to the location. It eventually influenced the management plan for the Tamar in a follow-up project under the UK ‘Catchment Based Approach’ to water resources governance. The Bayesian framework was chosen to express the various uncertainties perceived in the modelling process. In this article, we take this project as a case to situate Bayesian knowledge practices.
Bayesian statistics interprets probability as a degree of belief in a proposition, while frequentist statistics focuses on the relative frequency of an event’s occurrence in a long run of repeat experiences. Bayesian modelling, therefore, enables scientific inference by assigning probabilities to any uncertain elements in a model, including parameters, input data, and model structure (see Box 1)1. The Bayesian modelling workflow comprises a number of activities which we describe as ‘practices’: building the model structure, preparing the data, defining the likelihood function, defining the prior, implementing the equations, sampling from the posterior, and model checking and revision. Although modellers typically follow this workflow, they differ in how and to what extent they engage in each of these practices.
Box 1: A very short introduction to Bayesian modelling
Central to Bayesian inference is Bayes’ rule, which updates a joint prior probability distribution of the uncertain elements of the model to a joint posterior probability distribution. The ‘prior’ reflects the degree of belief before, while the ‘posterior’ reflects the degree of belief after considering data. Updating from prior to posterior is done through the likelihood function, which embodies the (deterministic) ‘model structure’ and all uncertainty components. This all happens in the numerator of Bayes’ rule. The denominator effectively normalises the equation. The result is, again, a probability distribution:
$$Pr(\theta|y,M,X)=\frac{Pr(y|\theta,M,X)Pr(\theta|M,X)}{\int{Pr(y|\theta,M,X)Pr(\theta|M,X)d\theta}}$$
$Pr(\theta|y,M,X)$ is the posterior probability distribution of possible parameter values conditional on the data for what the model predicts $y$, model structure $M$ and model input data $X$.
$Pr(y|\theta,M,X)$ is the likelihood function, i.e. the probability of the data $y$ conditional on the parameters, model structure $M$ and input data $X$.
$Pr(\theta|M,X)$ is the prior probability distribution of the possible parameter values conditional on the model structure $M$ and input data $X$.
In this notation, everything is explicitly conditional on the model structure and the input data. Bayes’ rule kept simple could leave out $M$ and $X$. In an extended Bayes’ rule, one could calculate the posterior probability jointly over $M$ and $X$. In this case, one would have to add priors over $M$ and $X$ on the right-hand side. In the above notation, the only uncertain quantities of interest are the values of the model parameters $\theta$.
The academic mainstream perspective on Bayesian statistics underwent a turnaround in the 20th century. Especially in the first half, Bayesianism was shunned by some for its ‘subjective’ notion of probability and even considered ‘unscientific’ despite extensive application in practical problems2. Until today, some researchers may avoid Bayesian statistics on account of its supposed ‘scientific relativism’3, subjectivity4, or conflation of probability with ‘opinion’5. In recent times, however, Bayesian statistics and modelling have become increasingly popular due to their usefulness in analysing data sets with small sample sizes and other sources of uncertainty. Even more recently, Bayesian methods find applications in artificial intelligence6 and quantum computing7.
Along with a shift away from conventional understandings of scientific objectivity8 as well as computational advances in solving Bayesian problems, some proponents now claim that the Bayesian framework yields a necessarily subjective understanding of knowledge that deviates from the old notion of knowledge-world-correspondence9, rightfully incorporates belief in conceptions of evidence10 or objectivity11. Some argue that the Bayesian framework rightfully expresses the context-dependence of any knowledge claim and the relativity of evidence12, or indeed increases objectivity by strengthening the transparency of scientific reasoning13. The Bayesian framework even finds application in attempts to resolve conventional science philosophical debates14. Some proponents take a more cognition-centred approach. They consider Bayesian knowledge production equivalent to inductive reasoning15, analogous to the way in which humans learn in context16, to ‘enactive’ human cognition, ‘predictive’ perception and the production of rational or action-guiding behaviour17.
Yet, these arguments for and against Bayesian thinking seem to be based on a common conceptual foundation. Within debates on whether the Bayesian perspective on probability is truer to the nature of knowledge (because it is subjective, relative, situated or situational, possibly more plural) or less true to it (because it is subjective, mind-dependent or useless in the search for truth), both sides argue within the same conceptual space. Authors claiming that Bayesian knowledge is superior knowledge, pointing to, for example, the context dependence and relativity of evidence18, indeed seem to mirror their opponents’ implicit conception of knowledge as a singular object. Their reasoning suggests that knowledge is a fixed, universal notion–a referent that has a truth to it–and that we can therefore discuss methods based on how well they account for this truth by implementing principles such as accuracy, transparency, relativity, context-dependence or else.
Feminist and decolonial authors, instead, draw up a relational understanding of the world and of knowledge that stands in contrast to standard epistemological approaches. It renders knowledge production a ‘[way] of living with the real’19 or ‘being in the world’20 subject to real entanglements and productive of them21. Haraway’s notion of situated knowledges, for example, suggests a relational understanding which recasts objectivity in terms of the privilege of partial perspective. She suggests unpacking the way in which particular material-semiotic actors, in conjunction with knowledges themselves, produce other partial knowledges–knowledges that are locatable in webs of connections22. De la Cadena23 points to the historicity and contingency of scientific categories, questions, principles, theories, and frameworks and their performative relationship with the world, to call for the preservation of onto-epistemic openings24. Mol25 has developed the concept of ‘enactment’. She traces how ‘objects’ emerge through practices, including practices of knowledge production. Barad26 has described science in terms of ethico-onto-epistemological apparatuses27 that connect subject and object. Each of these authors makes distinct contributions, which cannot be smoothened into a single research programme.28 Yet, all of them expressly move away from the epistemological, in favour of an approach to knowledge that centres on ‘practices, doings, actions’29 and asks not whether they are accurate to what knowledge intrinsically is or ought to be, but which relations they make30 and whether they represent worthwhile ways of being with the real31.
Drawing on work in this tradition, we adopt a relational approach to knowledge to analyse Bayesian modelling. From this perspective, knowledge is not a singular referent, whose truth we ought to discover and implement through methods appropriate to what knowledge truly is. Contrary to the above-cited, epistemologically inclined texts on, for example, the superiority or inferiority of Bayesian over frequentist thinking32, our approach casts knowledge as a multiple object in the making. In this sense, knowledge and knowing emerge together. The very ‘nature’ of knowledge itself is in emergence along with knowing ‘subjects’ and known ‘objects’. This suggests a focus on the ‘practicalities of doing’33 knowledge, as opposed to the implementation of methodological principles.
For statistics, previous work such as that of Hacking34 on the historicity and contingency of epistemology and statistical concepts in particular ‘situates’ statistical knowledge by locating it within temporal, political, infrastructural, and geographical relationships. Poovey35 investigates the entwinement of the ‘modern fact’, the foundation of statistical thinking, with organisational principles ‘by which subjects of the modern world manage [their] relationships with each other and with society’36. More specific empirical work explores, for example, how data-centred approaches to knowledge production emerge along with political, social or ethical ordering principles, emphasise the presence and visibility of aspects of the world such as regularity, reconfigure social relations and co-shape entities37. For models in particular, Klein et al.38 have developed the term ‘situated modelling’ to suggest that situated knowledges demand reflection on and reconfiguration of the positions from which scientists build and apply models. These perspectives consider knowledge practices an object of social scientific inquiry, ask how they are situated and bring specific worlds to realisation.
Against this background, we document a collective process of critical inquiry into Bayesian modelling practice in this contribution to develop insights into Bayesian knowledge. Reaching beyond existing epistemological discussions to examine science in action, we believe this will contribute to philosophical and (social) scientific debates on Bayesian ways of knowing. Yet our discussion also speaks to, among other things, debates on the mathematical affordances that play out in Bayesian modelling practice, including the necessity for probabilities to sum to one39, the assumed space of models40, the numerical solvability of Bayesian models, and the lack of a built-in mechanism for the rejection of hypotheses41.
Ultimately, we argue that ‘Bayesian’ ways of knowing, although some have suggested that they align with a ‘contextual’ or ‘relative’ notion of knowledge42, do not automatically account for feminist and decolonial conceptions of situated knowledges and plural world(ing)s. We suggest, along the case at hand, that Bayesian knowledge is no less universalising in itself than, for example, frequentist knowledge. A Bayesian story about knowledge may indeed be a partial perspective itself.43 From a feminist STS perspective, then, it is more meaningful to reflect on how Bayesian knowledge is ‘done’ than to focus on its theory or methodology. Relationality, from this point of view, extends far beyond the relationship between evidence and hypothesis, and between prior and subjective contextual knowledge. As we will show in this paper, actors who know from outside the Bayesian logic can thus unsettle the Bayesian workflow in productive ways. Eventually, we argue that Bayesian analysts can therefore benefit from engagement with other ways of knowing, to engage in worthwhile ways of living with the real and assume responsibility for the worlds they enact.
Methodology
As a heterogeneous collective44 of scholars, we combine interdisciplinary backgrounds in geography, human geography, hydrology, mathematics, statistics, anthropology, European ethnology, philosophy of science, political science, sociology, and science and technology studies. Two of us are also Bayesian modelling ‘practitioners’. Four of us do social science research on modelling practices.
Together, we explored a case of Bayesian modelling, for which one of us had been the lead scientist. Our inquiry builds on the two co-authors’ expert knowledge and experience of the practice of Bayesian modelling, as well as on interpretive concepts and methods for researching modelling practices which some co-authors had developed through ethnographic research. Krueger and Alba (2022) provide some background information about the case study45. Several aspects of the model have been discussed by Klein et al. (2024)46.
To make sense of Bayesian knowledge production as a way of living with the real, we complement the Harawayan attention to material-semiotic positions with Mol’s methodological proposal for tracing how ontologically multiple (knowledge) objects become single objects-in-practice. Haraway’s notion of ‘situated knowledges’ holds that knowledges, produced by concrete knowers in concrete situations, are performative. They are also ‘actors’47, they ‘build meanings and bodies’48 and ‘other objects of value’49 in conjunction with knowledge ‘objects’, which are active entities themselves. Therefore, knowledge claims ought to be responsible, because they exist in a mutually reciprocal relationship with knowledge objects, politics and ethics50. Yet, Haraway in Situated Knowledges does not offer a methodology for ‘interrogating positionings’51 with regard to how they contribute to this emergence of ‘various […] bodies’ or ‘embodiments of the world’, or interfere with objects of knowledge as ‘material-semiotic generative nodes’52, apart from indicating that their ‘boundaries materialize in social interaction’53. The Molian concept of ‘enactment’ allowed us to conduct an analysis that explores which objects and versions of objects emerge in our case study. It holds that ‘ontology is not given in the order of things, (…) instead, ontologies are brought into being, sustained, or allowed to wither away in common, day-to-day, sociomaterial practices’54. What people perceive as ‘objects’ are therefore multiple, dynamic entities, and sociomaterial practices enact versions of these ontologically multiple objects. The concept of enactment and the accompanying analytical inquiries enable us to also uncover hidden ‘objects’ in the making. This approach allowed us to go beyond examining the relationships between preconceived objects, such as the ‘performative’ effect of a Bayesian approach on the overt object of the case study project, and to thus explore the multiple entanglements of Bayesian practices with various aspects of the world.
In 2024, we embarked on a collaborative investigation of the case study. We compiled extensive documentation on the project, including published and unpublished materials. We conducted two interdisciplinary workshops in the first half of 2024, which we recorded. During the workshops, we explored the case study together through presentations, listening and dialogic questioning from our different practical and disciplinary vantage points. We also began to engage in some preliminary collaborative analysis. Drawing on Mol’s approach for tracing the making of objects-in-practice to find out what Bayesian knowledge practices do in/to the world, our analytical exercises revolved around singling out relevant practices, examining what the modeller and other involved parties reportedly said and did, and asking questions such as ‘Which ‘objects’ does this way of doing things enact?’, ‘Which version of this ‘object’ does it enact?’ via the proxy questions ‘Which attributes does this ‘object’ appear to have?’, ‘What can and can’t it do?’, ‘How is it implicitly differentiated from other versions of the same ‘object’ and from other ‘objects’?’ and ‘Which relationships does it sustain to other ‘objects’?’. Eventually, an ethnographer in the team analysed the resulting material, asking similar questions and applying concepts partly developed elsewhere55. They used an iterative approach to coding and writing memos.
In doing this interdisciplinary inquiry, we sought to attend to feminist methodological sensibilities, foregrounding ‘the how of science’56, grounding our critical reflection on a scientific ‘method’ in its practice57, and combining various partial perspectives58 on what is going on in and with Bayesian knowledge practices. Throughout the paper, we seek to retain the visibility of this partiality through form by 1) preserving two different voices, employing, among other things, two different font colours and 2) adhering to a ‘modeller’s approach’ to structure in presenting the Bayesian workflow instead of organising it along interpretive concepts and analytical points. In grey we employ a ‘descriptive’ voice, narrating the Bayesian model(ling) in a manner familiar to hydrologists, which perhaps invites a more conventional epistemological inquiry. Each chapter begins with such a ‘naturalised’ account to present the following deconstructive-analytical segments, written in black, as a text that is also made and partial. We use the different colours, reflecting different ideas of what Bayesian knowledge is, to point to the partiality of our own understandings and to invite the reader to critically partake in the making of webbed connections–potentially going beyond what we present here. We intentionally preserve the breaks between the two styles in order to make them both palpably unnatural.
Bayesian modelling practices, and how they produce situated knowledges
$ M$ Building the model structure
In a Bayesian framework, the model structure $M$ refers to a set of equations that relate some model input variables $X$ to some model output variables $Y$, or single output variable $y$. It contains parameters $\theta$ that are estimated from the data (see Box 1).
Bayesian inference is always conditional on the selected model structure $M$, what it includes and excludes and how it does so. Bayesian inference does allow for comparison between various model structures, but only within the specified set of structures, implicitly considered an exhaustive set of hypotheses. Model comparison also comes with the challenge of having to specify a prior distribution over the set of model structures which are not independent.59
In the case at hand, the modeller developed an ECM for the Tamar catchment. An ECM models nutrient loads in a river draining a catchment. The loads represent the mass of phosphorus or nitrogen that passes through the catchment outlet per year. An ECM assumes that this load can be modelled as a function of different inputs: land use and management, livestock, roads and tracks60, sewage treatment and other industry in the catchment61. Each input contributes a characteristic annual nutrient load into the river, the ‘export coefficients’ which together make up the bulk of the parameters $\theta$ of the model. Other parameters are the effects of land management practices in reducing nutrient exports62 and the ‘decay’ of nutrient load through net deposition of phosphorus and degassing of nitrogen along the river network,63 which allowed the model to functionally connect subcatchments (Figure 1).
