Introduction
Uber, Airbnb, Google, Amazon and Netflix are names that stress how data-driven systems are reshaping the world. Yet these platforms and services would not be possible without the data infrastructure that underpins them. Far from being nebulous and immaterial, “the cloud” is highly material, taking the form of the copper and cables, switches and server racks that comprise the data center and its accompanying infrastructure.1 Often overlooked by consumers, these data centers nevertheless play a critical role, delivering media streams, ferrying financial transactions, storying health data, and deriving insights through machine learning. As everyday activities increasingly become digitally mediated, the control and distribution of this data becomes not just a technical question, but a social and political one.2
Yet if data centers are increasingly influential, they are often conceived as a black-box.3 Typically off limits to researchers, what can be determined is often gleaned from high level technical specifications: a building spanning several thousand meters of floor space, which may contain a certain number of server racks, and which is driven by an infrastructure capable of producing a certain amount of megawatts of power. Specific details—the names and numbers of clients, the precise amount of water and energy used, the routing of data, and the largest markets—are all proprietary information that remains undisclosed for reasons of both client security and business competitiveness.
Recently however, Alibaba, the Chinese cloud computing giant, released major datasets from its production cluster.4 In essence, a production cluster is simply a large number of servers that are grouped together by scheduling software. The cluster management system assigns jobs to machines in the cluster and manages the allocation of resources to it. The 2017 dataset includes about 1300 machines over a period of 12 hours. The 2018 dataset is much larger and more detailed, with 5 files totaling 270 gigabytes, and includes data from around 4000 machines over a period of 8 days.
Certainly there are limitations in this dataset. Unfortunately, Alibaba does not disclose exactly where this cluster is located, nor whether these machines are housed in a single data center or spread across multiple sites. Moreover, while the times and durations of jobs are given, what exactly the job entails—moving data? performing queries on databases? generating machine learning models?—is never specified. Finally, machines are simply numbered as a series—how they are racked or arranged spatially in the building is unknown. As with any dataset, these gaps set limits on what can be inferred. However, given the typically black-boxed nature of data centers, the public release of this information already represents an interesting resource for researchers and a welcome step towards transparency from cloud operators.
Why was this data made publicly available? To a certain extent, Alibaba’s claim that these help to “bridge the knowledge gap between many of us and academic researchers/industrial experts” is not unfounded.5 Without voluntary release of this information, it would be off limits to all but a handful of data center employees. However, the publishing of this data is not entirely selfless. At the time of writing, eight journal articles had been produced based on this dataset.6 Alibaba links to these articles from the cluster webpage and encourages authors to notify them when an article is published. Each article analyses the data in different ways and delivers its own findings in terms of problems and possible improvements. As one paper observes: “researchers can study the workload characteristics, analyze the cluster status, design new algorithms to assign workloads, and help to optimize the scheduling strategies between online services and batch jobs for improving throughput while maintaining acceptable service quality.”7 By releasing the data, Alibaba gets to draw on the expertise and training of dozens of computer scientists around the world. Their knowledge production provides valuable insights, which in turn may become folded back into day-to-day operations at the cloud company.
In this article, the Alibaba archive is explored through data visualization. Of course, data visualization itself is subjective rather than objective.8 While it provides a way of understanding information, it is a mediation rather than a direct translation, a method that reveals some things while obscuring others. Decisions made by the designer concerning parameters, color, and form influence what is seen by the viewer.9 Nevertheless, these depictions can provide a productive way of exploring data and communicating dynamics in a visual rather than textual form. Data visualization can be particularly helpful in presenting essential information in big data.10 Data visualization can draw out trends or relationships from the millions of data points in these vast repositories, which can often seem arbitrary or formless. If these patterns are made clear by design, they are beneficial in initiating a broader discussion.
What are the aims of this work and its broader intervention? Certainly exploring the normally inaccessible operations of a real-world data center is of interest. Yet the intent here is not to improve data center efficiency by delivering a list of optimizations to be implemented. Indeed, the kind of quantitative performance testing carried out in computer science is a highly technical undertaking requiring an engineering background. However, neither does this intervention want to simply dismiss the notion of efficiency altogether, as might be the tendency when coming from a humanities or social science perspective.
Instead, the article uses data center infrastructures as a way to consider efficiency at both an operational and political level. The first half of the article explores the complexity and contingency that pervades the data center on a practical level, showing how, even on its own terms, these infrastructures fail to achieve the efficiency ideal. The latter half of the article then moves into a discussion that questions efficiency itself and the values, assumptions, and norms bound up with this ideal. In balancing these twin goals, the article wants to model a contribution that is technically aware yet also theoretically critical. Such an interdisciplinary approach seems increasingly apt for our contemporary moment where data infrastructures have become a site of significant political force.11
The article, to briefly signpost, consists of four sections. The first section establishes some context around efficiency in computing and traces a brief history of the struggle to improve it. The second section steps through each data visualization, detailing the ways in which the data center fails to achieve the efficiency imaginary. The third section touches briefly on the industry’s scapegoat for this inefficiency: human labor and incomplete automation. And the fourth section opens out to an extended discussion that questions efficiency more fundamentally. What does this framing device reveal, what does it obscure, and how might we critically understand efficiency within these machine-centric environments?
The Struggle For Efficiency
We begin by examining the data center industry according to efficiency’s own terms. Seen through this particular lens, the industry has long struggled. Data centers consume vast amounts of energy in order to power and cool servers, which run around the clock without interruption. Indeed, the voracious appetite of data centers for energy is not slowing. One study estimated that data centers will use around 3–13% of global electricity in 2030 compared to 1% in 2010.12 Along with the obvious financial cost, the enormous environmental impact of this demand has increasingly been recognized, even within the industry itself. Papers have begun to analyze and quantify the sustainability of data centers.13 A more recent paper by computer science engineers admitted bluntly: “Data centers are key contributors of greenhouse gas emissions that pollute the environment and cause global warming.”14
One of the reasons for this inefficiency is that availability is all-important in the industry. Servers must be always-on and always-running, allowing files to be accessed, services to remain online, transactions to complete, and queries to be returned. Quality-of-service contracts between data center operators and clients guarantee extremely high availability rates. “Three nines” (99.9%) availability, once the gold standard, has been ratcheted up in recent years to four, five, or even six nines.15 Indeed, a coveted Tier IV rating—an enormously influential metric in the industry—is awarded only to those facilities who can expect a maximum of 20 minutes downtime per year based on their highly redundant infrastructure.16 Interruptions, whether caused by human error or natural disaster, must be avoided at all costs. Yet servers, while constantly draining energy, only spend a fraction of their time and resources carrying out work for clients. “Such low efficiencies,” admitted one industry insider, “made sense only in the obscure logic of digital infrastructure.”17
One of the first widely adopted technologies aiming to improve efficiency was the hypervisor. Gaining its name from being “the supervisor of the supervisor,” hypervisors were actually created in the mid 1960s by IBM in order to test different “virtual machines” on the same hardware. At that time, institutions typically had a single mainframe that could only be used by one person at a time. Time-sharing and virtualization techniques aimed to bypass this limit, splitting up resources and allocating them to users.18 From very early on then, as Hu demonstrates in his Prehistory of the Cloud, computing was fixated on reducing “wasted” time and “idle” computing cycles. Virtualization partially addressed this problem by allowing “fixed units of labor and hardware to become mobile again.”19 Yet for several decades, hypervisors remained a niche concept, only employed for high-end mainframes. It wasn’t until hypervisors became available on commodity servers in the early 2000s that they became widely adopted in data centers. In late 2000, VMWare introduced its first server virtualization platform, followed by subsequent versions over the next years that introduced new features; In 2003, competitor Xen released its own virtualization offering, followed two months later by Microsoft.20 Already by 2005, virtualization was being recognized as a “killer app.”21
In essence, hypervisors provided flexibility, decoupling hardware and software. A machine was no longer fixed as a Windows box with 8GB of memory, for example. Instead, hypervisors could create multiple “virtual machines” on a single machine, each with its own operating system and allocation of resources. This ability allowed operators to combine multiple workloads onto fewer machines, improving efficiencies within the data center. For industry associations concerned with sustainability: “Consolidation using virtualization is one powerful tool that can be applied to many data centers to drive up server efficiency and drive down energy consumption.”22
Yet these measures were still not enough. In their 2009 book on “warehouse-scale computing” Google engineers Hoelzle and Barrosso quantified data center inefficiency. The engineers analyzed two clusters, each with 20,000 servers, over a two month period. The cluster with mixed workloads, including online services, was far from optimal in terms of efficiency. As the authors admit: “most of the time is spent within the 10–50% CPU utilization range,” with an average of only around 30% use.23 If Google was the most open in admitting to inefficiency, it is not the only case. One study on public clouds found that the average utilization of 10 Amazon Web Services servers was only around 7%.24 And recent studies based on the Alibaba cluster data put its utilization at less than 17%.25 This low level of activity is only compounded by the design of servers, which are engineered for a high use case. As the Google engineers explain: “This activity profile turns out to be a perfect mismatch with the energy efficiency profile of modern servers in that they spend most of their time in the load region where they are most inefficient.”26
As data centers grew in both size and number over the next few years, their energy use came under increasing scrutiny. Rather than being merely an industry or academic concern, critiques began appearing in more mainstream avenues. A US News and World Report story in 2009 described data centers as “energy hogs,” pointing to their rapidly growing demands and raising concerns about rolling blackouts and greenhouse gases.27 In 2012, the New York Times conducted a year long investigation into data center energy use. As part of the story they asked McKinsey & Company to analyze data center energy use. The firm found that “on average, they were using only 6 percent to 12 percent of the electricity powering their servers to perform computations”; indeed, after compiling documents and conducting interviews, the journalists concluded that rather than the “image of sleek efficiency and environmental friendliness” that was usually portrayed, “most data centers, by design, consume vast amounts of energy in an incongruously wasteful manner.”28 A TIME report the following year echoed these findings, warning that “computers and smartphones might seem clean, but the digital economy uses a tenth of the world’s electricity—and that share will only increase, with serious consequences for the economy and the environment.”29
“The data center needs an operating system,” claimed Benjamin Hindman (2014) in a rather prescient and widely referenced article for O’Reilly Media: “It’s time for applications—not servers—to rule the data center.”30 Hindmann argued that the status quo of considering the data center as a set of machines was fundamentally wrong. This mindset was encouraging developers to do the most logical thing when deploying their services—assign one application per machine. But as Hindman asked:
What happens when a machine dies in one of these static partitions? Let’s hope we over-provisioned sufficiently (wasting money), or can re-provision another machine quickly (wasting effort). What about when the web traffic dips to its daily low? With static partitions we allocate for peak capacity, which means when traffic is at its lowest, all of that excess capacity is wasted. This is why a typical data center runs at only 8-15% efficiency.
