© 2023 The Authors.
Published by Computational Culture under the terms of the Creative Commons Attribution License http://creativecommons.org/licenses/by-nc/4.0/, which permits non-commercial use, provided the original author and source are credited.
1. Introduction
Network science emerges as a term in the late nineteen-nineties and consists of a series of ‘content agnostic’ ways to analyse structures of various kinds as networks or graphs 1. It can be understood as a revival of the much older social network analysis through the influence of physics. 2 The kind of things network scientists work on range from the structure of proteins, to relations between social media posts, to chains of influence in academic research. Tools and approaches from network science are also often drawn into other fields, to show connections amongst entities as diverse as members of the ruling class or of criminal trading networks—as developed for instance in the meticulous work of artist Mark Lombardi 3—or to construct a taxonomic characterisation of the intestinal microbiota involved in gout. 4 Work in the field and in the applications of its tools seems to suggest the possibility of finding shared ‘hidden laws’ amongst often very different kinds of formations.
By the present day, the working vernacular of network visualisations has become a familiar part of contemporary culture. For instance, Figure 1 and Figure 2 below typify such images. They are composed of two types of entity, edges or connecting lines and vertices or dots where two or more lines meet. But what is meant by these patterns of dots and lines? In network science, the notion of ‘community’ was coined to grapple with these patterns 5 and ‘community detection algorithms’ such as the ‘Louvain algorithm’ are used today to discriminate such patterns in large networks with millions of nodes and edges. 6 In particular, community detection algorithms can be interpreted as methods for unsupervised machine learning that are supposed to find patterns in data without a given ground truth. 7 To delve into these patterns requires asking questions of their meaning: what do they stand in for, what do they signify, and what do they create? Further, what are the ways in which these arrangements of dots and lines, and the calculations that produce them, have potential cultural and political effects? To address this means recognising these patterns as a visual articulation of mathematical relationships. In order to hold these two aspects together, recognising their mutual inherence and differentiation, their particular and conjoint epistemic dimensions need to be addressed. One of the ways to do this is by understanding the way in which the notion of community provides in itself something of a conceptual vertex between different modes of analysis and understanding.
Since social media have incorporated the form of the graph, without, oddly enough, giving users actual sight of it, social networks have become part of the everyday furniture of social relations, given for instance in the brute facticity of artifacts like the following to follower ratios on Twitter, the commonplace of ‘virality’ 8 and the social role of the influencer, a social function that is in some ways predicated upon the operation of graphs. Such graphs play numerous roles.
We move from a society understood, from some disciplinary or technical perspectives, to be composed of individuals in networks that can be analysed by means of reserved or neutral observation to a society of analysis whose givens are networks in which power operations are implemented. In this set-up it should be of scant surprise that the word community appears as capable of interpreting many kinds of phenomena at the exact point in time when, if it has not entirely vanished, community, in its hitherto understood senses—in the social—seems often to have been mechanised, and often by the very means that redescribe it in more generalisable terms. In this condition, it is perhaps rather wince-inducing to rifle through the techniques of network analysis to try, not only to understand them, but to evaluate the conditions in which they might be worked. Nevertheless, there is something fascinating here, and one of the ways of understanding the way these techniques not only address but compose the present is by delving into them.
In this article, we aim to analyse the nature of what figures in network science as a community, trace the historical lineages of community detection algorithms and examine a specific case study of an algorithm for community detection and the notion of community it addresses. We introduce the notion of the ‘vague operator’, a specific kind of boundary object, to describe the various kinds of interplay between the hyper-precise and the vague that are embodied in the conjuncture of community and community detection algorithms. We then look into the broader standing of heuristics in relation to algorithmic practices and suggest a ‘critical’ heuristics attuned to the epistemic politics of ‘vague operators’.
2. Community / Detection
2.1 Lineages of Community Detection Algorithms
Mathematical practices are interwoven with their historical and technological gestation, but are rarely reducible to them. Computation in turn has changed mathematical ideas and modes of calculation in multiple ways. 9 The uptake of graph theory for network science purposes coincides with the increased availability of network datasets during the 1990s development of computer networks and the internet 10—which in some ways become both its metaphor and locus of veridiction, the space where it became true as something natively artificial. To say this is not to claim that mathematics is simply on the receiving end of history, nor of technical histories. Mathematics, as a means of thinking that has great capacity of abstraction also contains some possibility of thinking outside of historical constraints, of over-leaping them, and in this way may also act as one of their determinants.
Whilst we can take the above considerations into account, the focus of our paper lies on the mathematical practices that have shaped the central concept of community in network science. A genealogy of community detection needs to disentangle different lineages that have roots in other techniques (not named after community) and run in parallel across disciplines, mostly the social sciences and statistical physics. We can only approximate these lineages due to the enormous amount of publications involved and so present one narrative only, one that is influenced by discussions with different practitioners in network science. A certain amount of reticence is therefore present in this account as we map an initial development in the social sciences and a subsequent, and initially separate, one developed in statistical physics.