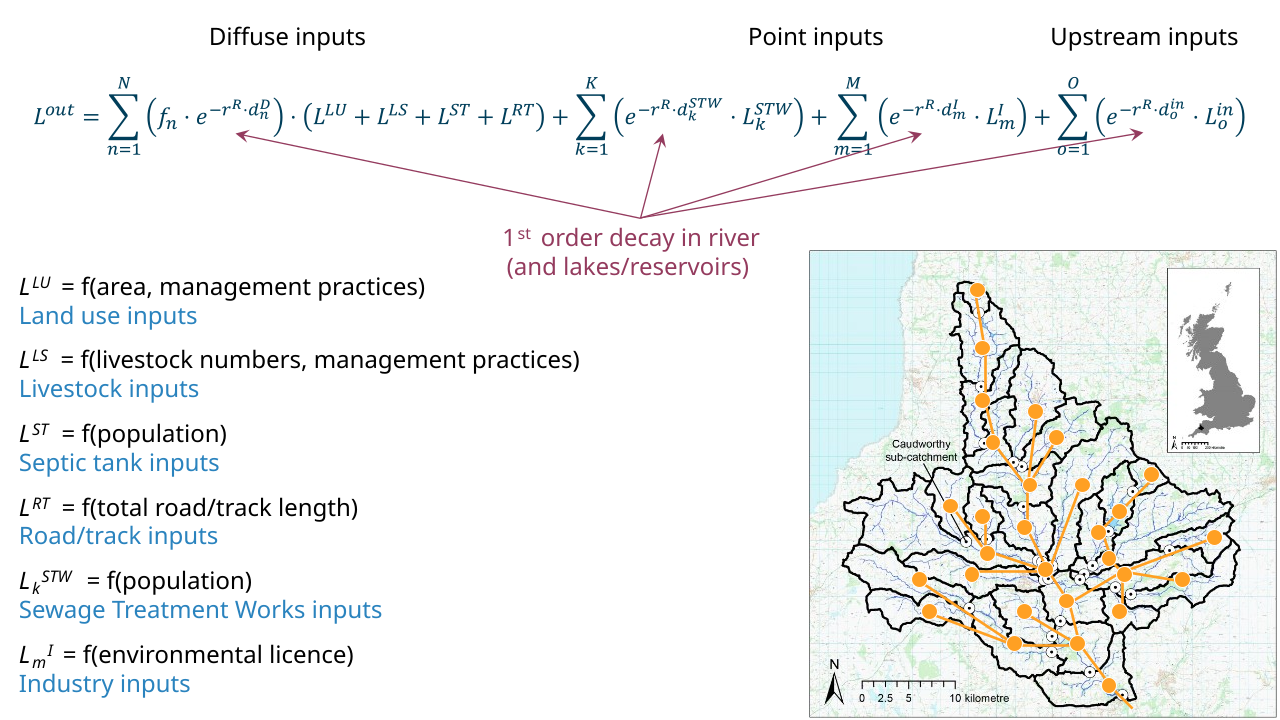
Figure 1: Representation of the model structure. The map symbolises the networking of subcatchments of the Tamar. The equation symbolises predicted load at a subcatchment outlet as a function of inputs from land use, livestock, septic tanks, roads/tracks, sewage treatment works, industries and upstream, which decay with distance ‘d’ and decay coefficient ‘r’ along the river network (and, not shown, in lakes and reservoirs). The various inputs are a function of subcatchment scale processes and data. Agricultural management practices are omitted from this figure. Contains OS data© Crown copyright and database right 2016.
Calibration was done on 29 subcatchments, i.e. the model had to satisfactorily match – in a Bayesian sense – the data collected routinely at these subcatchment outlets as part of national water quality monitoring.
The model’s consistency was thus assessed in space but not in time. Input data such as land use maps had only been produced at coarse intervals and data on land management practices had been elicited from farmers and farm advisors only for the recent time. The model thus reflected ‘recent’ weather conditions, and any simulation of management interventions would be conditional on them. To make this approach more robust, 5-year average loads were modelled and the monitoring data aggregated accordingly.
Zooming out of a technical view of the model-building process, the entities and relations that a model structure includes or excludes are not only ‘conditions for Bayesian inference’, as mentioned above. They can also be considered, for example, according to how they are embedded in specific frameworks, types of models, thought styles64, and scientific disciplines, as well as their consequences for what can and cannot be known, and therefore acted upon, through the model.
A hydrological framing, just as any other framing, necessarily closes debates on what water and pollution are. Received scientific framings and existing regulatory frameworks interact in suggesting ontological decisions in building the model, which in turn suggest that there is a situation in need of action and a specific kind of problem, which can be solved by certain means65.
The separation of ‘phosphorus’ and ‘nitrogen’ in the model structure, for example, is situated within a received scientific framing of chemical elements according to their essential properties rather than their effects or relationships. At the same time, the model structure relates to the regulatory framing of the research project, the EU Water Framework Directive (WFD). The WFD postulates a separation of ‘humans’ and ‘environment’, in which humans negatively impact the environment, but are also in a unique position to mitigate this impact66. Harking back to an imaginary of control, science is thus required to assess those impacts and suggest remedial action67. The explicit inclusion of subcatchments in the model at hand, moreover, stemmed from the need for both calibration and data availability. Administrative conventions for governing the geographical area and producing data for doing so interacted in relevant ways with the knowledge generated through the model.
In addition, knowledge on how to assess impacts and suggest remedial action contains a partial perspective and participates in producing partial perspectives on another level. Different types of model structures such as, in this case, an export coefficient model serve to construct differently where to locate a problem and how it can be solved. Although it incorporates sewage treatment efficiency, for example, the model structure constructs a problem that cannot (or should not) be solved by removing phosphorus and nitrogen from the river. A chemical or environmental engineering framing, instead, may have made it seem necessary and plausible to consider such questions.68 A perspective rooted in sociology or economics might have prompted building a model that incorporates entities and relationships relevant to managing consumption, addressing questions such as ‘How can we curtail the demand that drives industries to emit excessive levels of phosphorus and nitrogen?’. The model structure at hand, instead, does not make explicit consumption patterns, e.g. of meat and dairy products. In this sense, it naturalises demand, consumption, and the internal workings of the sectors by explicitly including only bulk nutrient outputs69.
On a closer look, this way of building the model structure, beyond being embedded in scientific disciplines, thought styles, and regulatory framings, enacts a management model that participates in remaking relations and a particular version of the good70. It embodies value-laden assumptions regarding the social, appropriate ways of governing it, and on the nature of the (public) ‘good’71. First, it privileges a view of the social and of collective action according to which independent, generalised types of actors interact in specific ways: sectors interact with local government in the regulation of pollutants. This excludes a view on the political according to which, for example, consumers interact with sectors, sectors with sectors, global entities with sectors, webs of meaning with sectors’ activities etc. The model structure does not afford asking how to reduce this aggregated amount through avenues such as maintenance, consumption patterns, value change, landscaping, or nutrient removal.
In this way, the model locates harm at a point that is a ‘source’ only relative to certain perspectives and understandings of the world. It shifts attention to a locality in which the problem becomes visible, arguably not to the unambiguous cause of the issue. By establishing these kinds of relations and variables, the model structure aligns more with an approach to assessment that asks how harm might be mediated than with an assessment approach that questions dominant patterns of pollutant generation and use72. In this sense, it represents a partial perspective contingent on a particular situation and particular assumptions.
This localisation links to specific ideas on where researchers and policymakers can and should intervene. Building the model structure in this way excludes, for example, a view of pollution as a systemic effect. Such a view may afford a consideration of the extent to which all sectors are affected by some common principles or paradigm73 that produces nutrient inputs into rivers. Another alternative model structure could have refrained from generalising from the subcatchment to the catchment level, resulting in a higher visibility of concrete farms or parts of the road network in the catchment area74. This, in turn, may have made sense when wanting to explore—and at the same time could have made seem sensible—more targeted local action.75 Moreover, different types of soil, topography and hydrological connectivity are not included in the model, although they impact run-off and eventually water quality. The model structure at hand, instead, is built to enable policies at the sector-level around standardised interventions for regulating a preconceived range of ‘sectors’.
Building the model structure thus enacted a version of responsibility for pollution, which prefigured certain possible responsible actors while excluding others. This responsibility neither results from a system that brings forth pollution, nor lies with consumers, nor with actors that engage in grave misconduct–the contribution of sources such as industry and sewage treatment facilities, for example, is not broken down further into actors that pursue ‘good’ and ‘bad’ practices. Instead, the only kind of ‘responsibility’ that can be assigned by means of this model lies with the sectors, whose activities are assumed to contribute to the nutrient loads at the catchment outlet. Building the model in this way enacts a version of ethics that revolves around general outcomes. By including decay and decomposition, and loads calculated at subcatchment outlets, the model structure embodies the assumption that not concrete input as such, or input above a certain threshold per source matters, but what generally remains of the input.
This contributes to enacting the ‘good’ itself. By abstracting from people to sectors, building the model structure obscures, for example, the particular relations that farmers may have with their land, be they financially-strained or culturally-significant. These relations may, however, play a role in their capacity for transformation, while an industrial spill on the other hand may be prevented with comparative ease. In terms of attaining the good–here, a mitigation of pollution–the model structure does not provide a relational kind of view on the constraints, or dependence of concrete actors within the sector on certain kinds of practices that produce nutrient inputs to rivers, nor a perspective on unequally distributed capacities to change or unequal burdens, benefits, and obligations within the group of involved or affected actors.76
In this sense, model building enacts a version of ethics that revolves around identifying points for intervention to mediate outcomes in terms of one good (reduced pollution levels), while institutionalised structures–sectors, but also consumption patterns, relations that characterise the nutrient cycle–are bracketed from inquiry. The model structure partly enables seeing which changes could be made to adjust the outcomes of the relevant sectors’ activities. But it does not enact a good that requires a comparative approach to all potential action options for reconfiguring activities at all levels and scales. Instead, it remains at the sector level, suggesting that sectors are meaningful units for analysis and management, although rules for action in some sectors (land management practices77) could be changed.
Modelling in this way also enacts specific ‘land relations’78. The modelled elements and relations foreground relations of water use and a single good–a lower nutrient load–that benefits an abstract mass of people in the region in universal ways. We could imagine an alternative model that, for example, manages nutrient sources in a way that will induce only minimal or justifiable drawbacks for most people living in the region. Such a model would perhaps need to consider the contribution of ‘luxury’ goods79 to the load. Yet another alternative could have facilitated considering various, perhaps even multispecies goods that sector activities contribute to (or not), to evaluate policy interventions in light of plural incommensurable goods.
In this sense, the model structure creates an artificial situation in which all sectors’ productive activities are equal, disregarding any unequally distributed and situated needs for plural values attached to them, and the potential realities of attempting their transformation. In terms of policy making, this enables a discussion that assumes that responsibility for pollution can indeed be assigned based on contributions to the general load. From this perspective, interventions may target different individuals (via sectors) with equal legitimacy, disregarding that one could, for example, figure an agent’s knowledge, capacities, and concrete relationships into the attribution of responsibility.
$ X,y$ Preparing the data
As for any modelling, the data needed to run and calibrate a Bayesian model ($X$ and $y$) rarely exist in a form and resolution that can easily be combined with the model. Data need to be prepared to fit the model resolution and the conceptual understanding of variables encoded in the model structure. Vice versa, the type and availability of data plays a role in building the model, as we have seen in the previous section. As a result, theories related to both model and data are being operationalised so as to coordinate the interaction of model, world, data and modeller.80
In the case at hand, the model simulates loads (masses of phosphorus or nitrogen per year) while the monitoring data were concentrations (masses of phosphorus or nitrogen per volume of flow) at different times. These so-called instantaneous concentration measurements were aggregated to 5-year average concentrations. To match the monitoring data, the 5-year loads simulated by the model were divided by total flow volume estimated at the monitoring sites to translate them to 5-year average concentrations.81
Land use and livestock information were taken from the then most recent 2010 Agricultural Census. The data were aggregated to 14 land use and 4 livestock classes using the then most recent Land Cover Map. Thirty-six best management practices (BMPs) to be reflected in the model were chosen together with farmers who were stakeholders in the project. The locations of the Sewage Treatment Works (STWs), their nutrient removal efficiencies and the numbers of people connected to them were acquired from the responsible water company. Based on these numbers and the total population in the catchment, the number of people connected to septic tanks per subcatchment was estimated. The length of roads and tracks per subcatchment was taken from the Ordnance Survey (OS) Master Map. The OS Master Map also served to extract the river network and lake/reservoir areas as proxies for nutrient load travel time. Phosphorus and nitrogen decay was modelled as a function of river length and reservoir/lake area, respectively.
From the above description, we can already conclude that Bayesian inference was conditional on a variety of data preparation steps. The uncertainties of the relationship between load and average concentration and many more steps were not considered. From this perspective already, the resulting posterior distribution does not span all choices that could have been made.
On a more fundamental level, categorising, labelling and codifying–practices central to any statistical knowledge practice–produce partial perspectives. First of all, they embody a specific mode of apprehending difference: Statistical knowledge affords a way of making the world intelligible in terms of hierarchical relationships between instantiations of categories.82 Based on this subordination of difference to identity83, statistics foregrounds certain kinds of differences84. On a more practical level, statistics caters to a universalising lens that highlights coherence over outliers, although the latter may hold important insight on which unknown processes generated the data. We describe in one of the following sections how this aspect of situated statistical knowledge became and could have become performative in the research process at hand.
Second, on a more closely empirical level, data is interpretation85. Statistics is always based on judgement and provides information in need of interpretation86. But it is also ‘always already social’87. Technologies of data collection emerge in interaction with practices imbued with certain worldviews and scientific conventions for pre-existing categories88. Data categories may in turn afford particular ways of seeing, because researchers are trained to detect problems and find solutions in, for example, the water body they were trained to see89. The selection of indicators, meanwhile, interacts with funding sources90 and political considerations91. In addition, data categories necessarily exclude other available ones that may express overlapping interpretive concepts which people use to make (other) sense of their lives. Ultimately, setting up data categories means ‘alter[ing] aspects of the world that concern (our emphasis) us so that they resemble (…) artificial randomisers like dice’92. Thinking in these terms makes certain things and versions of ‘research objects’ perceptible, while other things escape them93. This, in turn, makes some ways of interacting with the world plausible and possible.
In the research process at hand, pollution, for example, was altered to become nutrient ‘load’, an ‘artificial randomiser’ that facilitates building a model. Thinking in terms of loads, though seemingly ‘neutral’, enacts a particular version of pollution, which plays a role in what we can and cannot know about the issue at stake and which actions therefore seem plausible. At the same time, the practice of calculating the load via 5-year average concentrations at the catchment outlet results in a partial perspective on the harms that arise which, again, has consequences regarding who can be made responsible for what, and for the goods that can be considered, including whose goods.
The ‘load’ numeralises pollution; it serves to produce numbers that can be plugged into a model. Pollution could be, again, ‘otherwise’94. For example, it could be harm95, a ‘[matter] out of place’96, or a threshold97. Different versions of pollution relate to norms that play a role in methodologies for studying it and in the development of countermeasures98.
Generalising to nutrient loads may obscure the role of existing human relations with water and the dynamic construction of norms and practices that exist around both water and the sectors in question. How many cows are needed, but also how much phosphorus a farm produces, for example, are contingent on malleable mediating conditions.99 The same goes for the assumed link between people connected to SWTs100. This puts limits on universalising practices such as formalising relationships between farms and phosphorus across contexts. These limits may however become hidden when foregrounding the ‘load’ as a 5-year average measured at the catchment outlet.
Moreover, the nutrient ‘load’ may obscure the values inherent in water quality judgements and suggest the appropriateness of ‘object-given ethical reasoning’101. Degraded water is an established problem, rendering standard minimums for nutrient loads or elimination of certain pollutants altogether ‘obvious’ means for maintaining an intrinsic good. Thinking in terms of the ‘load’, however, enacts a version of the good that is a good of humans only. It leaves no room for other species. This good resides on the regional scale and is agent-neutral. The people whose good is under consideration seem to be an abstract mass: thinking in terms of the load–an object giving reasons to advance the good–suggests that all those affected are affected in uniform ways and can become responsible in uniform ways, irrespective of their concrete relationships, capacities, actions and so on.
On the action side, data preparation for the model at hand enacts a version of responsibility which can be arrived at through loads via average concentrations. Preparing input data in this way again suggests that it is not per se bad to discharge potential toxins at a particular point in time. Pollution, it seems, arises at the outlet over the course of five years. Responsibility relates to contributions to harmful aggregate amounts, rather than to whether an individual actor’s contribution is directly harmful (much less unjustified or avoidable) at a particular point in time. The load-as-pollution is bad for all people in the region and possibly beyond, regardless of how it affects whom, when and where. Handling data in this way suggests that it is not important to know who or what has produced which amount of discharge at concrete points in time during the 5-year period relevant to calculating the load from average concentrations. It also suggests that it is unimportant why or how the discharge has come to be, or which harms may have arisen over the course of producing it in the region and beyond, including through mining for fertiliser production elsewhere.
But nutrients are not and have not been pollution per se, in equal ways, for everybody. Nutrients are made problematic because of historical developments over time, given a specific global socio-economic system, particular epistemological developments, and particular notions of the public good, including who is relevant for ethical reasoning. Phosphorus and nitrogen pollution have a history of unevenly distributed global patterns of exploitation102, and corresponding decisions on which ethical subjects and harms to consider and weigh over others.103Place-based relations and practices, histories, norms, values and culturally-specific practices, including methodologies, make pollution what it is104. Figuring a chemical element in terms of a ‘load’ obscures that pollution can alternatively be understood as a set of relations or a way of living with incumbent political and economic structures105.
Other methodologies might have also foregrounded that nutrients can have different relationships with different beings or things106. Distinctions between dissolved organic phosphorus, particulate phosphorus and soluble reactive phosphorus, for example, are made in freshwater ecology, because bacterioplankton also require phosphorus107. A biological or ecological lens might consider the interplay between nutrient availability108, mix of nutrients available and time. The alternative concept of nutrient ‘availability’ shifts attention to complex processes that include aquatic organisms, their life cycles, water, time, nutrients and other factors.