For Hindman, hardware still dictated data center operations. Software was being led by legacy architecture that operated on a machine by machine basis. This inflexibility produced inefficiency. Instead, storage and processing capacity should be understood and managed as fluid resources. Compute should be malleable, able to be rapidly redeployed as needed. In essence, Hindman’s vision consisted of two steps: “Pool together the basic compute resources from multiple data center clusters into a single virtual infrastructure. Then distribute scalable workloads throughout that pool and continually manage them for efficiency.”31
Bringing this rhetoric down to earth somewhat, Hindman’s “data center operating system” was a container cluster manager. Rather than isolated machines running individual software, the cluster manager functions as a kind of conductor, orchestrating their scheduling and execution of all the workloads and services running on a cluster.32 On a technical level, rather than hypervisor-based virtualization, it was container-based virtualization.33 Hindman’s own product, Mesos DC/OS, joins a marketplace of other container cluster managers like Docker Swarm and Kubernetes. The latter, while now widely adopted by companies and a developer community, is an open-source version of Google’s own cluster management tool that it had used in-house for years.34
Alibaba also runs their own cluster management system, which consists of agents and schedulers. In 2015, in an effort to increase efficiency, they came up with a plan to combine two types of jobs into the same cluster. Broadly speaking, jobs in the data center can be divided into two types. Firstly, there are online service jobs. These are consumer facing and so often require low latency in order to function and feel responsive. As one example, this might be an e-commerce service that processes the credit cards of shoppers. These services are not typically processor intensive, but must remain continually on and constantly available, maintained around the clock. Their use will vary greatly, from a trickle of users to massive spikes in demand, requiring the ability to swiftly expand and grab more resources like storage and processors. Indeed, the millions of online transactions during the “Double 11 Global Shopping Festival”—a major ecommerce event that now dwarfs Black Friday and Cyber Monday—provides one of the acid tests for these kinds of online service jobs.
Secondly, there are offline batch jobs. These are typically about processing information rather than providing a service. For this reason they are not consumer facing, nor time sensitive in the same way. Indeed, sometimes these are run as “nightlies”, leveraging down time overnight in order to be available the next morning. These often take the form of highly processor intensive tasks: data mining of massive datasets, machine learning applications, large scale computing, and so on. To accelerate the completion of these jobs, the cloud can leverage parallel computing frameworks, where tasks are split into smaller subtasks, farmed out to many machines simultaneously, and then assembled back together again.
Typically these two types of jobs have been placed on separate clusters, or groups of machines. Yet if this separation was clean and straightforward conceptually, it was highly inefficient in terms of utilizing data center resources. A cluster dedicated only to offline batch jobs, for instance, would require cooling and power throughout the entire day, but might only be carrying out “real work” for a small portion of that time. Conversely, online services might not be using all the resources provisioned to them; this spare capacity could potentially be sunk into processor-intensive offline batch jobs. Both financially and environmentally, then, this architecture contributed towards significant wastefulness and a misuse of resources.
Co-allocation strives to remedy this problem.35 The basic concept is that both job types are allocated to the same cluster, allowing resources to be used where and when they are needed. Rather than sitting idle and draining power, machines should remain active, moving back and forth between offline and online jobs as needed. Co-allocation deploys “latency-insensitive offline batch computing tasks and latency-sensitive online services in the same batch of machines in Alibaba data centers,” explains a page on Alibaba Developer, in doing so, “idle resources not being used by online services can be used offline to improve the overall machine utilization rate.”36 The next section steps through each data visualization in order to examine the successes and failures of this vision.
Visualizing (In)efficiency
The first image shows 1200 servers over the course of 11 hours, with each server represented by a single line. Every five minutes, the load of each server is polled. Load, in essence, is a figure expressing how many processes are waiting in the queue to access that server’s processor. When the line spikes upwards, it indicates the server is under high load; when it dips down, the server’s load is low at that point in time.
Looking across the image, what stands out is the many lines that almost perfectly mirror each other. Many lines follow the curves and undulations of the slopes above or below them. This pattern can be seen in the middle third of the image in particular. These matched lines show machines under a similar load pattern over the course of a day. This suggests that this group of machines has been assigned the same task—they are carrying out the same job for the same company. Rather than 1200 individual machines, we see here the extent to which processing in the data center is coordinated.
This insight resonates with broader changes in the data center industry. While some data centers do host dozens of smaller companies, it is the hyperscalers—companies like Facebook, Google, and Amazon—that are understood to be driving growth. Tech giants may rent out entire floors of a data center, occupying much of its capacity with their outsized square footage and energy demands. “Only five years ago you felt a 250,000 sq ft building with 10MW was a lot” recalled one industry insider, “now we may do a lease for 36MW for one client, and they’ll take it in six rooms.”37 Indeed, data centers actively pursue these kinds of “anchor tenants” for the guaranteed business and stability they provide.