From this perspective, the concept of ‘load’ affords a way of seeing pollution as an object and nutrients as discrete molecular actors, while they could alternatively be understood, for example, in terms of a set of relations or practices. The model at hand neither constructs a relational account of the load nor of how the needs of different groups of people–local, regional, global, consumers, producers–or of different species–cows, people, bacterioplankton–interact in the problem at hand. Framing the issue in terms of nutrient ‘load’ largely enacts a good that relates primarily to an abstract mass of universal people who control natural resources and the benefits they produce for human life on a regional scale. For this, too, alternative practices in knowledge production more broadly but also in data preparation in particular would result in other doings, produce other partial perspectives and other consequences.
$Pr(y|\theta,M,X)$ Defining the likelihood function
The likelihood function connects the model structure $M$ and the data $y$ to learn about likely values of the parameters $\theta$ (and any other uncertain quantities of interest). Formally, it is the probability of the data $y$ conditional on hypothesised parameter values $\theta$, and also conditional on the model structure(s) $M$ and the input data $X$. This requires an additional probabilistic assumption to the model structure $M$ that maps the model output to the data of this output $y$. This probabilistic component represents everything that remains unexplained by the model structure. The choice of likelihood function is ambiguous and makes a difference in prediction as shown by Cooper et al.109, for example.
In the case at hand, the likelihood function used for parameter calibration via Bayesian inference was a custom likelihood function, specifically the posterior probability of 5-year average phosphorus or nitrogen concentration at the 29 subcatchment outlets as per Krueger110. The use of a custom likelihood instead of a closed form likelihood is known as Approximate Bayesian Computation (ABC)111. The joint likelihood over the 29 locations was the product of the individual likelihoods as per Bayes’ rule.
ABC can be used to produce a custom likelihood when the likelihood function does not have an analytical form, i.e. when the analyst wants to represent an ‘oddly shaped’ likelihood for which no equation exists. It approximates the likelihood function by simulating datasets for parameter values by repeatedly sampling from the parameters’ prior distribution and comparing predictions to observed data including their estimated uncertainties. The uncertainty distribution of the observed data serves as the measure of tolerance for the discrepancies between prediction and data to form the likelihood function112.
Defining the likelihood function is the first step in the described process that happens in a Bayesian but not necessarily in other modelling processes. It serves to handle uncertainty and to engage in uncertainty reduction by enabling the ‘updating’ of the prior to the posterior distribution. Given the all-important work the likelihood function performs in Bayes’ rule in updating prior to posterior distributions, it is perhaps surprising that it has received much less scrutiny and critique in the literature compared to the prior.
The setting of the likelihood function is a seemingly technical operation which, however, has non-technical consequences. By enabling knowledge production under ‘uncertainty’, the setting of the likelihood function enacts an action-oriented version of knowledge, as opposed to, for example, scientific practices that foreground determinist explanations, ‘demonstrative’ knowledge113 or theory building. In this sense, it contributes to a partial perspective on both knowledge and on the phenomenon in question.
A simple likelihood function, a binomial distribution to describe a coin toss, for example, is immediately plausible because we assume that we know (i.e. we can observe) all the ways in which the observed data can be produced. Though we may not know whether a coin is forged and therefore be uncertain about the probability of obtaining heads, we know that the coin has two sides and can fall on either one of them. For the setting of the likelihood function to be a sensible operation in the more complex case at hand, we have to assume that the world can be reduced in such a way that we can approximate all possible ways in which the variables, i.e. their states, could be recombined in order to attain the observed data. In other words, we have to assume that something structurally akin to a coin, though infinitely more complex, lies at the cause of the phenomenon. In this sense, the likelihood function turns data into evidence for a hypothesis that relates to, in this case, a distribution of pollution shares. We cannot, for example, ask what decay is, how nutrient inputs behave once they come into contact with other nutrients, how the interrelationship of preconceived input sources, inputs and loads may change over time, with place, or due to any other variation. In this sense, setting the likelihood function is a technique that suggests the reducibility of the world according to a preconceived theory on variables in relation to the production of data. It allows people to create a kind of knowledge that can enable action without having to have an understanding of the ‘nature’ of the variables, their potential way of behaving given changes on factors unconsidered by the given model structure, and so on.
From this perspective, setting the likelihood function foregrounds a particular kind of knowledge and handles a particular kind of uncertainty–an uncertainty on and of numbers–which arguably provides a partial perspective on knowledge and the world, even if probability calculus suggests that all uncertainties have been dealt with because the probabilities over all possible states of a variable have to sum to one. Probabilities mesh well with the notion of expected value and the risk calculus of economics and engineering. The Bayesian approach, since it foregrounds a kind of uncertainty that can be translated into states within a set model structure assumed to produce another state, seems thus especially suited for being enlisted in these types of calculations.
Meanwhile, uncertainty reduction may seem of self-evident value. Yet, an interest in minimising uncertainty on states, and thereby regret, implies that knowledge informs and should inform action, and that certainty helps to choose the right action option to achieve desired states. This also suggests a particular understanding of the good. In Buddhist philosophy, for example, human suffering stems precisely from an interest in controlling outcomes114. From this point of view, there is no need to attain certainty on abstract parameters, their interrelationships and consequences. In order to attain a good life, people ought not to cling to any concrete state. Uncertainty reduction and quantification, in this sense, are embedded in some value-laden, perhaps ‘Western’, behaviourist notions: an outcome-focus, an implicit understanding of wellbeing as tied to the experience of desired states, and of people as intentional outcome seekers115.
Yet, this is not a universal assumption or affordance of Bayesian techniques such as setting a likelihood function in themselves but manifests when they become part of certain practices. According to science historian Bertsch McGrayne, Bayes’ own search for knowledge in a case of ignorance was motivated by a desire to determine whether one could infer a cause from observations, to solve the so-called ‘inverse probability problem’.116 So, Bayes rule enabled a knower to do something other than what it enables contemporary statisticians and modellers to do. It did not suggest that the good rests in achieving certain states and people need to successfully minimise regret to live well. Instead, updating a prior to a posterior distribution helped maintain a world in which people’s trust in the existence of hidden causes was important to live well.
$Pr(\theta| M,X)$ Defining the prior
The prior is the probability distribution over all uncertain quantities in a Bayesian model, here the model parameters $\theta$, before the data are being considered. It thus formalises the analyst’s uncertainty prior to the evidence at hand. When defining a prior, the analyst chooses its distributional form together with plausible ranges of parameter values. Priors are often defined separately for each uncertain quantity, which implicitly assumes these are independent in what really is a joint prior distribution. Hence, prior correlations between uncertain quantities require consideration, too. It is clear, however, that the influence of the prior on the posterior and thereby the inferential results diminish as the amount of data increases. The data are said to overwrite the prior via the likelihood function. It is also common today to assess the sensitivity of the results to different prior choices117 or factor in numerical considerations (e.g. regularising priors), even if this conflicts with Bayesian orthodoxy.
In the case at hand, the model had 91 parameters for each nutrient118. All were defined as independent uniform distributions over prescribed ranges, which is a so-called ‘uninformative’ choice. The ranges for the export coefficients except for industries and roads/tracks were based on the minima and maxima found in the literature on export coefficients in the UK, without weighing repeat citations higher because not all studies were considered independent. The ranges for industrial discharges were bounded by zero and the maximum permitted value as per the environmental licence. The range for roads/tracks, due the lack of information for the UK and a general absence of information of nutrient exports from roads and tracks worldwide, was based on studies for forest roads in Australia that were the only ones found at the time119. The ranges for the effectiveness of BMPs were taken from Newell Price et al120. The ranges for the river and reservoir/lake decay coefficients were established by trial and error.
Not all Bayesians agree with the equal probabilities assigned also to the extreme ends of a uniform distribution and with the step change to zero probability at its bounds. According to Bertsch McGrayne121, Bayes himself initially assumed equal probabilities due to his Christian beliefs and prevalent practices of awarding annuities. In the case at hand, the definition of the uniform prior enacted reliability, certainty, knowledge, research goals, and the methodologically permissible in ways that drew together and contributed to, again, partial perspectives and ‘real-world’ material consequences.
The choice of the uniform prior was entwined with the modeller’s personal experience of academic publishing conventions and their intuitions regarding the nature of the knowledge reported in papers. Several publications existed on the export coefficients in the UK context. They could have been used to form a more informative prior. Yet, the modeller did not consider them independent, believing that most of them merely reproduced previous studies without providing new evidence for the export coefficients. So, instead of giving more weight to results mentioned more often across the literature, they chose to give equal weight to each single result and all values in between. Other modellers may enact reliability differently by counting each published result towards the prior, for different reasons. In this sense, each practitioners’ different understandings of, for example, reliability or certainty may interact with a different choice regarding the shape of the prior distribution.
The shape of the prior distribution, meanwhile, matters. It has implications for the subsequent modelling process and the interpretation of data. A diffuse prior, as much as an informative prior, can adversely impact parameter estimates when dealing with small sample sizes122 and create numerical inefficiencies. By choosing the uniform prior, the modeller thus implicitly assumed that it was less risky to end up with a model that would take more iterations to approximate the parameter values than it was to end up with inferences that align more with the prior than with the likelihood. They could have made another choice, resulting in different consequences in terms of the time and energy needed to approximate the parameter values.
So, the definition of the prior enacts the ‘methodologically permissible’ in interaction with partial knowledge of the nature and the goals of research. In the case at hand, it was also situated within a particular ‘school’ of Bayesian modelling, a particular time and value orientation. Determining the priors for the decay coefficients iteratively would have not been permitted to an ‘orthodox’ Bayesian, who requires the prior to be set before incorporating the data via the likelihood and then to remain unchanged. Others, however, argue that adjusting priors or testing their sensitivities is permissible, because people in practice want and need to be efficient. From this point of view, a modelling process contributes to enacting the boundaries between the methodologically permissible and impermissible in relation to values–such as efficiency–that the modellers deem relevant to their working context.
Lastly, assembling prior evidence may serve to enact a version of knowledge that highlights appropriate form over relationships to place. This has consequences for which next research steps seem necessary and how the research process intervenes in the world. The prior had to translate information from studies across the UK to the particular place of the Tamar, with its unique climate, topography, soils, farming system etc. The prior/likelihood interplay was deemed to capture this translation well: studies across the UK provided bounds on what to expect in terms of nutrient exports in the Tamar (via the prior) while in-stream data from the Tamar (via the likelihood) was used to narrow those ranges by way of Bayesian inference. It was also deemed permissible to take data from a very different context to formulate priors for road runoff N and P exports. In this sense, working with data to build a model afforded finding input, i.e. something of the right form, rather than being specific to a place. When the stakeholders pointed to the necessity of including roads in the model, the process was already committed to the ECM. So, the modeller had to find data of the right form to determine a prior that fitted this model. The translatability of knowledge that the prior/likelihood interplay enabled had relevant ‘real-world’ consequences. Had the setup not succeeded in suggesting the translatability of knowledge of a certain form, the modeller might have had to choose a different model structure to solve this issue, or to set up local infrastructure, invest time and build relevant relations to obtain the necessary local data.
Implementing the equations
When performing Bayesian inference on a computer, the analyst must choose between using pre-existing packages or implementing algorithms from scratch. This choice matters as packages are maintained by developers, limiting options for likelihood functions, prior distributions, numerical methods, and model types. Packages may, in fact, require reformulations of research questions. Implementing algorithms from scratch offers more flexibility but increases the risk of coding errors and numerical inefficiencies. Thus, technical possibilities co-determine the Bayesian inference setup.
In the case at hand, the equations were implemented from scratch in the high-level programming language Matlab. Powerful open-source Bayesian inference engines such as STAN (Stan Development Team 2024) were not yet available, and the model had a degree of complexity that would be difficult to implement in such a software in any case. The modeller chose Matlab because they were familiar with the software. The model was implemented so that the uptake of 36 BMPs, 14 land uses and 4 kinds of livestock numbers could be simulated by stakeholders via a graphical interface.
By setting up a particular way to manipulate the model, the implementation of the model enacts socio-political-ethical order123. An interface to model scenarios made the model elements manipulable and opened the model to the involved stakeholders. This implementation, again, did not focus on specifying standards for harmful or non-harmful exports or the concrete, harmful outcomes of the nutrient exports, even though model outputs were assessed against existing status classes of the EU WFD. It also did not revolve around the cost of the sectors’ activities,124 to calculate an adequate tax to regulate externalities125, which is an approach common in modelling practices that target carbon pollution, for example126. Such models enact a world in which governments develop price control instruments to regulate consumption, to target productive activities whose costs outweigh their benefits127. In the case at hand, the implementation of the equation thus contributed to enacting socio-political-ethical order: It suggests that in the pursuit of a common good, a regional community of people implicitly agrees on the necessity to preserve some sectors and focuses on identifying some best practices. In this sense, the implementation enacted a world in which concrete people may together select strategies to pursue their collective good, discounting the idea of, for example, a general optimum that dictates policy.
$Pr(\theta|y,M,X)$ Sampling from the posterior
Once the model, the data, the likelihood and the prior are assembled, Bayes’ rule can be used to calculate the posterior. Since most real-world models have no analytical solution, the posterior is generally constructed by sampling from it. These samples are then summarised as in descriptive statistics to gain information about the posterior.
At this stage of the Bayesian workflow, most time typically goes into demonstrating that the sampler has ‘converged’, i.e. the theoretically correct posterior distribution has been found. Different samplers can make a difference, as demonstrated by Cooper et al128. Accuracy is as much an issue as efficiency, i.e. the computational time needed to represent the posterior precisely. These considerations interact in interesting ways with the choice of prior. So called ‘regularising’ priors, for example, concentrate the sampler on particular regions of the parameter space and thus mitigate against inefficient sampling. Uniform priors put the sampler at the mercy of the likelihood function and introduce step changes where the posterior probability drops to zero, which can again make the sampler inefficient.
In the case at hand, the prior parameter space (see above) was sampled randomly with 1 million realisations on a high-performance computing cluster. Pure random sampling is a simple yet inefficient choice of sampling. A more sophisticated sampler based on Monte Carlo Markov Chains that would work with a custom likelihood, e.g. the DREAM algorithm129, was not implemented due to time constraints.
If we consider science a way of being in the world, it is relevant to ask who can contribute to a particular kind of knowledge and which social relations and material consequences emerge along with it. Bayesian modelling in particular may contribute to enacting a world in which geographical distance and local embeddedness decrease in importance while technical skills rise and energy-intensity and infrastructural requirements cement existing inequalities.
In the case at hand, it was possible to choose an inefficient Monte Carlo sampler due to access to adequate infrastructure and hardware, and because the modeller did not assume they had to take into account any constraints or negative effects associated with high energy use. Abundant energy, however, is not simply a technical condition for the use of a method. It has participated in the evolution of that very method, is symptomatic of a particular position relating to resource access and power and creates material consequences in the world.
Bayesian modelling practices have evolved along with increased computational capacity and energy availability in some, mainly Western research centres. For the modeller, both were readily accessible. Their methodological choice was not limited by the consequences of energy and infrastructure use130, including in other places. Time, however, was constrained due to, among other things, academic conventions and context-specific demands for the project duration, pointing, again, to the embeddedness of any methodological choice in concrete socio-material contexts.
From this perspective, Bayesian ways of knowing may reorder relations. Geographically distant actors with relevant skills and infrastructure access may become more important for knowledge production, while local material interventions such as setting up and maintaining measuring devices decrease in importance. Bayesian modelling may thus contribute to enacting a world in which geographical distance diminishes, the importance of technical skills increases, and energy and infrastructure can compensate for a lack of time, possibly privileging richer research centres or increasing the need to develop computational capacities, acquire funds and intensify energy use.
Model checking and revision
Model checking and revision in the Bayesian workflow is more ambiguous than in frequentist statistics because uncertainties are carried forward to the model results and there are no residuals, misfits between the model and the data, as such that can be analysed. Metrics such as the coefficient of determination have a posterior distribution themselves. One could extract a single, most probable, realisation of model predictions and its deviation from the observations, but this would somewhat defeat the point of doing a coherent uncertainty analysis. Still, it can be checked whether the probabilistic properties of the model’s predictions are being realised in the relative frequencies of observations via so-called ‘posterior predictive checks’. Importantly, however, there is no built-in mechanism in Bayesian statistics for model rejection. This always requires considerations external to the Bayesian workflow.
When the modeller presented results of the export coefficient model to project stakeholders, they noticed for one of the subcatchments a discrepancy between the annual average phosphorus concentration they had measured at high resolution for one year and the concentration the model predicted as a 5-year average. In Figure 2, this is shown in the top-left graph in blue and red, respectively. Note that the model predictions come as a probability density function (pdf), i.e. with uncertainty.
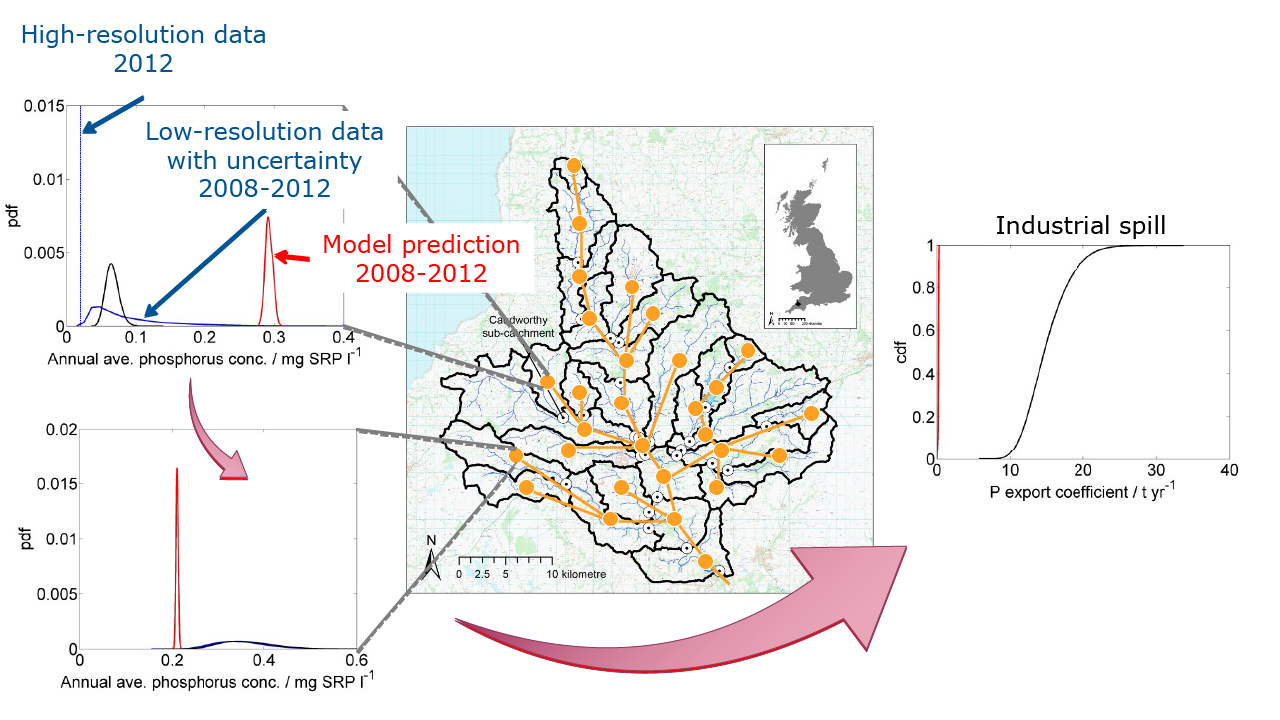
The two sets of data are not readily comparable due to the different temporal scales, but the discrepancy was enough to force a closer examination of the model. This investigation had not seemed pressing earlier because the model predictions were within the uncertainty range estimated for the model calibration data (also shown in blue in the top-left graph in Figure 2), albeit in the tails of that pdf. The predictions were still plausible given the data.
Upon investigation, it appeared that the model predictions were in the upper tails of the data pdfs for all subcatchments except one (bottom-left graph in Figure 2) where they were in the lower tails. After speaking to stakeholders and contacts in the catchment it transpired that there had been an industry spill during the simulation period in that subcatchment. The spill had released considerable amounts of phosphorus. This missing phosphorus input was partly compensated for during calibration by increasing the phosphorus contributions from agriculture (within prior ranges), which led to the overprediction elsewhere in the catchment (top-left graph in Figure 2).
Once a much higher input from the industry in question was allowed (bottom-right graph in Figure 2; black is the modified model, red is the original model), the model re-calibrated to yield a much more sensible picture. The predictions with the modified model were now more in the centre of the data pdf (top-left in Figure 3; black vs. blue pdf).
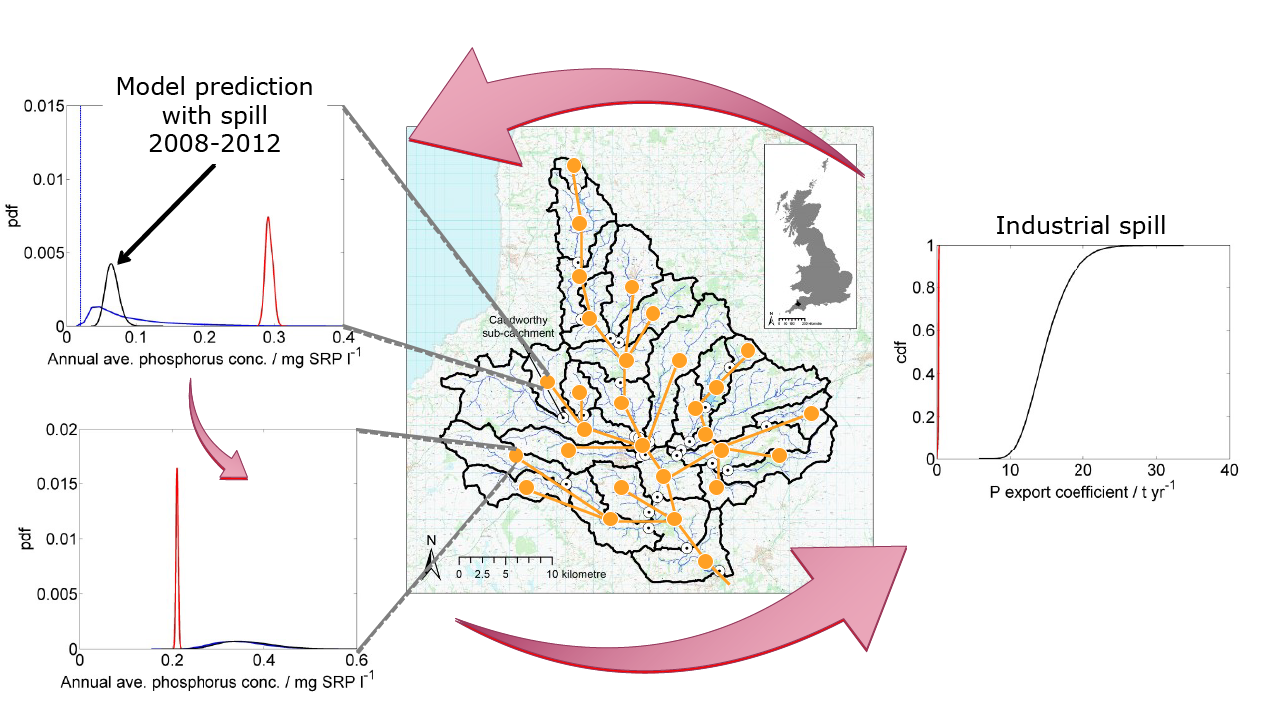
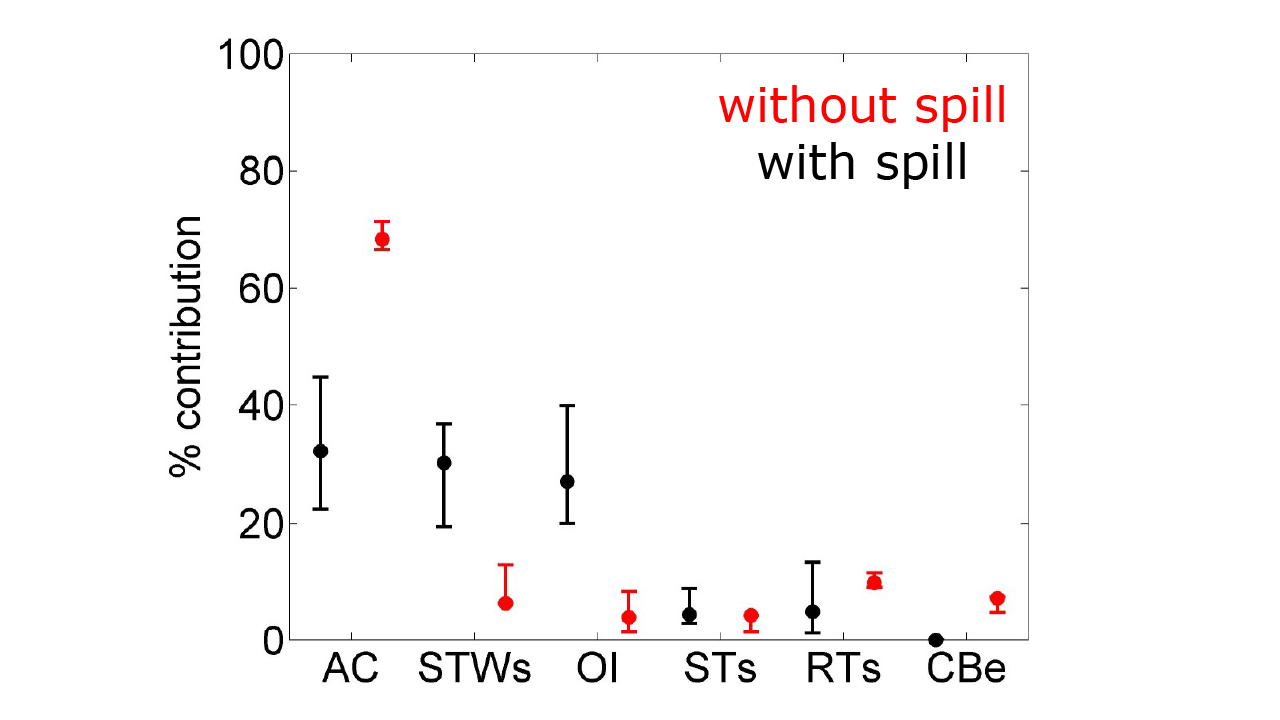
The re-calibration had political and economic implications (Figure 4): Not considering the industry spill (red symbols in Figure 4) would have resulted in putting all the blame for the phosphorus problem onto agriculture (about 70% contribution). Considering the spill led to a re-calibration of the model so that three sectors now shared the responsibility; agriculture, STWs and other industries each contributed about 30%. Very different discussions ensued on what to do about phosphorus pollution and who might have to pay for it.
Revising the model, much like the initial creation of the model, embodies a specific vision of the world and of responsibility.131 Yet, more importantly, the modeller’s approach to model checking and revision enacted a particular version of knowledge–one that points, from our perspective, to the potential for Bayesian (and any other) modelling practices to better account for partial perspectives and plural worldings.
In the case at hand, the particular social embeddedness of the project and lead researcher meant that onto-epistemic openings prevailed that made a different kind of solution for the model’s over- and underprediction both perceptible and available. Existing governance structures (both governmental and non-governmental) participated in the availability of subcatchment-level data, which was crucial in seeing the over- and underprediction. The researcher had built up social relations with local people that led to questioning the model’s internal resolution. A stakeholder, moreover, had access to another kind of data, and so on.
In other cases, however, the notion of Bayesian ‘updating’ may in everyday research practice afford a job-done mentality that indeed obscures all the ways in which the model is partial and impedes model checking and revision of this kind. Importantly, Bayesian inference schemes per se do not prompt the kind of investigation that led to the discovery of the spill. It required external impetus and a different kind of data–one that did not fit the model.132. The requirement of probabilities to sum to one in Bayesian modelling suggests the possibility to optimise, potentially obscuring that this optimisation pertains only to the distribution of shares of contributions from different sectors within certain limits set by the prior distribution.
Bayesian updating, in this sense, serves to learn only which belief is ‘better’ within certain limits, as the set of hypotheses is mutually exclusive and jointly exhaustive133. Compared to frequentist knowledge practices, Bayesian ones summarise hypotheses into new units. Bayesian modelling creates new units out of combinations of, in this case, inputs, approximating the best hypothesis on how these values combine in producing an outcome. This yields a necessary focus away from, in this case, whether we are accurate about a single source’s contribution to a single variable of interest. Bayesian knowledge is therefore partial knowledge in the sense that it gives privilege to seeing the best fit for the assumed combination of hypotheses. At the same time, Bayesian updating will not automatically consider other, previously unconsidered hypotheses, while the included hypotheses are contingent on an inextricable web of existing framings, (scientific) thought styles, foundational scientific concepts that privilege certain ways of seeing, as well as underlying ordering principles regarding the good, the social, the political and so on, as illustrated above. If researchers ‘just’ keep updating, the model will solve the issue, but the result still does not have to be faithful to what is going on.
So, the very practice of ‘updating’ itself may lead practitioners to disregard the partiality of their knowledge and engage in universalising practices. It may be the very appeal of Bayesian inference in formalising a coherent strategy of assessing hypotheses, which to some fits the scientific method extremely well, that prevents new hypotheses from emerging – because all hypotheses to be weighed against each other have to be already plausible a priori. Otherwise, one has to reset the Bayesian inference engine.
In this sense, Bayesian modelling practices can, as in the case at hand, co-evolve with other ways of knowing and become part of non-universalising kinds of relations. In a more conventional, detached scientific setting, however, they are likely to privilege internal solvability.
Concluding thoughts
In this article, we have presented a cursory investigation of how partial perspectives can be acknowledged at different points in Bayesian research, to increase the potential of the approach to produce strong134 scientific knowledge. We started by suggesting that existing arguments that focus on whether Bayesian approaches better reflect what knowledge is or ought to be treat knowledge as a stable referent and disregard the enactive capacities of knowledge practices. Following feminist and decolonial perspectives on science, we therefore examined, by using examples, what a ‘Bayesian’ way of knowing does in and to the world. We pointed out how research ‘doings’ in a Bayesian modelling process prefigured other ones, how Bayesian knowledge practices enacted aspects of the world–for example responsibility at a sector level and 5-year scale and pollution as nutrient load–and contributed to making real a limited number of action options such as, in the case at hand, regulating sector activities as opposed to intervening in global nutrient cycles or consumption patterns. We expounded that a Bayesian research process unfolds within a particular situation that draws together partial knowledges relating to, for example, administrative conventions for governing space, regulatory frameworks, technological capacities, infrastructural availabilities, scientific framings, foundational assumptions on science, collective action, the good, governance, and the nature of the world. This paper also exemplarily highlights some ways in which Bayesian knowledge production leaves material traces, and (re)configures (social) relations.
In summary, we argue that building certain model structures may highlight interventions that are desirable, thinkable, and needed according to certain enactments of the world. In the case at hand, model building aligned with an existing political and scientific problem framing, naturalised patterns of consumption, and privileged policy intervention at the regional and sector level, while granting farmers some agency by including land management practices. In data preparation, data categories and availability were embedded in existing administrative conventions for governing geographical space and conventional framings of pollution within hydrology. By making nutrients problematic, calculating nutrient ‘loads’ participated in enacting responsibility for pollution in terms of a uniformly attributable responsibility at the regional and sector level. This, in turn, hung together with limiting considerations to an agent-neutral, abstract good of people in the region, resulting in a partial perspective on pollution. In this concrete case, the possibility to create knowledge within the Bayesian framework enabled an attribution of responsibility characterised by a conflation of moral reasoning and accounting135. However, it is oblivious of, for example, histories, politics of place and meanings that render perceived sources as sources. It is likewise oblivious to how these histories, politics and meanings may impact ‘sectors’’ needs for and during transformation, concrete agents’ location within a broader enabling or constraining system, their intentions, inner attributes, needs for care or capacities to care, or their ‘response-ability’136. This is a partial perspective in many ways. Among other things, it suggests a fixed existence of pollution as a problem of loads per se, disconnected from concrete people and other organisms’ relations to nutrients that play a role in, for example, the materialisation of their ‘effects’ in different places.