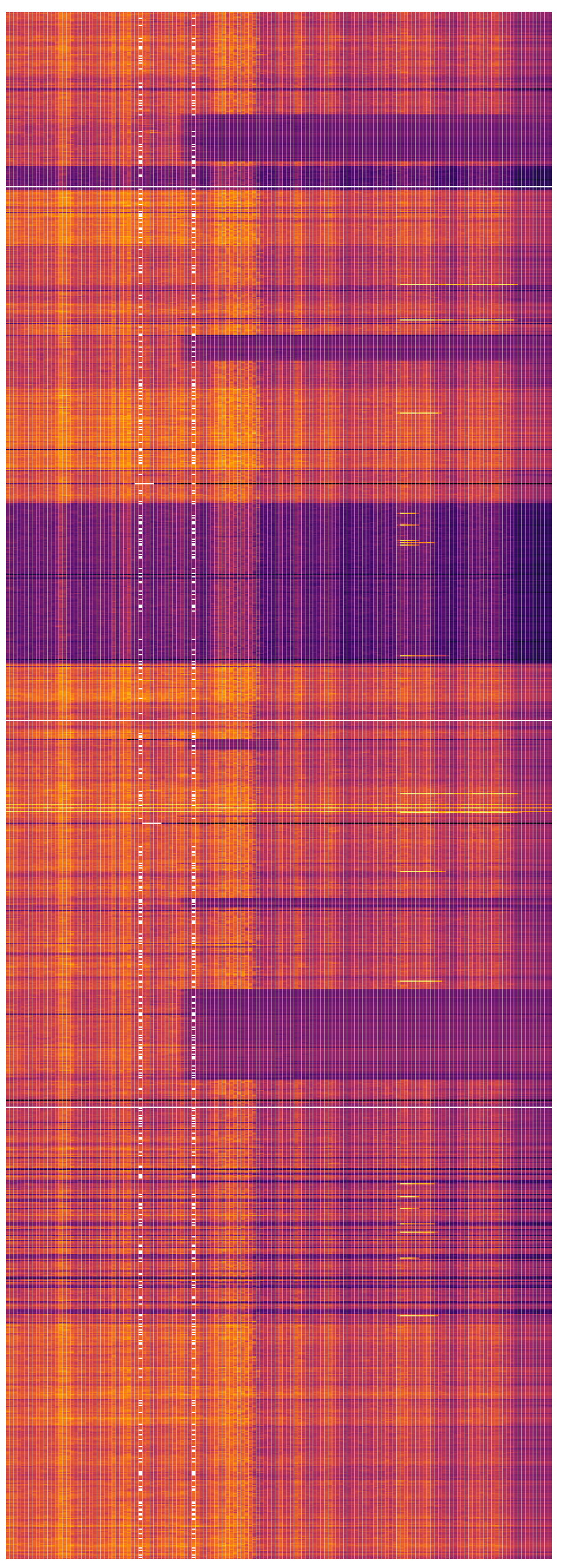
The second image draws upon the same dataset of 1200 machines over 11 hours, but focuses on memory utilization. Each server contains a certain amount of total memory. As a job is executed, this memory fills up with the data and instructions related to the job. Memory usage is one indicator of the intensity of processing required to carry out a job. Processing a few fields like name and credit card for an online payment, for instance, would only take a tiny portion of memory. In contrast, sorting millions of rows of a database or transforming hours of video would be a highly memory-intensive job. Visually, this image takes the form of a heat-map. Hotter colors like yellow and orange indicate memory usage closer to 100%, while cooler shades of purple represent low memory use (white rectangles in this image indicate gaps in the data for small moments of time).
Looking down the image, an uneven pattern immediately becomes apparent. On the one hand, we see a significant number of machines with hot colors throughout the 12 hours period. Oscillating between orange and yellow, these machines are almost constantly occupied with jobs that push their memory limits. Yet on the other hand, there are huge blocks of machines that remain purple or even black throughout the entire day. These machines are switched on—drawing power and costing the data center money—but are not carrying out any work for clients. According to the logic of efficiency, they are wasting resources.
This uneven performance in the Alibaba cluster has been pointed out by other researchers. In their 2017 paper, Lu and his co-authors described an “imbalance in the cloud.”38 This consists firstly in Spatial Imbalance. Ideally, the work scheduler would use all of the machines—the full “space” of computing resources—equally. Yet, echoing the finding above, Lu et al noted the “heterogeneous resource utilization across machines and workloads.”39 In other words, some machines are constantly churning, while others lie almost dormant for the entire day. Secondly, the authors noted a Temporal Imbalance, with “greatly time-varying resource usages per workload and machine.”40 As will be shown in the next image, some jobs require minutes or even hours, while others take less than a second. Finally, the authors observed the “Imbalanced proportion of multi-dimensional resources (CPU and memory) utilization per workload.”41 Jobs tend to drastically over-reserve resources like the processor and memory, only to use a tiny proportion of their allocated amount when they are actually run. More accurate estimates would leave more compute resources available, allowing other jobs to take up these resources and be completed.
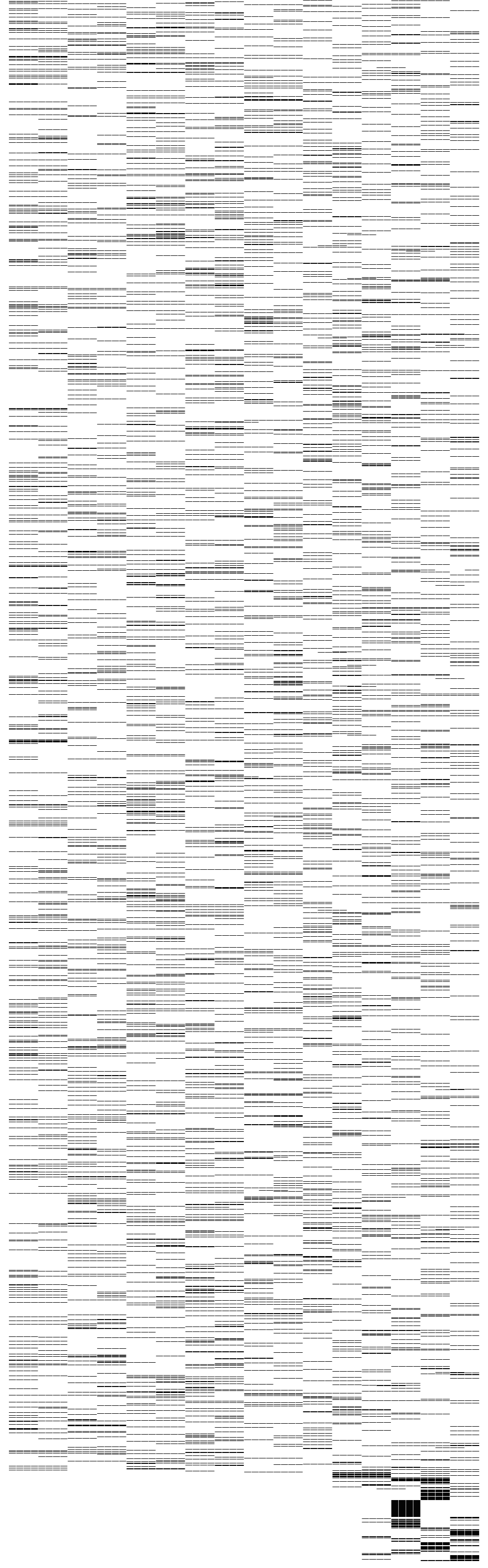
The third image shows the particular CPUs assigned to jobs over the 12 hour period. CPU is short for central processing unit, and can be understood colloquially as the brains of the machine, the core component that carries out calculations. In this cluster, a job can be assigned to any one of 64 total machines, represented by 64 lines from left to right. In practice, jobs are typically assigned to 4 or 8 CPUs at a time, indicated by 4 or 8 lines next to each other. By scrolling down the image, we can see the ways in which jobs are allocated throughout the day.
While the resulting image is rather complex, the key point here is that Alibaba’s allocation system is attempting to balance CPU use across the cluster. A perfectly load-balanced cluster strives to equally allocate jobs, giving new jobs to unused CPUs—in this visualization, to never have repeating lines. However, scrolling down the image reveals a number of thick black repeating lines, showing where the same group of CPUs has been selected over and over to carry out each new job. As this group is repeatedly hit with new work, we could assume that its temperature rises and more cooling is needed, requiring in turn more energy. This trend becomes acute at the very end of the day (the bottom of the image), where long black squares show how CPUs #44 – #64 are repeatedly pummeled by new jobs, while the rest of the CPUs in the cluster go entirely unused.
The fourth image focuses on the timing and duration of tasks that machines carry out. Over the same 12 period, this production cluster carries out around 13,000 tasks. The data provided by Alibaba logs when the task began and when it was completed. Visually, each task is depicted by a colored line, with the entire image representing a timeline of the day moving from left to right.
Here, as mentioned above, we can witness the temporal imbalance pointed out by Lu and colleagues. The red line near the top, for instance, displays a task that takes several hours to complete, while the blips and dots that punctuate the image indicate jobs that last only seconds. Of particular note is the task “waterfall”, the cascade of lines that occurs towards the end of the day. Looking down the image, an almost identical cascade can be seen in the same period over and over again. As discussed in the first image, this sequence of short tasks is a highly coordinated level of processing, suggesting a single client with nearly identical jobs to be completed.

The fifth image focuses on the status of 1 million Alibaba instances over time. Each pixel is one instance. Ready and Waiting instances are displayed in grey, Running in green, Terminated and Failed in red, and Cancelled and Interrupted in orange. While green dominates the image, indicating that most instances complete with no issues, a number of red and grey dots also show that waiting and failed instances are not uncommon.