Moreover, Bayesian inference requires defining the prior and the likelihood function, both of which also are entangled with and contribute to building partial knowledges. In the case at hand, setting a uniform prior, for example, enacted reliability in terms of independent publications of newly attained results–which also implies a certain perspective on knowledge. The setting of the likelihood function, a crucial step that enables Bayesian updating from the prior to the posterior, enacted a version of knowledge that is action-oriented, deemphasising, for example, knowledges that foreground the relevance, nature or meaning of the variables in question. By enabling uncertainty reduction on a type of uncertainty that can be expressed in numbers–uncertainty regarding the states of variables–it suggests that people are wilful outcome seekers whose ’good’ rests in minimising regret associated with achieving certain states.
Implementing the equations, sampling from the posterior and checking and revising the model, moreover, may also do things in the world that render the resulting knowledges partial ones, and simultaneously enact a version of knowledge itself by producing knowledge along with attendant notions of what ought to and can legitimately be done to attain it. In the case at hand, the implementation of the equations made a specific part of the model manipulable. Thus, it enacted a version of politics according to which concrete people may choose best practices to realise a common good, as opposed to, for example, a general optimum dictating policy. The inefficient sampler chosen in the case at hand points to the way in which Bayesian modelling may (re)order relations by enacting a world of diminished geographical distances, heightened energy-intensity and possibly inequality. Ultimately, the approach taken to checking the model suggests that Bayesian model checking by itself revolves around a partial perspective–one that solidifies the model structure, as opposed to foregrounding previously unconsidered hypotheses.
In thus exploring the multiple ways in which a Bayesian statistical model is based on partial knowledges and produces partial knowledges, we would like to suggest that, from a relational perspective, the Bayesian approach may not be so different from the frequentist one. Bayesian inference is impossible to disentangle from practices such as building model structures which are not specific to the Bayesian framework. Beyond this, the ‘Bayesian’ production of knowledge is no less universalising in itself than frequentist knowledge production. When we zoom in on how ‘Bayesian’ research is done in practice, the contingency and partiality of Bayesian knowledge and its active role in the world combined with technical operations that make it easy to forget about its contingency, partiality and role seem to be common to both the Bayesian and frequentist approach.
We believe that the recognition of Bayesian knowledge as situated knowledge, by contrast, demands continuous openness towards other ways of producing knowledge, to remain ‘faithful’137 to the contingency and complexity of any real-world issue. Due to the embeddedness of Bayesian knowledge practices in the project at hand, the modelling process emerged alongside a particular kind of stakeholder engagement process. This forced moments of openness that allowed alternative versions of the social, of politics, and of the good to enter the process, for example through the inclusion of land management practices in the ECM. Eventually, a stakeholder organisation’s access to a different kind of data made available a new way of solving the mismatch between predictions and data that was arguably more faithful to the issue at hand than the model’s initial solution.
In other cases, however, when Bayesian knowledge practices are differently embedded, the tools and resources that come into play during a Bayesian research project may reinforce a view of the world according to which all actions and artefacts of the world can be treated as fact. For some practitioners, the Bayesian approach might sensitise to the notion that knowledge is conceived against a particular context, that evidence is relative to a hypothesis, to the likelihood function, and to input data. This sensitivity, however, may in practice fit with a postpositivist position that objectifies knowledge, albeit maybe a contextual one. Researchers who use the Bayesian machinery may treat knowledge as partial in so far as they incorporate context and belief into their notion of knowledge, or consider evidence to be relative to the model, the data, and the likelihood function. They may well, however, ‘[attach] the feeling of the absolute to the partial truth’138 by adhering to the belief that Bayesian updating is the way to approximate the hypothesis that is ‘best’ in a conventional epistemological sense.
From a relational point of view, even the epistemologically ‘best’ model that Bayesian updating may yield is irreducibly partial. Beyond the particular kind of relativity that Bayesian practitioners may be aware of, it sustains various kinds of relations at various levels, which we exemplified in this paper. The model is thus made best only by a situated conglomeration of intersecting, contingent and partial knowledges. Ultimately, having a result—the best model of source apportionment in the catchment in our case—may obscure that all of these could be otherwise, and that modelling has enactive139 capacities.
Our resulting plea for maintaining constructive interdisciplinary inquiry and openness to ensure that Bayesian approaches to knowledge are done responsibly aligns with much current work. In the recent past, many researchers have pointed out the value of preserving openness140 and considering the concrete relations and places that situate a research project to construct methods that increase accountability for how research participates in the world141. Fine142, for example, suggests creating ‘collaborative contexts’ to ask ‘why, how, when, with whom and who is made vulnerable by the research’143, to engage in collective self-reflection and ongoing conversation about a research project’s lens, framing of the problem, data, ‘and what we can’t/don’t see’144. Bieler et al. promote ‘distributed reflexivity’145, Tuck and McKenzie have coined the term ‘relational validity’146. Schmidt147 suggests constructing rich contextual social science accounts about science to unearth styles of ethical reasoning that have been used to legitimise ways of knowing and managing water in particular. Liboiron148 describe practices of ‘community peer review’ to develop methods that align with the perspectives and ways of being in the world of relevant communities. With regard to modelling in particular, Klein et al.149 advise directing attention to a modelling project’s social embeddedness and building heterogeneous social collectives that produce knowledge ‘agonistically’, iteratively inquiring into research practices in a non-conclusive kind of way.
Acknowledgements / Funding Information
Anja Klein: This work was supported by the German Research Foundation (DFG) under Grant number 497511081.
References
Amelang, Katrin, and Susanne Bauer. ‘Following the Algorithm: How Epidemiological Risk-Scores Do Accountability’. Social Studies of Science 49, no. 4 (August 2019): 476–502. https://doi.org/10.1177/0306312719862049.
Barad, Karen. Meeting the Universe Halfway: Quantum Physics and the Entanglement of Matter and Meaning. Duke University Press, 2006. https://doi.org/10.1215/9780822388128.
Bauer, Susanne. ‘Seeing Like a Model Fish: How Digital Extractions Mediate Metabolic Relations’. Science, Technology, & Human Values 49, no. 3 (May 2024): 524–54. https://doi.org/10.1177/01622439241236520.
Bäumler, Jelena. ‘Rise and Shine: The No Harm Principle’s Increasing Relevance for the Global Community’. In The Global Community Yearbook of International Law and Jurisprudence 2017, edited by Giuliana Ziccardi Capaldo, 1st ed., 149–74. Oxford University Press, 2018. https://doi.org/10.1093/oso/9780190923846.003.0007.
Baumol, William J. ‘On Taxation and the Control of Externalities’. The American Economic Review 62, no. 3 (1972): 307–22.
Berger, James. ‘The Case for Objective Bayesian Analysis’. Bayesian Analysis 1, no. 3 (1 September 2006). https://doi.org/10.1214/06-BA115.
Berger, James O., Elías Moreno, Luis Raul Pericchi, M. Jesús Bayarri, José M. Bernardo, Juan A. Cano, Julián De La Horra, et al. ‘An Overview of Robust Bayesian Analysis’. Test 3, no. 1 (June 1994): 5–124. https://doi.org/10.1007/BF02562676.
Bieler, Patrick, Milena D. Bister, Janine Hauer, Martina Klausner, Jörg Niewöhner, Christine Schmid, and Sebastian Von Peter. ‘Distributing Reflexivity through Co-Laborative Ethnography’. Journal of Contemporary Ethnography 50, no. 1 (February 2021): 77–98. https://doi.org/10.1177/0891241620968271.
Bierhoff, Hans-Werner, and Elke Rohmann. ‘Conditions for Establishing a System of Fairness: Comment on Brosnan (2006)’. Social Justice Research 19, no. 2 (June 2006): 194–200. https://doi.org/10.1007/s11211-006-0001-0.
Blouin, Gabriel G. ‘Data Performativity and Health: The Politics of Health Data Practices in Europe’. Science, Technology, & Human Values 45, no. 2 (March 2020): 317–41. https://doi.org/10.1177/0162243919882083.
Bouleau, Gabrielle. ‘The Co-Production of Science and Waterscapes: The Case of the Seine and the Rhône Rivers, France’. Geoforum 57 (November 2014): 248–57. https://doi.org/10.1016/j.geoforum.2013.01.009.
Bovens, Luc, and Stephan Hartmann. Bayesian Epistemology. Edited by Stephan Hartmann. Oxford: Oxford University Press, 2003.
Bunge, Mario. ‘Bayesianism: Science or Pseudoscience?’ International Review of Victimology 15, no. 2 (September 2008): 165–78. https://doi.org/10.1177/026975800801500206.
Cadena, Marisol de la. ‘Research’. Personal Website. Marisol de La Cadena (blog). Accessed 18 December 2024. https://www.marisoldelacadena.com/bio.
Cakici, Baki, Evelyn Ruppert, and Stephan Scheel. ‘Peopling Europe through Data Practices: Introduction to the Special Issue’. Science, Technology, & Human Values 45, no. 2 (March 2020): 199–211. https://doi.org/10.1177/0162243919897822.
Clark, Andy. ‘Busting Out: Predictive Brains, Embodied Minds, and the Puzzle of the Evidentiary Veil’. Noûs 51, no. 4 (December 2017): 727–53. https://doi.org/10.1111/nous.12140.
———. The Experience Machine: How Our Minds Predict and Shape Reality. Dublin: Penguin books, 2024.
Coase theorem. Oxford Reference. https://www.oxfordreference.com/view/10.1093/oi/authority.2011080309562015, Accessed 15 Sep 2024.
Cooper, Richard J., Tobias Krueger, Kevin M. Hiscock, and Barry G. Rawlins. ‘Sensitivity of Fluvial Sediment Source Apportionment to Mixing Model Assumptions: A Bayesian Model Comparison’. Water Resources Research 50, no. 11 (November 2014): 9031–47. https://doi.org/10.1002/2014WR016194.
De La Cadena, Marisol. ‘An Invitation to Live Together’. Environmental Humanities 11, no. 2 (1 November 2019): 477–84. https://doi.org/10.1215/22011919-7754589.
———. ‘An Invitation to Live Together’. Environmental Humanities 11, no. 2 (1 November 2019): 477–84. https://doi.org/10.1215/22011919-7754589.
———. Earth Beings: Ecologies of Practice across Andean Worlds. Edited by Robert J. Foster and Daniel R. Reichman. Duke University Press, 2015. https://doi.org/10.1215/9780822375265.
Deleuze, Gilles. Difference and Repetition. 2nd ed. Bloomsbury Revelations Ser. London: Bloomsbury Publishing Plc, 2014.
Deleuze, Gilles, and Félix Guattari. What Is Philosophy? Repr. London: Verso, 2015.
Dennis, Brian. ‘Discussion: Should Ecologists Become Bayesians?’ Ecological Applications 6, no. 4 (November 1996): 1095–1103. https://doi.org/10.2307/2269594.
Douglas, Mary. Purity and Danger; an Analysis of Concepts of Pollution and Taboo. London: Routledge & Paul, 1966.
Edenhofer, Ottmar, Michael Jakob, Felix Creutzig, Christian Flachsland, Sabine Fuss, Martin Kowarsch, Kai Lessmann, Linus Mattauch, Jan Siegmeier, and Jan Christoph Steckel. ‘Closing the Emission Price Gap’. Global Environmental Change 31 (March 2015): 132–43. https://doi.org/10.1016/j.gloenvcha.2015.01.003.
Eisenack, Klaus, O Edenhofer, and M Kalkuhl. ‘Efficiency and Distribution Effects of Resource and Energy Taxes for Climate Protection’. IOP Conference Series: Earth and Environmental Science 6, no. 10 (1 February 2009): 102014. https://doi.org/10.1088/1755-1307/6/10/102014.
Feinberg, Joel. ‘Environmental Pollution & the Threshold of Harm’. The Hastings Center Report 14, no. 3 (June 1984): 27. https://doi.org/10.2307/3561186.
Fine, Michelle. ‘Bearing Witness: Methods for Researching Oppression and Resistance—A Textbook for Critical Research’. Social Justice Research 19, no. 1 (1 March 2006): 83–108. https://doi.org/10.1007/s11211-006-0001-0.
Fleck, Ludwik. Entstehung und Entwicklung einer wissenschaftlichen Tatsache: Einführung in die Lehre vom Denkstil und Denkkollektiv. Edited by Lothar Schäfer and Thomas Schnelle. 13. Auflage. Suhrkamp-Taschenbuch Wissenschaft 312. Frankfurt am Main: Suhrkamp, 2021.
Forsyth, A.R., K.A. Bubb, and M.E. Cox. ‘Runoff, Sediment Loss and Water Quality from Forest Roads in a Southeast Queensland Coastal Plain Pinus Plantation’. Forest Ecology and Management 221, no. 1–3 (January 2006): 194–206. https://doi.org/10.1016/j.foreco.2005.09.018.
Franks, Max, Friedemann Gruner, Matthias Kalkuhl, Kai Lessmann, and Ottmar Edenhofer. ‘Pigou’s Advice and Sisyphus’ Warning: Carbon Pricing Withnon-Permanent Carbon Dioxide Removal’, 2024. https://doi.org/10.2139/ssrn.4828800.
Gelman, Andrew. ‘Induction and Deduction in Bayesian Data Analysis’, 2011. https://doi.org/10.22029/JLUPUB-374.
Gelman, Andrew, and Cosma Rohilla Shalizi. ‘Philosophy and the Practice of Bayesian Statistics’. 66, no. 1 (February 2013): 8–38. https://doi.org/10.1111/j.2044-8317.2011.02037.x.
Gelman, Andrew, and Yuling Yao. ‘Holes in Bayesian Statistics *’. Journal of Physics G: Nuclear and Particle Physics 48, no. 1 (1 January 2021): 014002. https://doi.org/10.1088/1361-6471/abc3a5.
Ghahramani, Zoubin. ‘Probabilistic Machine Learning and Artificial Intelligence’. Nature 521, no. 7553 (28 May 2015): 452–59. https://doi.org/10.1038/nature14541.
Green, Peter J. ‘Reversible Jump Markov Chain Monte Carlo Computation and Bayesian Model Determination’. Biometrika 82, no. 4 (1995): 711–32. https://doi.org/10.1093/biomet/82.4.711.
Grommé, Francisca, and Evelyn Ruppert. ‘Population Geometries of Europe: The Topologies of Data Cubes and Grids’. Science, Technology, & Human Values 45, no. 2 (March 2020): 235–61. https://doi.org/10.1177/0162243919835302.
Hacking, Ian. An Introduction to Probability and Inductive Logic. Cambridge University Press, 2001.
———. The Emergence of Probability: A Philosophical Study of Early Ideas about Probability, Induction and Statistical Inference. 2nd ed. Cambridge University Press, 2006. https://doi.org/10.1017/CBO9780511817557.
———. The Taming of Chance. 1st ed. Cambridge University Press, 1990. https://doi.org/10.1017/CBO9780511819766.
Haraway, Donna. ‘Situated Knowledges: The Science Question in Feminism and the Privilege of Partial Perspective’. Feminist Studies 14, no. 3 (1988): 575. https://doi.org/10.2307/3178066.
Hesse, Mary B. ‘Models in Physics’. The British Journal for the Philosophy of Science 4, no. 15 (1953): 198–214.
Isaac, Susan. ‘“Phossy Jaw” and the Matchgirls: A Nineteenth-Century Industrial Disease’. Royal College of Surgeons of England (blog), 28 September 2018. https://www.rcseng.ac.uk/library-and-publications/library/blog/phossy-jaw-and-the-matchgirls/.
Johnes, P.J. ‘Evaluation and Management of the Impact of Land Use Change on the Nitrogen and Phosphorus Load Delivered to Surface Waters: The Export Coefficient Modelling Approach’. Journal of Hydrology 183, no. 3–4 (September 1996): 323–49. https://doi.org/10.1016/0022-1694(95)02951-6.
Jung, Hoseung. ‘Uncertainty in Water Quality Monitoring, Data Analysis and Modelling – and a Buddhist Contemplation on Its Suffering’. Humboldt-Universität zu Berlin, 10 October 2023. https://doi.org/10.18452/27074.
Kail, P. J. E. Berkeley’s A Treatise Concerning the Principles of Human Knowledge: An Introduction. 1st ed. Cambridge University Press, 2014. https://doi.org/10.1017/CBO9780511736506.
Klein, Anja, Krystin Unverzagt, Rossella Alba, Jonathan F. Donges, Tilman Hertz, Tobias Krueger, Emilie Lindkvist, et al. ‘From Situated Knowledges to Situated Modelling: A Relational Framework for Simulation Modelling’. Ecosystems and People 20, no. 1 (31 December 2024): 2361706. https://doi.org/10.1080/26395916.2024.2361706.
Krueger, Tobias. ‘Bayesian Inference of Uncertainty in Freshwater Quality Caused by Low-Resolution Monitoring’. Water Research 115 (May 2017): 138–48. https://doi.org/10.1016/j.watres.2017.02.061.
Krueger, Tobias, and Rossella Alba. ‘Ontological and Epistemological Commitments in Interdisciplinary Water Research: Uncertainty as an Entry Point for Reflexion’. Frontiers in Water 4 (17 November 2022): 1038322. https://doi.org/10.3389/frwa.2022.1038322.
Kruschke, John K. ‘Posterior Predictive Checks Can and Should Be Bayesian: Comment on Gelman and Shalizi, “Philosophy and the Practice of Bayesian Statistics”’. British Journal of Mathematical and Statistical Psychology 66, no. 1 (February 2013): 45–56. https://doi.org/10.1111/j.2044-8317.2012.02063.x.
Lane, Stuart N., Chris J. Brookes, A. Louise Heathwaite, and Sim Reaney. ‘Surveillant Science: Challenges for the Management of Rural Environments Emerging from the New Generation Diffuse Pollution Models’. Journal of Agricultural Economics 57, no. 2 (July 2006): 239–57. https://doi.org/10.1111/j.1477-9552.2006.00050.x.
Latour, Bruno. We Have Never Been Modern. Harvard university press, 2012.
Liboiron, Max. Pollution Is Colonialism. Duke University Press, 2021. https://doi.org/10.1215/9781478021445.
Linton, Jamie, and Tobias Krueger. ‘The Ontological Fallacy of the Water Framework Directive: Implications and Alternatives’. Water Alternatives 13, no. 3 (2020): 513.
Lynch, Scott M., and Bryce Bartlett. ‘Bayesian Statistics in Sociology: Past, Present, and Future’. Annual Review of Sociology 45, no. 1 (30 July 2019): 47–68. https://doi.org/10.1146/annurev-soc-073018-022457.
Mackenzie, Adrian. ‘The Production of Prediction: What Does Machine Learning Want?’ European Journal of Cultural Studies 18, no. 4–5 (August 2015): 429–45. https://doi.org/10.1177/1367549415577384.
McGrayne, Sharon Bertsch. The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted down Russian Submarines, & Emerged Triumphant from Two Centuries of Controversy. New Haven: Yale university press, 2011.
McMahon, Melissa. ‘Difference, Repetition’. In Gilles Deleuze, edited by Charles J. Stivale, 42–52. McGill-Queen’s University Press, 2005. https://doi.org/10.1515/9780773584884-007.
Meadows, Donella. ‘Places to Intervene in a System’. Whole Earth 91, no. 1 (1997): 78–84.
Medema, Steven G. ‘“Exceptional and Unimportant”?’ History of Political Economy 52, no. 1 (24 October 2019): 135–70. https://doi.org/10.1215/00182702-8009583.
Mocigemba, Dennis. ‘Sustainable Computing’. Poiesis & Praxis 4, no. 3 (September 2006): 163–84. https://doi.org/10.1007/s10202-005-0018-8.
Mol, Annemarie. The Body Multiple: Ontology in Medical Practice. Duke University Press, 2002. https://doi.org/10.1215/9780822384151.
Morey, Richard D., Jan‐Willem Romeijn, and Jeffrey N. Rouder. ‘The Humble Bayesian: Model Checking from a Fully Bayesian Perspective’. British Journal of Mathematical and Statistical Psychology 66, no. 1 (February 2013): 68–75. https://doi.org/10.1111/j.2044-8317.2012.02067.x.
Morey, Richard D., Jan-Willem Romeijn, and Jeffrey N. Rouder. ‘The Philosophy of Bayes Factors and the Quantification of Statistical Evidence’. Journal of Mathematical Psychology 72 (June 2016): 6–18. https://doi.org/10.1016/j.jmp.2015.11.001.
Murdoch, Iris. Metaphysics as a Guide to Morals New York, New York, U.S.A.: Allen Lane, The Penguin Press, 1993.
———. The Sovereignty of Good. Routledge Classics. London: Routledge, 2006.
Newell Price, J.P., D. Harris, M. Taylor, J.R. Williams, S.G. Anthony, D. Duethmann, R.D. Gooday, et al. ‘An Inventory of Mitigation Methods and Guide to Their Effects on Diffuse Water Pollution, Greenhouse Gas Emissions and Ammonia Emissions from Agriculture’. Devon: Rothamsted Research, North Wyke, December 2011. https://repository.rothamsted.ac.uk/download/942687eab7ec4b83751c7e241d62f0fa8472d72adcd25a149bb891b7c30d55d0/1595300/MitigationMethods-UserGuideDecember2011FINAL.pdf.
Nimbe, Peter, Benjamin Asubam Weyori, and Adebayo Felix Adekoya. ‘Models in Quantum Computing: A Systematic Review’. Quantum Information Processing 20, no. 2 (February 2021): 80. https://doi.org/10.1007/s11128-021-03021-3.
Nott, David J., Lucy Marshall, and Jason Brown. ‘Generalized Likelihood Uncertainty Estimation (GLUE) and Approximate Bayesian Computation: What’s the Connection?’ Water Resources Research 48, no. 12 (December 2012): 2011WR011128. https://doi.org/10.1029/2011WR011128.
O’Brien, Mary. Making Better Environmental Decisions: An Alternative to Risk Assessment. Cambridge: MIT Press, 2000.
Ostrom, Elinor. ‘Collective Action and the Evolution of Social Norms’. The Journal of Economic Perspectives 14, no. 3 (2000): 137–58.
Parker, Wendy S. ‘Climate Modeling’. In The Routledge Companion to Environmental Ethics, by Benjamin Hale, Andrew Light, and Lydia Lawhon, 245–55, 1st ed. New York: Routledge, 2022. https://doi.org/10.4324/9781315768090-26.
Pigou, Arthur Cecil. The Economics of Welfare. 1st ed. London: Macmillan, 1912.
Poovey, Mary. A History of the Modern Fact: Problems of Knowledge in the Sciences of Wealth and Society. 5. print. Chicago, Ill.: University of Chicago Press, 2007.
Räsänen, Minna, and James M. Nyce. ‘The Raw Is Cooked: Data in Intelligence Practice’. Science, Technology, & Human Values 38, no. 5 (September 2013): 655–77. https://doi.org/10.1177/0162243913480049.
Ribes, David. ‘STS, Meet Data Science, Once Again’. Science, Technology, & Human Values 44, no. 3 (May 2019): 514–39. https://doi.org/10.1177/0162243918798899.
Robertson, Dale M., David A. Saad, Glenn A. Benoy, Ivana Vouk, Gregory E. Schwarz, and Michael T. Laitta. ‘Phosphorus and Nitrogen Transport in the Binational Great Lakes Basin Estimated Using SPARROW Watershed Models’. JAWRA Journal of the American Water Resources Association 55, no. 6 (December 2019): 1401–24. https://doi.org/10.1111/1752-1688.12792.
Roffe, Jon, and Gilles Deleuze. The Works of Gilles Deleuze. I, 1953-1969. Melbourne: Re.press, 2020.
Schmidt, Jeremy J. ‘Water Quality and Availability’. In The Routledge Companion to Environmental Ethics, by Benjamin Hale, Andrew Light, and Lydia Lawhon, 157–67, 1st ed. New York: Routledge, 2022. https://doi.org/10.4324/9781315768090-18.
Schoot, Rens van de, Sarah Depaoli, Ruth King, Bianca Kramer, Kaspar Märtens, Mahlet G. Tadesse, Marina Vannucci, et al. ‘Bayesian Statistics and Modelling’. Nature Reviews Methods Primers 1, no. 1 (14 January 2021): 1–26. https://doi.org/10.1038/s43586-020-00001-2.
Schuurman, Nadine, and Geraldine Pratt. ‘Care of the Subject: Feminism and Critiques of GIS’. Gender, Place & Culture 9, no. 3 (September 2002): 291–99. https://doi.org/10.1080/0966369022000003905.
Sharpley, A.N., and A.D. Halvorson. ‘The Management of Soil Phosphorus Availability and Its Impact on Surface Water Quality’. In Soil Processes and Water Quality, by B.A. Stewart, 7–90. edited by R. Lal and B. A. Stewart, 1st ed. CRC Press, 1994. https://doi.org/10.1201/9781003070184-2.
Sheridan, Gary J., and Philip J. Noske. ‘Catchment‐scale Contribution of Forest Roads to Stream Exports of Sediment, Phosphorus and Nitrogen’. Hydrological Processes 21, no. 23 (November 2007): 3107–22. https://doi.org/10.1002/hyp.6531.
Smith, Laurence, Kevin Hiscock, Keith Porter, Tobias Krueger, and David Benson. ‘Getting Informed: Tools and Approaches for Assessment, Planning and Management’. In Catchment and River Basin Management: Integrating Science and Governance, 1st ed., 17. London: Routledge, 2015.
Spångberg, J., P. Tidåker, and H. Jönsson. ‘Environmental Impact of Recycling Nutrients in Human Excreta to Agriculture Compared with Enhanced Wastewater Treatment’. Science of The Total Environment 493 (September 2014): 209–19. https://doi.org/10.1016/j.scitotenv.2014.05.123.
Spiegelhalter, David. ‘Introducing The Art of Statistics: How to Learn from Data’. Numeracy 13, no. 1 (January 2020). https://doi.org/10.5038/1936-4660.13.1.7.
Sprenger, Jan, and Stephan Hartmann. Bayesian Philosophy of Science: Variations on a Theme by the Reverend Thomas Bayes. First edition. Oxford: Oxford University Press, 2019.
Star, Susan Leigh. ‘Introduction: The Sociology of Science and Technology’. Social Problems 35, no. 3 (June 1988): 197–205. https://doi.org/10.2307/800618.
Strathern, Marilyn, ed. Audit Cultures: Anthropological Studies in Accountability, Ethics and the Academy. 1. publ. European Association of Social Anthropologists. London: Routledge, 2000.
Sunnåker, Mikael, Alberto Giovanni Busetto, Elina Numminen, Jukka Corander, Matthieu Foll, and Christophe Dessimoz. ‘Approximate Bayesian Computation’. Edited by Shoshana Wodak. PLoS Computational Biology 9, no. 1 (10 January 2013): e1002803. https://doi.org/10.1371/journal.pcbi.1002803.
Tsing, Anna Lowenhaupt. The Mushroom at the End of the World: On the Possibility of Life in Capitalist Ruins. New paperback printing. Princeton Oxford: Princeton University Press, 2021.
Tuck, Eve, and Marcia McKenzie. ‘Relational Validity and the “Where” of Inquiry: Place and Land in Qualitative Research’. Qualitative Inquiry 21, no. 7 (September 2015): 633–38. https://doi.org/10.1177/1077800414563809.
Vrugt, Jasper A. ‘Markov Chain Monte Carlo Simulation Using the DREAM Software Package: Theory, Concepts, and MATLAB Implementation’. Environmental Modelling & Software 75 (January 2016): 273–316. https://doi.org/10.1016/j.envsoft.2015.08.013.
Walsh, Michael, Gerhard Schenk, and Susanne Schmidt. ‘Realising the Circular Phosphorus Economy Delivers for Sustainable Development Goals’. Npj Sustainable Agriculture 1, no. 1 (4 October 2023): 1–15. https://doi.org/10.1038/s44264-023-00002-0.
Wetzel, Robert G. ‘THE PHOSPHORUS CYCLE’. In Limnology, 239–88. Elsevier, 2001. https://doi.org/10.1016/B978-0-08-057439-4.50017-4.
White, Natasha. ‘Toxic Shadow: Phosphate Miners in Morocco Fear They Pay a High Price’. The Guardian, 16 December 2015, sec. Global development. https://www.theguardian.com/global-development/2015/dec/16/toxic-shadow-phosphate-miners-morocco-fear-they-pay-high-price.
Williams, James. ‘Difference and Repetition’. In The Cambridge Companion to Deleuze, edited by Daniel W. Smith and Henry Somers-Hall, 1st ed., 33–54. Cambridge University Press, 2012. https://doi.org/10.1017/CCO9780511753657.003.
———. Gilles Deleuze’s Difference and Repetition: A Critical Introduction and Guide. Critical Introductions and Guides CIG. Edinburgh: Edinburgh University Press, 2013. https://doi.org/10.1515/9780748668946.