The sixth and final image is a relatively technical interrogation. MPKI is short for missed-predictions-per-thousand (k)-instructions. This industry metric refers to the ability of a processor to carry out branch prediction. To achieve optimal processing, this number should be as close to zero as possible, with no missed predictions. Visually, the color scheme here ranges from blue to pink, using a scale of 0 – 20 MPKI. Certainly the sea of blue in the image indicates very low misses and high processor performance. Yet the dappled pink dots interspersed throughout show that processing is not perfect, and up to 20 predictions per 1000 can be missed at times.

Alibaba’s vision was to increase efficiency through co-allocation. Efficiency here, as elsewhere, would entail a smooth, ceaseless productivity, where disruption of any kind would be avoided. In her book-length study on the history of efficiency, Jennifer Alexander defines the ideal of efficiency as a “a process fully understood and fully predictable, disrupted neither by unknown movements nor by particular or unique ones.”42 Depending on the industry, such disruptions may take the form of a mechanical failure, an unruly child, or an unforeseen natural disaster. These disruptions emerge from unwanted developments or unexpected catastrophes, from “externalities” that interrupt the seamless operations that are desired.
Perhaps one of the most striking dynamics observed in these images, then, is the way that work itself disrupts efficiency. Work on a data center cluster, as discussed earlier, takes the form of jobs and tasks. Certainly these can all be completed on the “universal machine” of the computer servers. Yet far from being homogenous, the visualizations above together demonstrate the highly heterogeneous nature of these jobs. Some require hours to calculate, others a few seconds. Some are computationally intensive, while others use a fraction of their allocated memory. Some must respond “in the moment” to customers; others are offline batches, free to run overnight. Alibaba attempts to allocate these jobs to the cluster, but these highly diverse forms of work essentially stretch the scheduler, they introduce resource conflicts, and they overwhelm its ability to efficiently orchestrate work.
Several papers examining the Alibaba dataset have recognized the disruption this work causes, even if they are framed in the more technical language of computer science. One of the first analyses argued that the co-allocation approach creates a number of fundamental imbalances across the cluster. “Such imbalances exacerbate the complexity and challenge of cloud resource management, which might incur severe wastes of resources and low cluster utilization.”43 After analyzing the cluster data, Ren and co-authors similarly concluded that: “Unavoidably, deploying multiple applications to share resources on the same node will cause contentions and performance tilt.”44 The mixture of two job types, as Jiang et al observe, results “in scheduling complexity and interferences among online services and batch jobs.”45 The divergence of these tasks introduces a degree of contingency into the system that cannot be anticipated nor managed. In doing so, these jobs frustrate the control necessary for optimal productivity. Work itself proves disruptive to efficiency.
Inhuman Efficiency
In data center rhetoric, there is a clear figure responsible for these inefficiencies—the human. The data center has become a highly complex environment, with countless tasks, each with their own demands, running across hundreds or even thousands of machines. Yet the prioritization and execution of jobs is still determined manually, for example via rulesets set out by the operator or on a case-by-case, cluster-by-cluster basis. Pundits have begun to deride this practice as antiquated or even artisanal. These are “hand-edited algorithm schedules”46 or a “hand-rolled container stack.”47 For critics, this traditional approach requires significant amounts of tedious work. This work cannot be carried out by anyone, but requires the expertise of a highly trained (and highly paid) individual. Clients need to be considered, job patterns understood, and underlying resources properly leveraged. As Mao et al acknowledge, “workload-specific scheduling policies that use this information require expert knowledge and significant effort to devise, implement, and validate.”48
While human labor is expensive and time-consuming, the larger problem for these commentators is that it is fundamentally ineffective. Human engineers cannot adequately grasp the complexities of the data center and the myriad variables around jobs, resources, and priorities. As one commentator observed: “Unfathomable permutations for humans in the manually edited scheduling can include the fact that a lower node (smaller computational task) can’t start work until an upper node (larger, more power-requiring computational task) has completed its work.”49 When humans undertake this work, they produce task schedules that are straightforward to understand but ultimately inefficient. Often based on observation and trial and error, they are “clever heuristics for a simplified model of the problem.”50 In following this schedule, computable resources lie underutilized even as they continue to drain power and require cooling.
A new array of automated solutions have begun to encroach on this space. In 2014, “Tetris” drew from a parallel problem of bin packing, “packing” jobs as tightly as possible and adaptively learning task requirements as it went.51 In 2016 “DeepRM” drew more specifically from machine learning techniques; after training it began holding back large jobs to make room for soon-to-arrive smaller jobs, a sophisticated strategy that was learned automatically.52 These precedents culminated in “Decima”, a neural net based approach that automatically learns how to optimally allocate workloads across thousands of servers.53 Echoing the human-as-problem rhetoric above, commentators noted how “Decima can find opportunities for [scheduling] optimization that are simply too onerous to realize via manual design/tuning processes.”54
For industry proponents, then, efficiency is an important problem best tackled by machines. Indeed, the shift to containerization suggests that these issues are not so much beyond humans as beneath them. While these problems are complex, they are also mundane and low-level, not worth attending to. In an interview, Hindman compares the advent of these virtual containers to the advent of virtual memory. Memory was once a scarce resource that was also allocated “by hand”, with programmers manually tracking where variables and datasets were stored. If this granted total control, it was also highly time-consuming and required meticulous attention to detail. Virtual memory not only abstracted away hardware memory, but allowed it to be pooled and managed automatically. In the same vein, data center operating systems and container managers abstract away servers and their low-level specifics. “Containers encapsulate the application environment” asserts Burns et al, “abstracting away many details of machines and operating systems from the application developer and the deployment infrastructure.”55 In this vision, developers and engineers should not have to worry about trivial details like individual machines and their hardware resources. Instead, compute should be flexible, automatically adapting to the requirements of any given task and efficiently carrying it out. As Hindman’s interviewer concluded: “People are going to have to get over their own ‘perceived’ expertise and let computers do stuff that they’re good at.”56
According to this imaginary, what humans “are good at” is strategizing, innovating, and creating. Not only are these tasks difficult to automate, but they are the kind of high-level cognitive labor that disrupts incumbents, invents services, and opens markets, generating more sustainable and profitable value. These technologies carry out a double move: designating efficiency as a low-level machinic problem frees up the human to concentrate on more “meaningful” and “productive” work. “It is for reasons of productivity that the cloud is designed to remove infrastructure from sight,” notes Hu, “so that its users can focus on higher-level applications—namely, more ‘useful’ jobs that lift users from the factory floor and toward the noble air of the knowledge economy.”57 In this sense, the technology sector dovetails neatly into a broader programme of neoliberal capitalism,58 where individuals are liberated from mundane labor in order to create more inspired and entrepreneurial forms of value.
Questioning Efficiency
Taken together, the data visualizations above demonstrate that—despite the best efforts of data center engineers over several years to schedule jobs and allocate resources in an optimal way—inefficiencies remain significant. Yet more fundamentally, we might ask why efficiency is the frame we are offered to understand these technical (but always also social and political) systems. What work does this frame do, what does it show and hide, and how might we question it?
On an immediate level, efficiency provides a powerful paradigm, establishing a problem, a goal, and a clear path forward. As Wajcman notes, efficiency slots into a broader framework “in which technical rationality both defines political problems and provides the solution.”59 Efficiency points out the “waste” of energy, the glut of time, the misuse of resources. If these are the issues, then the solution becomes equally concrete: become more efficient. Computer scientists and software engineers are good at efficiency. Current performance can be quantitatively tested, providing a baseline. Every possible optimization—newer hardware, innovations in software, advanced schedulers—can then be measured against this benchmark. Improvements are retained; unsuccessful experiments are discarded. The result is an incremental but steady advancement, a sense of verifiable progression. These gains can then be touted in trade journals or in the press releases of hyperscalers like Google, Amazon Web Services, or Alibaba itself.
One of the key strengths of efficiency is its flexibility. While Alibaba’s data center clusters are the focus here, the efficiency imperative might equally be applied to a supply chain, a civic initiative, or a public transport network. Efficiency is reflexive, hermetic even, positing an enclosed system and measuring itself by its own inputs and outputs. The general concept of efficiency, explains Jennifer Alexander, enabled “the assessment of almost any action or process on the basis of the same units and qualities it had started with and nothing else.”60 Efficiency always points back to itself, aiming to accomplish the same task faster, or with the use of less resources, or at vaster scales. In this sense, efficiency is content agnostic. It can serve as an envelope for any process, from any industry. Efficiency is an off-the-shelf vision, already embedded with values, milestones, and regimes of measurement, that can be applied to anything.