Notes
- Rens van de Schoot et al., ‘Bayesian Statistics and Modelling’, Nature Reviews Methods Primers 1, no. 1 (14 January 2021): 1–26, https://doi.org/10.1038/s43586-020-00001-2. ↩
- Sharon Bertsch McGrayne, The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted down Russian Submarines, & Emerged Triumphant from Two Centuries of Controversy (New Haven: Yale university press, 2011), 34–58; 64. ↩
- Brian Dennis, ‘Discussion: Should Ecologists Become Bayesians?’, Ecological Applications 6, no. 4 (November 1996): 1095–1103, https://doi.org/10.2307/2269594. ↩
- James Berger, ‘The Case for Objective Bayesian Analysis’, Bayesian Analysis 1, no. 3 (1 September 2006), https://doi.org/10.1214/06-BA115, 5 ↩
- Mario Bunge, ‘Bayesianism: Science or Pseudoscience?’, International Review of Victimology 15, no. 2 (September 2008): 165–78, https://doi.org/10.1177/026975800801500206 ↩
- E.g. Zoubin Ghahramani, ‘Probabilistic Machine Learning and Artificial Intelligence’, Nature 521, no. 7553 (28 May 2015): 452–59, https://doi.org/10.1038/nature14541. ↩
- Peter Nimbe, Benjamin Asubam Weyori, and Adebayo Felix Adekoya, ‘Models in Quantum Computing: A Systematic Review’, Quantum Information Processing 20, no. 2 (February 2021): 80, https://doi.org/10.1007/s11128-021-03021-3. ↩
- Jan Sprenger and Stephan Hartmann, Bayesian Philosophy of Science: Variations on a Theme by the Reverend Thomas Bayes, First edition (Oxford: Oxford University Press, 2019). ↩
- Sprenger and Hartmann, 288–89. ↩
- Richard D. Morey, Jan-Willem Romeijn, and Jeffrey N. Rouder, ‘The Philosophy of Bayes Factors and the Quantification of Statistical Evidence’, Journal of Mathematical Psychology 72 (June 2016): 6–18, https://doi.org/10.1016/j.jmp.2015.11.001. ↩
- Sprenger and Hartmann, Bayesian Philosophy of Science, 300ff. ↩
- Morey, Romeijn, and Rouder, ‘The Philosophy of Bayes Factors and the Quantification of Statistical Evidence ↩
- Jan Sprenger, ‘The objectivity of Subjective Bayesianism’. European Journal for Philosophy of Science 8, 539–558 (2018). https://doi.org/10.1007/s13194-018-0200-1. ↩
- Luc Bovens and Stephan Hartmann, Bayesian Epistemology, ed. Stephan Hartmann (Oxford: Oxford University Press, 2003) ↩
- Reviewed by Andrew Gelman and Cosma Rohilla Shalizi, ‘Philosophy and the Practice of Bayesian Statistics’, British Journal of Mathematical and Statistical Psychology 66, no. 1 (February 2013): 9, https://doi.org/10.1111/j.2044-8317.2011.02037.x. The authors themselves prefer a hypothetico-deductive interpretation of Bayesian inference. ↩
- Scott M. Lynch and Bryce Bartlett, ‘Bayesian Statistics in Sociology: Past, Present, and Future’, Annual Review of Sociology 45, no. 1 (30 July 2019): 4, https://doi.org/10.1146/annurev-soc-073018-022457. ↩
- Andy Clark, The Experience Machine: How Our Minds Predict and Shape Reality (Dublin: Penguin books, 2024); Andrew Gelman and Yuling Yao, ‘Holes in Bayesian Statistics *’, Journal of Physics G: Nuclear and Particle Physics 48, no. 1 (1 January 2021): 11, https://doi.org/10.1088/1361-6471/abc3a5.; Andy Clark. ‘Busting Out: Predictive Brains, Embodied Minds, and the Puzzle of the Evidentiary Veil’. Noûs 51, No. 4 (December 2017): 727–53. https://doi.org/10.1111/nous.12140. ↩
- E.g. Morey, Romeijn, and Rouder, ‘The Philosophy of Bayes Factors and the Quantification of Statistical Evidence’. ↩
- Annemarie Mol, The Body Multiple: Ontology in Medical Practice (Duke University Press, 2002), https://doi.org/10.1215/9780822384151, 158. ↩
- Max Liboiron, Pollution Is Colonialism (Duke University Press, 2021), https://doi.org/10.1215/9781478021445, 37. ↩
- Liboiron, Pollution Is Colonialism. ↩
- Donna Haraway, ‘Situated Knowledges: The Science Question in Feminism and the Privilege of Partial Perspective’, Feminist Studies 14, no. 3 (1988): 575, https://doi.org/10.2307/3178066, 585. ↩
- Marisol de la Cadena, Earth Beings: Ecologies of Practice across Andean Worlds, ed. Robert J. Foster and Daniel R. Reichman (Duke University Press, 2015), https://doi.org/10.1215/9780822375265.; Marisol de la Cadena, ‘An Invitation to Live Together’. Environmental Humanities 11, no.2 (November 2019): 477–84. https://doi.org/10.1215/22011919-7754589. ↩
- Onto-epistemic openings are moments that provide insight into the possibility of plural worldings–practices that give meaning to, produce knowledge on and organise the world. They can arise from conceptual discrepancies in social interaction or be actively fostered through, for example, setting up ‘negativities’ of common-sense categories (De La Cadena, Earth Beings, 135; Marisol de la Cadena, ‘Research’, Personal Website, Marisol de La Cadena (blog), accessed 18 December 2024, https://www.marisoldelacadena.com/bio. ↩
- Mol, The Body Multiple. ↩
- Karen Barad, Meeting the Universe Halfway: Quantum Physics and the Entanglement of Matter and Meaning (Duke University Press, 2006), https://doi.org/10.1215/9780822388128. ↩
- According to Barad, ‘knowing is a material practice of engagement as part of the world in its differential becoming’ (Barad, 89). Ontology, epistemology and ethics are inseparable according to this view because the material practice of knowing creates ‘differences that matter’ (Barad, 381). ↩
- Haraway’s contribution, for example, enables an inquiry into the contingency, partiality and performativity of subject positions and ‘active’ knowledges (Haraway, ‘Situated Knowledges’). Barad highlights agencies, composed of humans, methods, instruments and so on, which intra-act with the world’s ‘differential becoming’ (Barad, Meeting the Universe Halfway, 89). De la Cadena engages with the performativity of concepts and classifications which emerge from onto-epistemic practices (de la Cadena, An Invitation to Live Together). ↩
- Barad, Meeting the Universe Halfway, 135. ↩
- Haraway, ‘Situated Knowledges’ ↩
- Mol, The Body Multiple, 158. ↩
- E.g. Bovens and Hartmann, Bayesian Epistemology; Dennis, ‘Discussion: Should Ecologists Become Bayesians?’; Sprenger and Hartmann, Bayesian Philosophy of Science; Morey, Romeijn, and Rouder, ‘The Philosophy of Bayes Factors and the Quantification of Statistical Evidence’. ↩
- Mol, The Body Multiple, 31. ↩
- Ian Hacking, The Emergence of Probability: A Philosophical Study of Early Ideas about Probability, Induction and Statistical Inference, 2nd ed. (Cambridge University Press, 2006), https://doi.org/10.1017/CBO9780511817557; Ian Hacking, The Taming of Chance, 1st ed. (Cambridge University Press, 1990), https://doi.org/10.1017/CBO9780511819766. ↩
- Mary Poovey, A History of the Modern Fact: Problems of Knowledge in the Sciences of Wealth and Society, 5. print (Chicago, Ill.: University of Chicago Press, 2007). ↩
- Poovey, xv. ↩
- E.g. Katrin Amelang and Susanne Bauer, ‘Following the Algorithm: How Epidemiological Risk-Scores Do Accountability’, Social Studies of Science 49, no. 4 (August 2019): 476–502, https://doi.org/10.1177/0306312719862049; Susanne Bauer, ‘Seeing Like a Model Fish: How Digital Extractions Mediate Metabolic Relations’, Science, Technology, & Human Values 49, no. 3 (May 2024): 524–54, https://doi.org/10.1177/01622439241236520; Gabriel G. Blouin, ‘Data Performativity and Health: The Politics of Health Data Practices in Europe’, Science, Technology, & Human Values 45, no. 2 (March 2020): 317–41, https://doi.org/10.1177/0162243919882083; Baki Cakici, Evelyn Ruppert, and Stephan Scheel, ‘Peopling Europe through Data Practices: Introduction to the Special Issue’, Science, Technology, & Human Values 45, no. 2 (March 2020): 199–211, https://doi.org/10.1177/0162243919897822; Francisca Grommé and Evelyn Ruppert, ‘Population Geometries of Europe: The Topologies of Data Cubes and Grids’, Science, Technology, & Human Values 45, no. 2 (March 2020): 235–61, https://doi.org/10.1177/0162243919835302; Minna Räsänen and James M. Nyce, ‘The Raw Is Cooked: Data in Intelligence Practice’, Science, Technology, & Human Values 38, no. 5 (September 2013): 655–77, https://doi.org/10.1177/0162243913480049; David Ribes, ‘STS, Meet Data Science, Once Again’, Science, Technology, & Human Values 44, no. 3 (May 2019): 514–39, https://doi.org/10.1177/0162243918798899; Anna Lowenhaupt Tsing, The Mushroom at the End of the World: On the Possibility of Life in Capitalist Ruins, New paperback printing (Princeton Oxford: Princeton University Press, 2021). ↩
- Anja Klein et al., ‘From Situated Knowledges to Situated Modelling: A Relational Framework for Simulation Modelling’, Ecosystems and People 20, no. 1 (31 December 2024): 2361706, https://doi.org/10.1080/26395916.2024.2361706. ↩
- E.g. Richard D. Morey, Jan‐Willem Romeijn, and Jeffrey N. Rouder, ‘The Humble Bayesian: Model Checking from a Fully Bayesian Perspective’, British Journal of Mathematical and Statistical Psychology 66, no. 1 (February 2013): 68–75, https://doi.org/10.1111/j.2044-8317.2012.02067.x. ↩
- Andrew Gelman, ‘Induction and Deduction in Bayesian Data Analysis’, 2011, https://doi.org/10.22029/JLUPUB-374; John K. Kruschke, ‘Posterior Predictive Checks Can and Should Be Bayesian: Comment on Gelman and Shalizi, “Philosophy and the Practice of Bayesian Statistics”’, British Journal of Mathematical and Statistical Psychology 66, no. 1 (February 2013): 45–56, https://doi.org/10.1111/j.2044-8317.2012.02063.x. ↩
- Gelman and Shalizi, ‘Philosophy and the Practice of Bayesian Statistics’; Gelman and Yao, ‘Holes in Bayesian Statistics *’. ↩
- Morey, Romeijn, and Rouder, ‘The Philosophy of Bayes Factors and the Quantification of Statistical Evidence’. ↩
- John Law and Vicky Singleton. ‘Performing Technology’s Stories: On Social Constructivism, Performance, and Performativity’. Technology and Culture 41, no. 4 (October 2000): 765–75. https://doi.org/10.1353/tech.2000.0167. ↩
- Klein et al., ‘From Situated Knowledges to Situated Modelling’. ↩
- Tobias Krueger and Rossella Alba, ‘Ontological and Epistemological Commitments in Interdisciplinary Water Research: Uncertainty as an Entry Point for Reflexion’, Frontiers in Water 4 (17 November 2022): 1038322, https://doi.org/10.3389/frwa.2022.1038322. ↩
- Anja Klein et al., ‘From Situated Knowledges to Situated Modelling: A Relational Framework for Simulation Modelling’, Ecosystems and People 20, no. 1 (31 December 2024): 2361706, https://doi.org/10.1080/26395916.2024.2361706. ↩
- Haraway, ‘Situated Knowledges’., 592. ↩
- Haraway., 580. ↩
- Haraway., 595. ↩
- Haraway., 595. ↩
- Haraway., 586. ↩
- Haraway., 595. ↩
- Haraway., 595. ↩
- Mol, The Body Multiple, 6. ↩
- Krystin Unverzagt, Enactments of Knowledge and Social Order in Participatory Modelling. An Ethnographic Perspective on the Relationship between Science and Democracy (Humboldt-Universität zu Berlin edoc-server, June 2025), https://doi.org/10.18452/33614. ↩
- Liboiron, Pollution Is Colonialism, 121. ↩
- Nadine Schuurman and Geraldine Pratt, ‘Care of the Subject: Feminism and Critiques of GIS’, Gender, Place & Culture 9, no. 3 (September 2002): 291–99, https://doi.org/10.1080/0966369022000003905. ↩
- Haraway, ‘Situated Knowledges’. ↩
- Contingency on model structure is not a uniquely Bayesian attribute. Yet, we aim to give an exemplary overview of the practices that occur in an actual research project that employs the Bayesian framework. In practice, Bayesian modelling cannot be done without more common practices such as building a model structure. It therefore cannot be considered in isolation from them. ↩
- Roads and tracks are rarely considered in ECMs but were after consultation with stakeholders. ↩
- Further developing P.J. Johnes, ‘Evaluation and Management of the Impact of Land Use Change on the Nitrogen and Phosphorus Load Delivered to Surface Waters: The Export Coefficient Modelling Approach’, Journal of Hydrology 183, no. 3–4 (September 1996): 323–49, https://doi.org/10.1016/0022-1694(95)02951-6. ↩
- The effects of land management practices, too, are not typically included in ECMs but were after consultation with stakeholders. ↩
- Using equations described in, for example, Dale M. Robertson et al., ‘Phosphorus and Nitrogen Transport in the Binational Great Lakes Basin Estimated Using SPARROW Watershed Models’, JAWRA Journal of the American Water Resources Association 55, no. 6 (December 2019): 1401–24, https://doi.org/10.1111/1752-1688.12792. ↩
- Ludwik Fleck, Entstehung und Entwicklung einer wissenschaftlichen Tatsache: Einführung in die Lehre vom Denkstil und Denkkollektiv, ed. Lothar Schäfer and Thomas Schnelle, 13. Auflage, Suhrkamp-Taschenbuch Wissenschaft 312 (Frankfurt am Main: Suhrkamp, 2021). ↩
- Jeremy J. Schmidt, ‘Water Quality and Availability’, in The Routledge Companion to Environmental Ethics, by Benjamin Hale, Andrew Light, and Lydia Lawhon, 1st ed. (New York: Routledge, 2022), 159, https://doi.org/10.4324/9781315768090-18. ↩
- Jamie Linton and Tobias Krueger, ‘The Ontological Fallacy of the Water Framework Directive: Implications and Alternatives’, Water Alternatives 13, no. 3 (2020): 513, https://www.water-alternatives.org/index.php/alldoc/articles/vol13/v13issue3/591-a13-3-9/. ↩
- Jamie Linton and Tobias Krueger, ‘The Ontological Fallacy of the Water Framework Directive: Implications and Alternatives’, Water Alternatives 13, no. 3 (2020): 513. ↩
- In fact, questions like this came up during stakeholder discussions in the wider project, the benefits of which will be discussed later on. We include footnotes wherever this was the case but focus on the affordances of the model structure. The term ‘stakeholder’ itself, much as it fits with the framing of the analytic-deliberative project that the model was developed in, could also be unpacked in terms of who these actors were (not), how they became involved and what form their participation took exactly. ↩
- For example, inputs such as phosphate-containing cleaning products and processed foods that include phosphorus additives are not explicitly included in the model structure at hand but wrapped up in the bulk nutrient loads of treated wastewater discharge. The precise location, differentiated maintenance and proper functioning of septic tanks are also not included in the model structure. By modelling bulk nutrient loads as a function of the estimated population connected to septic tanks, all septic tanks are assumed to work similarly well. ↩
- Adrian Mackenzie, ‘The Production of Prediction: What Does Machine Learning Want?’, European Journal of Cultural Studies 18, no. 4–5 (August 2015): 429–45, https://doi.org/10.1177/1367549415577384; Bauer, ‘Seeing Like a Model Fish’. ↩
- Various ethical theories exist. Consequentialist theories such as utilitarianism locate the good in substantive outcomes. Deontological theories focus on the inherent nature of acts and on certain actors’ obligations. Contractual theories locate the good in agreements on how to determine and pursue the good that preserve basic rights and freedoms. The capability approach to justice locates the (inconclusive) good in situational deliberations of preferences for action given everyone’s right to equal capacities to pursue social functionings. Care ethics locates the good in good relations, which enable consideration of unequally distributed needs and capacities to give care. Other ethical theories and various subforms of these ways of conceiving of the good exist. These different versions of ethics also revolve around dimensions of contrast such as the relevance of different subjects to ethical considerations (Unverzagt, Enactments of Knowledge and Social Order, 50-56; 72-98). In line with our methodological approach and somewhat contrary to moral philosophy, we approach the good in this article as a multiple object, an object that is continually in the making rather than of an essence. We suggest that water research practices enact aspects of the world that are relevant to ethics, including the ethical subject, the location of the good, ways of knowing about the state of the good and of attaining the good. Historically, for example, water research and policy have often established a conflation between the good of the community and the good of the state, or between the good and the aggregated individual good of members of the political community (Schmidt, ‘Water Quality and Availability’, 159). ↩
- As described in Mary O’Brien, Making Better Environmental Decisions: An Alternative to Risk Assessment (Cambridge: MIT Press, 2000). ↩
- Donella Meadows, ‘Places to Intervene in a System’, Whole Earth 91, no. 1 (1997): 78–84. ↩
- Discussed as ‘surveillant science’ by Stuart N. Lane et al., ‘Surveillant Science: Challenges for the Management of Rural Environments Emerging from the New Generation Diffuse Pollution Models’, Journal of Agricultural Economics 57, no. 2 (July 2006): 239–57, https://doi.org/10.1111/j.1477-9552.2006.00050.x. ↩
- This is another aspect that was discussed at stakeholder meetings and carried out separately from modelling by very different means, e.g. farm advice. ↩
- Though such discussion ensued around the model in the wider stakeholder meetings of the project. ↩
- The inclusion of land management practices in the model structure enacts a particular version of the social, of collective action and of ethics that some of us have discussed elsewhere (Klein et al., ‘From Situated Knowledges to Situated Modelling’, 14 ↩
- Liboiron, Pollution Is Colonialism, 156. ↩
- Such discussions happened in the stakeholder group with regard to meat and dairy products or with respect to tourism, highlighting complex entanglements of local people’s livelihoods with what by some may be perceived as luxury goods or services. ↩
- The ‘distributed agency’ of Klein et al., ‘From Situated Knowledges to Situated Modelling’. ↩