However if efficiency offers an enticing frame, it is also a particular one. In imposing a new, overarching set of values, efficiency suppresses alternative ways of understanding it. Alibaba never speaks about the specifics of their data center operations—the data being harvested, the capital being funneled, the personal information being onsold—but only observes that these processes could be more efficiently managed. In this sense, efficiency acts as a wrapper, shrouding original values and norms. As Feenberg notes, moral and ethical outcomes are “occluded rather than revealed by the application of technical norms.”61 Efficiency is an apolitical envelope that obscures the politics of systems and processes. Feenberg stresses that “considerations of efficiency are invoked to remove issues from normative judgment and public discussion.”62 Former qualms are rendered irrelevant; a new set of metrics for measuring success is introduced. Efficiency is strategic in foregrounding technical rationality while sidelining messier questions around labor and capital, inequality and sociality, privacy and the public good.
Indeed, one of the red threads running through social science critiques of efficiency is this idea that efficiency both highlights and obscures. Efficiency is a powerful conceptual frame, admits Lutzenhiser, but precisely because it “seems to illuminate the world so clearly… other aspects seem to disappear.”63 Efficiency makes sense of the world, yet simultaneously marginalizes other perspectives. Efficiency literature is dominated by narrowly focused “techno-economic approaches” that fail to account for its complex contexts and societal tradeoffs (Dunlop 2019). Because of this, many sociological critiques reiterate the same point: (energy) “efficiency tends to “obfuscate wider societal issues—specifically those concerning energy justice, environmental and philosophical concerns.” 64 As STS scholar Langdon Winner once asserted, to focus solely on efficiency is to miss “a decisive element in the story.”65
What does efficiency obscure? On an immediate level, it obscures the target of efficiency. What is being made more efficient, for whom, and to what end? In the data center industry as well as the broader technology sector, these questions are often never asked. It is axiomatic that PUE (power usage effectiveness) ratios should continue to drop, that new techniques for maximizing power and cooling should be welcomed, and that “better” schedulers and software should be embraced. Viewed through the framing of efficiency, the data center industry appears to be improving every year. Progress is being made. Yet again this view is highly insular, neglecting to consider the aims and intentions of these processes. What is being done is irrelevant; all that matters is that it is done faster and with less resources. It is efficiency stripped of any context—efficiency for efficiency’s sake.
Against this bracketed view, we can consider what these data infrastructures accomplish and what the sociopolitical impacts of these operations are. Without a doubt, the largest and fastest growing data center segment are the “hyperscale” companies mentioned earlier,66 tech giants such as Google, Amazon, Facebook, Apple, and Alibaba who either construct their own massive facilities or rent and manage floors of space from existing providers. These platforms and services are based upon an invasive and exploitative business model, where user data is harvested, assembled, packaged, and then sold onto third party advertisers.67 As Scholz argues, these entities “insert themselves between those who offer services and others who are looking for them, thereby embedding extractive processes into social interaction.”68 Alongside their consumer-facing services, companies like Google and Facebook have invested heavily in machine learning architectures, where data is mined in order to produce more invasive insights into consumers.69 These dynamics produce a highly asymmetric internet, where users offer up their personal data for access into the “walled gardens” offered by a handful of tech corporations. Underpinned by data center processes, these environments are “predicated upon an unprecedented intensification of extractive dynamics and related processes of dispossession.”70 With this in mind, making the data center more efficient equates to making these exploitative processes faster and less resource-intensive. It means “packing” this work in more sophisticated ways, allowing more work to be accomplished. In effect, it means an optimization of extraction.
Efficiency, then, is not an end to itself, but must be understood in relation to what is being made efficient. As Winner stressed, these technologies should be judged “not only for their contributions to efficiency and productivity and their positive and negative environmental side effects, but also for the ways in which they can embody specific forms of power and authority.”71 The capture of data, the extraction of social processes, and the funneling of capital carried out by hyperscale companies is problematic, if not pathological. In this sense, efficiency is neither apolitical nor objective, but rather deeply intertwined with the values, norms, and visions of those it services.
More broadly, efficiency aligns with capitalism and its imperative of productivity. There is a long lineage of criticism wary of efficiency and the exploitative potential of machinic regimes. Marx recognized the double-edged nature of efficiency—more efficient machines pressured the laborer to keep up, to maintain the pace and intensity of work. While output would be increased, the exploitation of the laborer and the toll on her body would also increase.72 For Ellul, individuals were subordinated to technical progress and its all consuming “calculus of efficiency.”73 Similarly for Ivan Illich, machines removed the creativity and autonomy necessary for fulfilling labor, enslaving men.74 For Wajcman, efficiency is a “dominant engineering approach” that attempts to save and order the time of social life.75 These critiques caution against efficiency, its economic logics and its obsession with productivity. They worry that human life will become diminished. Filtered through this starkly quantitative lens, the richness of human sociality, language, and labor will be reduced to a set of inputs and outputs. Popular literature has picked up these critiques in simplistic ways. To resist these stressful, destructive regimes, we need to waste time,76 learn to do nothing,77 and step back and slow down.78 Inefficiency should be embraced.
Yet if these concerns are understandable, they are also entrenched in a history of human-centered labor. How might Alibaba’s facility challenge these understandings? Can wasted machinic time really still be theorized through Taylorism? Can an “idle” machine still be understood through a Weberian critique of work-ethic? The Alibaba compute cluster is a pool of machines where jobs are assigned and completed, manipulating, transforming, and processing data, until each task is complete. While engineers may function at the edges of this regime, checking services and maintaining hardware, this labor is decidedly machine-centered rather than human-centered.
Indeed, one of the clear pushes of the data center industry is to more comprehensively automate these facilities. Systems should carry out predictive maintenance and algorithms should automatically control cooling, forming an auto-healing, auto-optimized environment.79 These initiatives move towards the seductive vision of the “lights out” data center.80 In this dream, on-site staff, even now typically just a handful of workers, will no be longer necessary. Server maintenance can be automated or completed remotely. The vestigial human and the concession to her vision can finally be jettisoned. Operations run smoothly and incessantly in the dark.
Of course, this is not to claim that a machine-centric shift resolves the issue of efficiency. Critique is still necessary, and as the data center and its role proliferates, attending to the processes at the heart of these environments, as noted above, will become even more urgent. It is simply to note that the question of efficiency in this machinic realm feels like a different kind of question. Here, theorizations based on 19th and 20th human-centric labor regimes begin to fray at the edges. Arguments based heavily on efficiency impinging human creativity and autonomy start to unravel. What is needed is a critical media theory grounded in a rich lineage of social theory, yet also aware of the promising possibilities ushered in by these technical architectures and operations.
Conclusion
Visualizing Alibaba’s cluster dataset provides insight into the operations and contradictions at the heart of the data center. Data center efficiency, centering around machine utilization rates, has long been an acknowledged problem in the industry. Alibaba’s vision of co-allocation aimed to address this issue by combining online and offline jobs. However, as the data visualizations demonstrated, this move introduces new forms of complexity. Jobs are highly heterogeneous in their durations and demands, creating difficulties in scheduling and conflicts in allocation. Work itself proves to be a disruption to efficiency. For the industry, this complexity confirms that efficiency is an issue for machines, driving automated schedulers and new layers of abstraction that allow operators to devote themselves to more productive and “high impact” labor. After exploring these dynamics, the article questioned the framing of efficiency itself. While efficiency can be justified on an economic and environmental level, its merit is often assumed. Efficiency introduces a particular framing, defining a problem, establishing a goal, and offering a compelling road map to achieving it. Yet if efficiency is clarifying, it is also obfuscating, bracketing out alternative ways of understanding these sociotechnical systems. As hyperscale companies dominate data centers, what is being made efficient are operations that are often exploitative and invasive. Efficiency, then, should certainly be critiqued and questioned. Yet to merely valorize inefficiency is to all-too-quickly fall back on comfortable tropes. As the data center grows in significance while de-centering human labor, it becomes important to develop a critical theorization of efficiency attuned to the new conditions of this machine-centric future.
Funding
This work was undertaken as part of “Data Centres and the Governance of Labour and Territory,” a Discovery Project funded by the Australian Research Council (DP160103307).
References
Alexander, Jennifer Karns. 2008. The Mantra of Efficiency: From Waterwheel to Social Control. Baltimore: Johns Hopkins University Press.
Alibaba. (2017) 2019. Alibaba/Clusterdata. Alibaba. https://github.com/alibaba/clusterdata.