- Many more data preparation and modelling steps could be unpacked here. We refrain from doing so, as the purpose of this paper is to give an exploratory overview of how Bayesian modelling practices bring forth situated knowledges. ↩
- The implied notion of the modern ‘fact’ as a unit of knowledge is itself a historically contingent piece of knowledge (Poovey, A History of the Modern Fact). Iris Murdoch for example has suggested that the world consists in general forms for which hierarchies of images exist (Iris Murdoch, Metaphysics as a Guide to Morals (New York, New York, U.S.A.: Allen Lane, The Penguin Press, 1993), 183), contradicting the notion of instantiations of a more general entity. Deleuze and Guáttari (Gilles Deleuze and Félix Guattari, What Is Philosophy?, Repr (London: Verso, 2015)) have argued that people know the world in terms of concepts that exist on a plane of immanence and maintain rhizomatic relationships with each other. George Berkeley has argued that abstraction is nonsensical because properties, like colour or dimension, cannot be isolated from each other (P. J. E. Kail, Berkeley’s A Treatise Concerning the Principles of Human Knowledge: An Introduction, 1st ed. (Cambridge University Press, 2014), https://doi.org/10.1017/CBO9780511736506.). ↩
- Gilles Deleuze, Difference and Repetition, 2nd ed, Bloomsbury Revelations Ser (London: Bloomsbury Publishing Plc, 2014). ↩
- Differences, for example, that occur along with variation of time and space or only in individual cases are discounted in favour of differences that point to identity (Melissa McMahon, ‘Difference, Repetition’, in Gilles Deleuze, ed. Charles J. Stivale (McGill-Queen’s University Press, 2005), 42–52, https://doi.org/10.1515/9780773584884-007.45-46). Other ways of apprehending difference have been advanced by, for example, Gilles Deleuze (Deleuze, Difference and Repetition). Deleuze argues that difference is not subjugated to the identical. Difference-in-itself, by contrast, is a kind of difference that can be thought without ‘identity’ as a sufficient condition (Deleuze, 346). Identity is made through repetition, a differential variation across series, as opposed to generality. Boundaries that arise in repetition allow us to sort a thing or being into classes (James Williams, Gilles Deleuze’s Difference and Repetition: A Critical Introduction and Guide, Critical Introductions and Guides CIG (Edinburgh: Edinburgh University Press, 2013), https://doi.org/10.1515/9780748668946., 11-12). Yet, each member or instantiation sustains different relations to an infinite number of other repetitions, making them all individuals in their own right. Difference in itself according to Deleuze therefore ‘runs through a series’, it is the continuous potential for a change of identities (James Williams, ‘Difference and Repetition’, in The Cambridge Companion to Deleuze, ed. Daniel W. Smith and Henry Somers-Hall, 1st ed. (Cambridge University Press, 2012), 33–54, https://doi.org/10.1017/CCO9780511753657.003.; Williams, Gilles Deleuze’s Difference and Repetition.12) and being is irreducibly differential (Jon Roffe and Gilles Deleuze, The Works of Gilles Deleuze. I, 1953-1969 (Melbourne: Re.press, 2020), 159). On these grounds, Deleuze criticises the ‘modes of thought’, ‘good sense’ and ‘common sense’, which, he argues, wrongfully suggest that people can treat the universe in terms of permanent objects, qualified objects which assert their identity across variable circumstances (Deleuze, 293-340). Statistics, from this point of view, represents a particular way of apprehending difference in the sense of subordinating difference to identity. ↩
- Poovey, A History of the Modern Fact, xii. ↩
- David Spiegelhalter, ‘Introducing The Art of Statistics: How to Learn from Data’, Numeracy 13, no. 1 (January 2020): 7–10, https://doi.org/10.5038/1936-4660.13.1.7. ↩
- Ribes, ‘STS, Meet Data Science, Once Again’. ↩
- Gabrielle Bouleau, ‘The Co-Production of Science and Waterscapes: The Case of the Seine and the Rhône Rivers, France’, Geoforum 57 (November 2014): 24, https://doi.org/10.1016/j.geoforum.2013.01.009. ↩
- Bouleau, 22. ↩
- Bouleau, ‘The Co-Production of Science and Waterscapes’; Linton and Krueger, ‘The Ontological Fallacy of the Water Framework Directive: Implications and Alternatives’. ↩
- Räsänen and Nyce, ‘The Raw Is Cooked’. ↩
- Hacking, The Emergence of Probability, xi–xxxiv. ↩
- Blouin, ‘Data Performativity and Health’. ↩
- Susan Leigh Star, ‘Introduction: The Sociology of Science and Technology’, Social Problems 35, no. 3 (June 1988): 198, https://doi.org/10.2307/800618. ↩
- See Jelena Bäumler, ‘Rise and Shine: The No Harm Principle’s Increasing Relevance for the Global Community’, in The Global Community Yearbook of International Law and Jurisprudence 2017, ed. Giuliana Ziccardi Capaldo, 1st ed. (Oxford University Press, 2018), 149–74, https://doi.org/10.1093/oso/9780190923846.003.0007. ↩
- Mary Douglas, Purity and Danger; an Analysis of Concepts of Pollution and Taboo (London: Routledge & Paul, 1966). ↩
- Joel Feinberg, ‘Environmental Pollution & the Threshold of Harm’, The Hastings Center Report 14, no. 3 (June 1984): 27, https://doi.org/10.2307/3561186. ↩
- Liboiron, Pollution Is Colonialism. ↩
- The amount of phosphorus in manure, for example, varies along with a number of conditions such as feeding conventions. ↩
- Separating nutrient-rich wastewater in sanitary facilities is, for example, an alternative to removing nutrients at STWs that is not currently viable due to, among other things, historically grown infrastructures and habits (see Spångberg et al. 2024). ↩
- Schmidt, ‘Water Quality and Availability’, 159 f. According to Schmidt, object-given ethical reasoning assumes that facts provide reasons to act in certain ways. The facts themselves make certain outcomes worth pursuing, or certain things worth doing. ↩
- Michael Walsh, Gerhard Schenk, and Susanne Schmidt, ‘Realising the Circular Phosphorus Economy Delivers for Sustainable Development Goals’, Npj Sustainable Agriculture 1, no. 1 (4 October 2023): 1–15, https://doi.org/10.1038/s44264-023-00002-0. ↩
- Phosphorus pollution, for example, was not considered a problem when it was killing female factory workers in the 19th century (Susan Isaac, ‘“Phossy Jaw” and the Matchgirls: A Nineteenth-Century Industrial Disease’, Royal College of Surgeons of England (blog), 28 September 2018, https://www.rcseng.ac.uk/library-and-publications/library/blog/phossy-jaw-and-the-matchgirls/). Nowadays, the same goes for workers in phosphate mines in, for example, Morocco and Tunisia (Natasha White, ‘Toxic Shadow: Phosphate Miners in Morocco Fear They Pay a High Price’, The Guardian, 16 December 2015, sec. Global development, https://www.theguardian.com/global-development/2015/dec/16/toxic-shadow-phosphate-miners-morocco-fear-they-pay-high-price). ↩
- Liboiron, Pollution Is Colonialism, 28. ↩
- Liboiron, 82. ↩
- Liboiron, Pollution Is Colonialism, 116. ↩
- E.g., Robert G. Wetzel, ‘THE PHOSPHORUS CYCLE’, in Limnology (Elsevier, 2001), 239–88, https://doi.org/10.1016/B978-0-08-057439-4.50017-4. ↩
- A.N. Sharpley and A.D. Halvorson, ‘The Management of Soil Phosphorus Availability and Its Impact on Surface Water Quality’, in Soil Processes and Water Quality, by B.A. Stewart, ed. R. Lal and B. A. Stewart, 1st ed. (CRC Press, 1994), 7–90, https://doi.org/10.1201/9781003070184-2. ↩
- Richard J. Cooper et al., ‘Sensitivity of Fluvial Sediment Source Apportionment to Mixing Model Assumptions: A Bayesian Model Comparison’, Water Resources Research 50, no. 11 (November 2014): 9031–47, https://doi.org/10.1002/2014WR016194. ↩
- Krueger, ‘Bayesian Inference of Uncertainty in Freshwater Quality Caused by Low-Resolution Monitoring’. ↩
- E.g. David J. Nott, Lucy Marshall, and Jason Brown, ‘Generalized Likelihood Uncertainty Estimation (GLUE) and Approximate Bayesian Computation: What’s the Connection?’, Water Resources Research 48, no. 12 (December 2012): 2011WR011128, https://doi.org/10.1029/2011WR011128. ↩
- Mikael Sunnåker et al., ‘Approximate Bayesian Computation’, ed. Shoshana Wodak, PLoS Computational Biology 9, no. 1 (10 January 2013): e1002803, https://doi.org/10.1371/journal.pcbi.1002803. ↩
- Hacking, The Emergence of Probability, 31. ↩
- Hoseung Jung, ‘Uncertainty in Water Quality Monitoring, Data Analysis and Modelling – and a Buddhist Contemplation on Its Suffering’ (Humboldt-Universität zu Berlin, 10 October 2023), https://doi.org/10.18452/27074. ↩
- As opposed to, to cite just one among many examples, a view on people as moral beings who live (well) by progressing through shifts in schemes of concepts (as laid out in, for example, Iris Murdoch, The Sovereignty of Good, Routledge Classics (London: Routledge, 2006, 1-44). ↩
- It has been suggested that after David Hume had claimed that observations on the design of the world could not serve to infer a cause – god’s existence, Bayes constructed his theorem to conclude that such an inference was, indeed, possible (Bertsch McGrayne 2011, 3-7). ↩
- James O. Berger et al., ‘An Overview of Robust Bayesian Analysis’, Test 3, no. 1 (June 1994): 5–124, https://doi.org/10.1007/BF02562676. ↩
- Fourteen export coefficients for the land use classes (kilogramme per hectare and year), 4 export coefficients for the livestock classes (kilogramme per capita per year), 36 reduction percentages for the BMPs, 1 export coefficient for septic tanks (kilogramme per capita and year), 1 export coefficient for STWs prior to nutrient stripping (kilogramme per capita and year), 1 export coefficient for roads/tracks (kilogramme per km and year), 32 export coefficients for various industries (kilogramme per year), 1 first-order decay rate for the river (per kilometre), 1 first-order decay rate for the lakes/reservoir (per square kilometre). ↩
- A.R. Forsyth, K.A. Bubb, and M.E. Cox, ‘Runoff, Sediment Loss and Water Quality from Forest Roads in a Southeast Queensland Coastal Plain Pinus Plantation’, Forest Ecology and Management 221, no. 1–3 (January 2006): 194–206, https://doi.org/10.1016/j.foreco.2005.09.018; Gary J. Sheridan and Philip J. Noske, ‘Catchment‐scale Contribution of Forest Roads to Stream Exports of Sediment, Phosphorus and Nitrogen’, Hydrological Processes 21, no. 23 (November 2007): 3107–22, https://doi.org/10.1002/hyp.6531. ↩
- J.P. Newell Price et al., ‘An Inventory of Mitigation Methods and Guide to Their Effects on Diffuse Water Pollution, Greenhouse Gas Emissions and Ammonia Emissions from Agriculture’ (Devon: Rothamsted Research, North Wyke, December 2011), https://repository.rothamsted.ac.uk/download/942687eab7ec4b83751c7e241d62f0fa8472d72adcd25a149bb891b7c30d55d0/1595300/MitigationMethods-UserGuideDecember2011FINAL.pdf. ↩
- McGrayne, The Theory That Would Not Die, 8–9. ↩
- van de Schoot et al., ‘Bayesian Statistics and Modelling’, 4. ↩
- We have identified the ‘object’ ‘socio-political-ethical order’ due to our interpretation of the material in terms of assumptions on, among other things, the public good (e.g. where it is located–for example, substantive outcomes, good practices, actions, people–how to attain it, how to know about the state of the good), ethical subjects (e.g. who is relevant to considerations of the good, who can legitimately contribute knowledge about the good), and politics (e.g. who relevant actors are, how they relate to one another, how politics relates to the good, what politics aims towards, what scale is appropriate for politics). ↩
- These calculations were in fact done on the back of the model in a separate assessment, bringing in other contextual factors and inputs from stakeholder groups (e.g. farmers were assessing the impacts of suggested measures on their businesses). Because these separate analytical processes were not coupled, this slowed down the process in a productive way, allowing for deliberations on various issues. The stakeholder process, in this way, served to enact various other versions of the social, the political, and the good. ↩
- Arthur Cecil Pigou, The Economics of Welfare, 1st ed. (London: Macmillan, 1912). ↩
- Ottmar Edenhofer et al., ‘Closing the Emission Price Gap’, Global Environmental Change 31 (March 2015): 132–43, https://doi.org/10.1016/j.gloenvcha.2015.01.003; Klaus Eisenack, O Edenhofer, and M Kalkuhl, ‘Efficiency and Distribution Effects of Resource and Energy Taxes for Climate Protection’, IOP Conference Series: Earth and Environmental Science 6, no. 10 (1 February 2009): 102014, https://doi.org/10.1088/1755-1307/6/10/102014; Max Franks et al., ‘Pigou’s Advice and Sisyphus’Warning: Carbon Pricing With non-Permanent Carbon Dioxide Removal’, 2024, https://doi.org/10.2139/ssrn.4828800. ↩
- Steven G. Medema, ‘“Exceptional and Unimportant”?’, History of Political Economy 52, no. 1 (24 October 2019): 135–70, https://doi.org/10.1215/00182702-8009583. Other conceptualisations of the political economy foreground, for example, voluntary cooperation (such as Elinor Ostrom, ‘Collective Action and the Evolution of Social Norms’, The Journal of Economic Perspectives 14, no. 3 (2000): 137–58, https://www.jstor.org/stable/2646923.), tolerable standards (William J. Baumol, ‘On Taxation and the Control of Externalities’, The American Economic Review 62, no. 3 (1972): 307–22, https://www.jstor.org/stable/1803378), or bargaining (“Coase theorem.” Oxford Reference.; Accessed 15 Sep. 2024). https://www.oxfordreference.com/view/10.1093/oi/authority.20110803095620155). ↩
- Cooper et al., ‘Sensitivity of Fluvial Sediment Source Apportionment to Mixing Model Assumptions’. ↩
- Jasper A. Vrugt, ‘Markov Chain Monte Carlo Simulation Using the DREAM Software Package: Theory, Concepts, and MATLAB Implementation’, Environmental Modelling & Software 75 (January 2016): 273–316, https://doi.org/10.1016/j.envsoft.2015.08.013. ↩
- Dennis Mocigemba, ‘Sustainable Computing’, Poiesis & Praxis 4, no. 3 (September 2006): 163–84, https://doi.org/10.1007/s10202-005-0018-8. ↩
- The first model set a prior for the phosphorus export of the responsible industry that effectively excluded the possibility of extraordinary events. To revise the model, the modeller chose to iteratively broaden the responsible industry’s prior range, thus implicitly suggesting that accidental events do not exempt sectors from responsibility, and accidents belong with the actors that are tasked with preventing them. They decided it was only necessary, however, to consider actual accidents in terms of their contribution to the load and unnecessary to include the spill as a separate parameter or potential accidents in other sectors by, for example, broadening the prior range for all parameters. This, again, produces a partial perspective with consequences for the kinds of responsibilities that can be made through the model. Broadening all prior ranges would have resulted in more uncertain model predictions because there was little information to constrain the magnitude of any possible spill. In this sense, the approach combined ‘technical’ and ‘ethico-political’ considerations, which were inseparable in practice. ↩
- Mary B Hesse, ‘Models in Physics’, The British Journal for the Philosophy of Science 4, no. 15 (1953): 198–214. ↩
- Theoretically it is possible to explore more ‘universal’ model structures within a Bayesian modelling framework. Green (Peter J. Green, ‘Reversible Jump Markov Chain Monte Carlo Computation and Bayesian Model Determination’, Biometrika 82, no. 4 (1995): 711–32, https://doi.org/10.1093/biomet/82.4.711) introduced a transdimensional Markov chain Monte Carlo algorithm that is capable of comparing models with different parameter numbers as part of the posterior sampling. In practice, these more ‘universal models’ may be approximated by using artificial neural network models, where the model behaviour can be altered (infinitely) just by introducing or removing new neurons in a procedural way. Yet, according to the perspective laid out in this article, the resulting knowledge will remain partial, because knowing through neural network models itself is a distinct, socio-materially embedded practice with socio-material implications. ↩
- In the sense of Haraway (1988). ↩
- Marilyn Strathern, ed., Audit Cultures: Anthropological Studies in Accountability, Ethics and the Academy, 1. publ, European Association of Social Anthropologists (London: Routledge, 2000). ↩
- Bruno Latour, We Have Never Been Modern (Harvard university press, 2012). ↩
- Haraway, ‘Situated Knowledges’. ↩
- Deleuze, Difference and Repetition, 297. ↩
- In the case at hand, for example, the model participates in creating responsibility, in locating harm, in making nutrients problematic, in enabling a limited range of policy options, in reconfiguring socio-material relations between researchers, research infrastructures, and local people, and much more. ↩
- De La Cadena, Earth Beings. ↩
- Liboiron, Pollution Is Colonialism, 138. ↩
- Michelle Fine, ‘Bearing Witness: Methods for Researching Oppression and Resistance—A Textbook for Critical Research’, Social Justice Research 19, no. 1 (1 March 2006): 83–108, https://doi.org/10.1007/s11211-006-0001-0. ↩
- Fine, 88. ↩
- Fine, 91. ↩
- Patrick Bieler et al., ‘Distributing Reflexivity through Co-Laborative Ethnography’, Journal of Contemporary Ethnography 50, no. 1 (February 2021): 77–98, https://doi.org/10.1177/0891241620968271. ↩
- Eve Tuck and Marcia McKenzie, ‘Relational Validity and the “Where” of Inquiry: Place and Land in Qualitative Research’, Qualitative Inquiry 21, no. 7 (September 2015): 633–38, https://doi.org/10.1177/1077800414563809. ↩
- Schmidt, ‘Water Quality and Availability’, 164. ↩
- Liboiron, Pollution Is Colonialism, 138 ff. ↩
- Klein et al., ‘From Situated Knowledges to Situated Modelling’. ↩