Alibaba Developer. 2019. “Alibaba Cluster Data: Using 270 GB of Open Source Data to Understand Alibaba Data Centers.” Alibaba Cloud Community. January 7, 2019. https://www.alibabacloud.com/blog/alibaba-cluster-data-using-270-gb-of-open-source-data-to-understand-alibaba-data-centers_594340.
Andrae, Anders S. G., and Tomas Edler. 2015. “On Global Electricity Usage of Communication Technology: Trends to 2030.” Challenges 6 (1): 117–57. https://doi.org/10.3390/challe6010117.
Boltanski, Luc, and Eve Chiapello. 2017. The New Spirit of Capitalism. Translated by Gregory Elliot. London: Verso. https://www.versobooks.com/books/2513-the-new-spirit-of-capitalism.
Burns, Brendan, Brian Grant, David Oppenheimer, Eric Brewer, and John Wilkes. 2016. “Borg, Omega, and Kubernetes.” Queue 14 (1): 70–93.
Carlini, Steven. 2020. “Why Every Data Center in the Future Will Be ‘Lights Out.’” Schneider Electric Blog. June 22, 2020. https://blog.se.com/datacenter/2020/06/22/why-every-data-center-in-the-future-will-be-lights-out/.
Cheng, Yue, Ali Anwar, and Xuejing Duan. 2018. “Analyzing Alibaba’s Co-Located Datacenter Workloads.” In 2018 IEEE International Conference on Big Data (Big Data), 292–97. Seattle, WA, USA: IEEE. https://doi.org/10.1109/BigData.2018.8622518.
Daggett, Cara New. 2019. The Birth of Energy: Fossil Fuels, Thermodynamics, and the Politics of Work. Elements. Durham: Duke University Press.
Davis, Charles R. 1985. “A Critique of the Ideology of Efficiency.” Humboldt Journal of Social Relations 12 (2): 73–86.
Delforge, Pierre. 2015. “America’s Data Centers Consuming and Wasting Growing Amounts of Energy.” NRDC. February 6, 2015. https://www.nrdc.org/resources/americas-data-centers-consuming-and-wasting-growing-amounts-energy.
Donoghue, Andrew. 2017. “Beyond Lights-Out: Future Data Centers Will Be Human-Free.” Data Center Knowledge. September 19, 2017. https://www.datacenterknowledge.com/design/beyond-lights-out-future-data-centers-will-be-human-free.
Dunlop, Tessa. 2019. “Mind the Gap: A Social Sciences Review of Energy Efficiency.” Energy Research & Social Science 56 (October): 1–12. https://doi.org/10.1016/j.erss.2019.05.026.
Ellul, Jacques. 1964. The Technological Society. New York: Vintage.
Fano, R. M., and F. J. Corbató. 1966. “Time-Sharing on Computers.” Scientific American 215 (3): 128–43.
Feenberg, Andrew. 1996. “Marcuse or Habermas: Two Critiques of Technology.” Inquiry 39 (1): 45–70. https://doi.org/10.1080/00201749608602407.
Flucker, Sophia, Robert Tozer, and Beth Whitehead. 2018. “Data Centre Sustainability – Beyond Energy Efficiency.” Building Services Engineering Research and Technology 39 (2): 173–82. https://doi.org/10.1177/0143624417753022.
Fuchs, Christian. 2014. Digital Labour and Karl Marx. London: Routledge.
Fulton, Scott. 2017. “One Year In, Has DC/OS Changed the Data Center?” Data Center Knowledge. April 24, 2017. https://www.datacenterknowledge.com/archives/2017/04/24/one-year-dcos-changed-data-center.
———. 2019. “What Is Kubernetes? How Orchestration Redefines the Data Center.” ZDNet. April 25, 2019. https://www.zdnet.com/article/what-kubernetes-really-is-and-how-orchestration-redefines-the-data-center/.
Garber, Kent. 2009. “The Internet’s Hidden Energy Hogs: Data Servers.” US News & World Report, March 24, 2009. https://www.usnews.com/news/energy/articles/2009/03/24/the-internets-hidden-energy-hogs-data-servers.
Glanz, James. 2012. “Data Centers Waste Vast Amounts of Energy, Belying Industry Image.” The New York Times, September 22, 2012. http://www.nytimes.com/2012/09/23/technology/data-centers-waste-vast-amounts-of-energy-belying-industry-image.html.
Grandl, Robert, Ganesh Ananthanarayanan, Srikanth Kandula, Sriram Rao, and Aditya Akella. 2014. “Multi-Resource Packing for Cluster Schedulers.” In Proceedings of the 2014 ACM Conference on SIGCOMM – SIGCOMM ’14, 455–66. Chicago, Illinois, USA: ACM Press. https://doi.org/10.1145/2619239.2626334.
Hatzenbuehler, Anthony. 2018. “The Importance of Uptime and All Those Nines.” CoreSite. March 5, 2018. https://www.coresite.com/blog/the-importance-of-uptime-and-all-those-nines.
Hindman, Benjamin. 2014. “Why the Data Center Needs an Operating System.” O’Reilly Media. December 3, 2014. https://www.oreilly.com/ideas/why-the-data-center-needs-an-operating-system.
Hindman, with Benjamin. 2015. a16z Podcast: The Datacenter Needs an Operating System Interview by Steven Sinofsky. https://a16z.com/2015/01/05/a16z-podcast-why-the-datacenter-needs-an-operating-system/.
Hoelzle, Urs, and Luiz Andre Barroso. 2009. The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines. San Rafael, CA: Morgan and Claypool Publishers.
Holt, Jennifer, and Patrick Vonderau. 2015. “‘Where the Internet Lives’: Data Centers as Cloud Infrastructure.” In Signal Traffic: Critical Studies of Media Infrastructures, edited by Lisa Parks and Nicole Starosielski, 175–229. Chicago: University of Illinois Press.
Hu, Tung-Hui. 2015. A Prehistory of the Cloud. Cambridge, MA: MIT Press.
Illich, Ivan. 1973. Tools for Conviviality. New York: Harper and Row.
Jaureguialzo, Enrique. 2011. “PUE: The Green Grid Metric for Evaluating the Energy Efficiency in DC (Data Center). Measurement Method Using the Power Demand.” In 2011 IEEE 33rd International Telecommunications Energy Conference, 1–8. https://doi.org/10.1109/INTLEC.2011.6099718.
Jiang, Congfeng, Guangjie Han, Jiangbin Lin, Gangyong Jia, Weisong Shi, and Jian Wan. 2019. “Characteristics of Co-Allocated Online Services and Batch Jobs in Internet Data Centers: A Case Study From Alibaba Cloud.” IEEE Access 7: 22495–508. https://doi.org/10.1109/ACCESS.2019.2897898.
Jonat, Rachel. 2017. The Joy of Doing Nothing: A Real-Life Guide to Stepping Back, Slowing Down, and Creating a Simpler, Joy-Filled Life. New York: Adams Media.
Jörgenson, Loki, BC Ronald Kriz, Virgina Tech, and Barbara Mones-Hattal. 1995. “Is Visualization Struggling under the Myth of Objectivity?”
Judge, Peter. 2019. “How Webscale Is Swallowing Colo.” Data Center Dynamics. May 17, 2019. https://www.datacenterdynamics.com/analysis/how-webscale-swallowing-colo/.
Kanev, Svilen, Juan Pablo Darago, Kim Hazelwood, Parthasarathy Ranganathan, Tipp Moseley, Gu-Yeon Wei, and David Brooks. 2015. “Profiling a Warehouse-Scale Computer.” In Proceedings of the 42nd Annual International Symposium on Computer Architecture – ISCA ’15, 158–69. Portland, Oregon: ACM Press. https://doi.org/10.1145/2749469.2750392.
Keim, Daniel, Huamin Qu, and Kwan-Liu Ma. 2013. “Big-Data Visualization.” IEEE Computer Graphics and Applications 33 (4): 20–21.
Kosara, Robert. 2008. “The Unbearable Subjectivity of Visualization.” Eagereyes. January 17, 2008. https://eagereyes.org/blog/2008/subjectivity-of-visualization.
Lightman, Alan. 2018. In Praise of Wasting Time. New York: Simon & Schuster/ TED.
Liu, Huan. 2011. “A Measurement Study of Server Utilization in Public Clouds.” In , 435–42. IEEE.
Loftus, Jack. 2005. “Xen Virtualization Quickly Becoming Open Source ‘Killer App.’” SearchDataCenter. December 19, 2005. https://searchdatacenter.techtarget.com/news/1153127/Xen-virtualization-quickly-becoming-open-source-killer-app.
Lu, Chengzhi, Kejiang Ye, Guoyao Xu, Cheng-Zhong Xu, and Tongxin Bai. 2017. “Imbalance in the Cloud: An Analysis on Alibaba Cluster Trace.” In 2017 IEEE International Conference on Big Data, 2884–92. Boston, MA: IEEE. https://doi.org/10.1109/BigData.2017.8258257.
Lutzenhiser, Loren. 2014. “Through the Energy Efficiency Looking Glass.” Energy Research & Social Science 1 (March): 141–51. https://doi.org/10.1016/j.erss.2014.03.011.
Mao, Hongzi, Mohammad Alizadeh, Ishai Menache, and Srikanth Kandula. 2016. “Resource Management with Deep Reinforcement Learning.” In Proceedings of the 15th ACM Workshop on Hot Topics in Networks – HotNets ’16, 50–56. Atlanta, GA, USA: ACM Press. https://doi.org/10.1145/3005745.3005750.
Mao, Hongzi, Malte Schwarzkopf, Shaileshh Bojja Venkatakrishnan, Zili Meng, and Mohammad Alizadeh. 2019. “Learning Scheduling Algorithms for Data Processing Clusters.” In Proceedings of the ACM Special Interest Group on Data Communication – SIGCOMM ’19, 270–88. Beijing, China: ACM Press. https://doi.org/10.1145/3341302.3342080.
Marshall, David, Stephen S. Beaver, and Jason W. McCarty. 2008. VMware ESX Essentials in the Virtual Data Center. Boca Raton, FL: CRC Press.
Marwah, Manish, Bruno Silva, Sérgio Galdino, Jose Pires, Paulo Maciel, Amip Shah, Ratnesh Sharma, et al. 2010. “Quantifying the Sustainability Impact of Data Center Availability.” ACM SIGMETRICS Performance Evaluation Review 37 (4): 64. https://doi.org/10.1145/1773394.1773405.
Marx, Karl. 2004. Capital: A Critique of Political Economy. Translated by Ben Fowkes. London: Penguin Books.
Matheson, Rob. 2019. “Artificial Intelligence Could Help Data Centers Run Far More Efficiently.” MIT News. August 21, 2019. http://news.mit.edu/2019/decima-data-processing-0821.
Metz, Cade. 2016. “Google, Facebook, and Microsoft Are Remaking Themselves Around AI.” Wired, November 21, 2016. https://www.wired.com/2016/11/google-facebook-microsoft-remaking-around-ai/.
Mezzadra, Sandro, and Brett Neilson. 2017. “On the Multiple Frontiers of Extraction: Excavating Contemporary Capitalism.” Cultural Studies 31 (2–3): 185–204. https://doi.org/10.1080/09502386.2017.1303425.
Miller, Rich. 2019a. “What’s Next for AI in Data Center Automation?” Data Center Frontier (blog). March 20, 2019. https://datacenterfrontier.com/whats-next-for-ai-in-data-center-automation/.
———. 2019b. “Hyperscale Data Centers.” New Jersey: Data Center Frontier. https://datacenterfrontier.com/wp-content/uploads/2019/09/DCF-Special-Report-Hyperscale-Data-Centers.pdf.
Morozov, Evgeny. 2014. “Selling Your Bulk Online Data Really Means Selling Your Autonomy.” The New Republic, May 14, 2014. https://newrepublic.com/article/117703/selling-personal-data-big-techs-war-meaning-life.
Nelson, Patrick. 2019. “Data Center-Specific AI Completes Tasks Twice as Fast.” Network World. August 29, 2019. https://www.networkworld.com/article/3434597/data-center-specific-ai-completes-tasks-twice-as-fast.html.
Niccolai, James. 2013. “New Data Center Survey Shows Mediocre Results for Energy Efficiency.” Computerworld. April 12, 2013. https://www.computerworld.com/article/2496597/new-data-center-survey-shows-mediocre-results-for-energy-efficiency.html.
Odell, Jenny. 2019. How to Do Nothing: Resisting the Attention Economy. Brooklyn, NY: Melville House.
Pasquinelli, Matteo. 2009. “Google’s PageRank Algorithm: A Diagram of Cognitive Capitalism and the Rentier of the Common Intellect.” Deep Search: The Politics of Search beyond Google, 152–62.
Pinch, Trevor J. 1992. “Opening Black Boxes: Science, Technology and Society.” Social Studies of Science 22 (3): 487–510. https://doi.org/10.1177/0306312792022003003.
Ren, Rui, Jinheng Li, Lei Wang, Jianfeng Zhan, and Zheng Cao. 2018. “Anomaly Analysis for Co-Located Datacenter Workloads in the Alibaba Cluster.” ArXiv:1811.06901 [Cs], November. http://arxiv.org/abs/1811.06901.
Riley, Judith Merkle. 1980. Management and Ideology: The Legacy of the International Scientific Management Movement. Berkeley: University of California Press.
Rossiter, Ned. 2017. Software, Infrastructure, Labor: A Media Theory of Logistical Nightmares. New York: Routledge.
Ruppert, Evelyn, Engin Isin, and Didier Bigo. 2017. “Data Politics.” Big Data & Society 4 (2): 1–7.
Scholz, Trebor. 2016. “Platform Cooperativism.” New York: Rosa Luxemburg Foundation. http://www.rosalux-nyc.org/wp-content/files_mf/scholz_platformcoop_5.9.2016.pdf.
Srnicek, Nick. 2017. Platform Capitalism. Cambridge, UK: Polity Press.
Talaber, Richard, Tom Brey, and Larry Lamers. 2009. “Using Virtualization to Improve Data Center Efficiency.” Washington, D.C.: The Green Grid.
Townend, Paul, Stephen Clement, Dan Burdett, Renyu Yang, Joe Shaw, Brad Slater, and Jie Xu. 2019. “Invited Paper: Improving Data Center Efficiency Through Holistic Scheduling In Kubernetes.” In 2019 IEEE International Conference on Service-Oriented System Engineering (SOSE), 156–161. San Francisco East Bay, CA, USA: IEEE. https://doi.org/10.1109/SOSE.2019.00030.
Uddin, Mueen, Jamshed Memon, Mohd Zaidi, Mohd Zaidi Abd Rozan, and Amjad Rehman. 2015. “Virtualised Load Management Algorithm to Reduce CO2 Emissions in the Data Centre Industry.” International Journal of Global Warming 7 (January): 3–20. https://doi.org/10.1504/IJGW.2015.067413.
Uptime Institute. 2018. “Tier Classification System.” May 21, 2018. https://uptimeinstitute.com/tiers.
Van Kessel, Jeroen. 2016. “Power Efficiency of Hypervisor-Based Virtualizationversus Container-Based Virtualization.” Amsterdam: University of Amsterdam. https://www.delaat.net/rp/2015-2016/p33/report.pdf.
Veel, Kristen. 2017. “Uncertain Architectures: Performing Shelter and Exposure.” Imaginations 8 (2). http://imaginations.glendon.yorku.ca/?p=9956.
Verma, Abhishek, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, and John Wilkes. 2015. “Large-Scale Cluster Management at Google with Borg.” In Proceedings of the Tenth European Conference on Computer Systems, 1–17. EuroSys ’15. Bordeaux, France: Association for Computing Machinery. https://doi.org/10.1145/2741948.2741964.
Wajcman, Judy. 2015. Pressed for Time: The Acceleration of Life in Digital Capitalism. Chicago: University of Chicago Press.
Wallen, Jack. 2019. “8 Data Center Predictions for 2020.” TechRepublic. December 15, 2019. https://www.techrepublic.com/article/8-data-center-predictions-for-2020/.
Walsh, Bryan. 2013. “The Surprisingly Large Energy Footprint of the Digital Economy.” TIME, August 14, 2013. https://science.time.com/2013/08/14/power-drain-the-digital-cloud-is-using-more-energy-than-you-think/.
Weber, Max. 2012. The Protestant Ethic and the Spirit of Capitalism. London: Routledge.
Wells, Sarah. 2018. “The Challenges of Migrating 150+ Microservices to Kubernetes.” Presented at the Kubecon, Copenhagen, May 2. https://www.youtube.com/watch?v=H06qrNmGqyE.
Winner, Langdon. 1980. “Do Artifacts Have Politics?” Daedalus 109 (1): 121–36.
Yuventi, Jumie, and Roshan Mehdizadeh. 2013. “A Critical Analysis of Power Usage Effectiveness and Its Use in Communicating Data Center Energy Consumption.” Energy and Buildings 64 (September): 90–94. https://doi.org/10.1016/j.enbuild.2013.04.015.
Zaharia, Matei, Benjamin Hindman, Andy Konwinski, Ali Ghodsi, Anthony D. Joesph, Randy Katz, Scott Shenker, and Ion Stoica. 2011. “The Datacenter Needs an Operating System.” In Proceedings of the 3rd USENIX Conference on Hot Topics in Cloud Computing, 17. HotCloud’11. Portland, OR: USENIX Association.
Zoellick, Jan Cornelius, and Arpita Bisht. 2018. “It’s Not (All) about Efficiency: Powering and Organizing Technology from a Degrowth Perspective.” Journal of Cleaner Production, Technology and Degrowth, 197 (October): 1787–99. https://doi.org/10.1016/j.jclepro.2017.03.234.
Notes
- Holt and Vonderau, “‘Where the Internet Lives’: Data Centers as Cloud Infrastructure.” ↩
- Ruppert, Isin, and Bigo, “Data Politics.” ↩
- Veel, “Uncertain Architectures.”; Pinch, “Opening Black Boxes.” ↩
- Alibaba, Alibaba/Clusterdata. ↩
- Alibaba Developer, “Alibaba Cluster Data.” ↩
- Lu et al., “Imbalance in the Cloud.”; Cheng, Anwar, and Duan, “Analyzing Alibaba’s Co-Located Datacenter Workloads.”; Jiang et al., “Characteristics of Co-Allocated Online Services and Batch Jobs in Internet Data Centers.”; and others ↩
- Ren et al., “Anomaly Analysis for Co-Located Datacenter Workloads in the Alibaba Cluster,” 2. ↩
- Jörgenson et al., “Is Visualization Struggling under the Myth of Objectivity?” ↩
- Kosara, “The Unbearable Subjectivity of Visualization.” ↩
- Keim, Qu, and Ma, “Big-Data Visualization.” ↩
- Rossiter, Software, Infrastructure, Labor: A Media Theory of Logistical Nightmares, Ruppert, Isin, and Bigo, “Data Politics.” ↩
- Andrae and Edler, “On Global Electricity Usage of Communication Technology.” ↩
- Marwah et al., “Quantifying the Sustainability Impact of Data Center Availability.” ↩
- Uddin et al., “Virtualised Load Management Algorithm to Reduce CO2 Emissions in the Data Centre Industry.” ↩
- Hatzenbuehler, “The Importance of Uptime and All Those Nines.” ↩
- Uptime Institute, “Tier Classification System.” ↩
- Glanz, “Data Centers Waste Vast Amounts of Energy.” ↩
- Fano and Corbató, “Time-Sharing on Computers.” ↩
- Hu, A Prehistory of the Cloud, 62. ↩
- Marshall, Beaver, and McCarty, VMware ESX Essentials in the Virtual Data Center. ↩
- Loftus, “Xen Virtualization Quickly Becoming Open Source ‘Killer App.’” ↩
- Talaber, Brey, and Lamers, “Using Virtualization to Improve Data Center Efficiency.” ↩
- Hoelzle and Barroso, The Datacenter as a Computer, 108. ↩
- Liu, “A Measurement Study of Server Utilization in Public Clouds.” ↩
- Lu et al., “Imbalance in the Cloud.” ↩
- Hoelzle and Barroso, The Datacenter as a Computer, 108. ↩
- Garber, “The Internet’s Hidden Energy Hogs.” ↩
- Glanz, “Data Centers Waste Vast Amounts of Energy.” ↩
- Walsh, “The Surprisingly Large Energy Footprint of the Digital Economy.” ↩
- Hindman, “Why the Data Center Needs an Operating System.” The same phrase—“The Datacenter Needs an Operating System”—actually appears in an earlier 2011 conference paper by Zaharia and Hindman, along with several co-authors. Matei Zaharia et al., “The Datacenter Needs an Operating System,” in Proceedings of the 3rd USENIX Conference on Hot Topics in Cloud Computing, HotCloud’11 (Portland, OR: USENIX Association, 2011), 17. ↩
- Fulton, “One Year In, Has DC/OS Changed the Data Center?” ↩
- Fulton, “What Is Kubernetes?” ↩
- Van Kessel, “Power Efficiency of Hypervisor-Based Virtualizationversus Container-Based Virtualization.” ↩
- Verma et al., “Large-Scale Cluster Management at Google with Borg.”; Burns et al., “Borg, Omega, and Kubernetes.” ↩
- Sometimes also referred to as co-location, though this term is far more commonly used to describe renting space in a datacenter alongside other clients. ↩
- Alibaba Developer, “Alibaba Cluster Data.” ↩
- Judge, “How Webscale Is Swallowing Colo.” ↩
- Lu et al., “Imbalance in the Cloud.” ↩
- Lu et al., “Imbalance in the Cloud,” 2802. ↩
- Lu et al., “Imbalance in the Cloud,” 2802. ↩
- Lu et al., “Imbalance in the Cloud,” 2802. ↩
- Alexander, The Mantra of Efficiency, 163. ↩
- Lu et al., “Imbalance in the Cloud.” ↩
- Ren et al., “Anomaly Analysis for Co-Located Datacenter Workloads in the Alibaba Cluster.” ↩
- Jiang et al., “Characteristics of Co-Allocated Online Services and Batch Jobs in Internet Data Centers.” ↩
- Nelson, “Data Center-Specific AI Completes Tasks Twice as Fast.” ↩
- Wells, “The Challenges of Migrating 150+ Microservices to Kubernetes.” ↩
- Mao et al., “Learning Scheduling Algorithms for Data Processing Clusters.” ↩
- Nelson, “Data Center-Specific AI Completes Tasks Twice as Fast.” ↩
- Mao et al., “Resource Management with Deep Reinforcement Learning.” ↩
- Grandl et al., “Multi-Resource Packing for Cluster Schedulers.” ↩
- Mao et al., “Resource Management with Deep Reinforcement Learning,” 55. ↩
- Mao et al., “Learning Scheduling Algorithms for Data Processing Clusters.”; see also Matheson, “Artificial Intelligence Could Help Data Centers Run Far More Efficiently.” ↩
- Nelson, “Data Center-Specific AI Completes Tasks Twice as Fast.” ↩
- Burns et al., “Borg, Omega, and Kubernetes.” ↩
- Hindman, a16z Podcast. ↩
- Hu, A Prehistory of the Cloud, 62. ↩
- Boltanski and Chiapello, The New Spirit of Capitalism. ↩
- Wajcman, Pressed for Time: The Acceleration of Life in Digital Capitalism, 178. ↩
- Alexander, The Mantra of Efficiency, 165. ↩
- Feenberg, “Marcuse or Habermas,” 53. ↩
- Feenberg, “Marcuse or Habermas,” 54. ↩
- Lutzenhiser, “Through the Energy Efficiency Looking Glass,” 143. ↩
- Dunlop, “Mind the Gap,” 8. ↩
- Winner, “Do Artifacts Have Politics?,” 256. ↩
- Miller, “Hyperscale Data Centers.” ↩
- Pasquinelli, “Google’s PageRank Algorithm: A Diagram of Cognitive Capitalism and the Rentier of the Common Intellect.”; Fuchs, Digital Labour and Karl Marx; Morozov, “Selling Your Bulk Online Data Really Means Selling Your Autonomy.”; Srnicek, Platform Capitalism. ↩
- Scholz, “Platform Cooperativism.” ↩
- Metz, “Google, Facebook, and Microsoft Are Remaking Themselves Around AI.” ↩
- Mezzadra and Neilson, “On the Multiple Frontiers of Extraction.” ↩
- Winner, “Do Artifacts Have Politics?,” 121. ↩
- Marx, Capital: A Critique of Political Economy, 829-830. ↩
- Ellul, The Technological Society, 188. ↩
- Illich, Tools for Conviviality, 10-11. ↩
- Wajcman, Pressed for Time: The Acceleration of Life in Digital Capitalism, 162. For a survey of similar critiques, see Zoellich and Bisht 2018. ↩
- Lightman, In Praise of Wasting Time. ↩
- Odell, How to Do Nothing. ↩
- Jonat, The Joy of Doing Nothing. ↩
- Miller, “What’s Next for AI in Data Center Automation?” ↩
- Donoghue, “Beyond Lights-Out.”; Carlini, “Why Every Data Center in the Future Will Be ‘Lights Out.’” ↩