In sociology, social network analysis has a twentieth century history, admirably given by Katja Mayer in a 2009 article that traces its links to search engine technologies. 11 Mayer argues that social network analysis or sociometry developed alongside related techniques such as citation analysis, formulated as means for measuring authority and participation in academic publishing, techniques that soon became extended as a measure for centrality, opportunities for ‘self-realisation’, cultural significance and optimisation amongst other factors. This phenomena is also perceptively described by Bernhard Rieder in his account of the genealogy of PageRank. 12 Aside from this thread of work, the development of methods for what is today called ‘community detection’ has a longer tradition under different names such as ‘network partitioning’ or ‘clustering’. 13 One important predecessor from social network analysis is the mathematically simpler concept of a graph ‘clique’, 14 defined as a set of nodes of which each pair of nodes is connected in the graph. This concept was used by Duncan Luce and Albert Perry in 1949 to algorithmically obtain group structures from experimental data about human interactions, arguing “that a set of more than two people form a clique if they are all mutual friends of one another”. 15 Although their matrix-based approach was less prone to errors than a cumbersome manual investigation of the data, the mathematical definition of a clique is often too restrictive in applications. Hence, later concepts in the different lineages of ‘community’ can often be understood as weaker or looser versions of cliques that allow for sparser relations within groups.
In a review of community detection algorithms, Fortunato traces the origins of community detection back to a 1955 paper in sociometry by Robert Weiss and Eugene Jacobson, who proposed a method to deduce working groups from a matrix of work relationships in a complex government agency. 16 Their method of finding groups by reorganizing the matrix representation of a graph (see Section 2.3 for a definition of the ‘adjacency matrix’ of a graph) corresponding to a sociogram was first introduced by Elaine Forsyth and Leo Katz in 1946 who in turn developed the famous sociometric approach to groups introduced by Jacob Moreno in the 1930s. 17
We can also trace origins of community detection in psychology and anthropology. In a 1956 paper in psychology, Dorwin Cartwright and Frank Harary used graph theory to introduce the concept of structural balance to describe “configurations of many different sorts, such as communication networks, power systems, sociometric structures, systems of orientations, or perhaps neural networks”. 18 The image of the later broad applicability of the techniques concerned can be glimpsed here. Harary, who was a mathematician at the University of Michigan, was interested in the translation of social science concepts into graph theory and later also worked on applications in anthropology, where he developed clustering methods for signed graphs to study homophily. 19
Yet another thread of the lineage is formed by the use of what are called ‘stochastic block models’ that find their origins in the social science literature from the 1970s. For a review of this very wide field see an overview by Lee and Wilkinson. 20 In general, stochastic block models provide notions of ‘structural equivalence’ in graphs where the ‘role’ of a node is determined by its link structure. Deterministic models were first introduced by a group of sociologists around Ronald Breiger in 1975 21and stochastic models by Paul Holland et al. in 1983. 22
A common feature of the techniques developed in the social sciences described above is their shared goal of determining structurally similar nodes in graphs to identify individuals in social networks playing similar roles. However, we want to emphasise that social scientists from the different lineages described above did not use the term ‘community’. Other terms like ‘cohesive subgroups’ 23 or ‘balance and clustering phenomena’ 24 were used instead, each meaning different things. Moreover, a limiting factor for the development of community detection algorithms in the social sciences was the absence of computational power in the early years of social network analysis, where algorithms had to be performed manually in a cumbersome process.
As social network forms become significant in how people understand society, Mayer argues that they effectively become “behavioural instructions” 25. It is these “instructions”—before the advent of their machining in social media—that also provide the grounds for another current of work that sets out approaches in which the idea of the network or a set of contacts has become something that is more self-consciously to be used or manipulated in order to achieve certain political ends or social benefits. Work such as Manfred Kochen and Ithiel de Sola Pool’s “Contacts and Influences”, a manuscript circulating from the early 1950s and published in 1978 26, Stanley Milgram’s 1967 direct experimental work 27, and Mark Granovetter’s 1973 article “The Strength of Weak Ties” 28 exemplify this tendency.
The notion of “weak ties” addressed by such researchers was embraced in mathematical terms by Watts and Strogatz in 1998 29. One of the interesting aspects of such work that is the idiomatic kind of movement from the very specific to the general that it stages. This work is predicated on a particular kind of social connection, a friendship, knowledge of or acquaintance with an other, a social link, the passing of information from one entity to another, as the key, indeed sole, unit of analysis. It is predicated on a wager that from this base unit, if precisely logged, something larger can be agglomerated. Whereas other approaches to understanding the social in mathematical terms have often worked on the basis of surveying or assembling a population as a statistics-yielding mass, to be probed by averages and the deviations that yield them, this work starts ‘from the bottom up’ in a certain way by narrowly fixating on the choreography of what each different method takes to be a link. It is this movement from the specific to the general that its enduring attraction also lies, and, it wagers, something like a community can be measured.
As far as we have been able to trace, the physicists Michelle Girvan and Mark Newman were first to use the term ‘community’ to describe a computational object in network science. In a highly influential paper from 2002, Girvan and Newman, who were both working at the Santa Fe Institute in New Mexico at that time, coined the term ‘community’ in this context and also present what one might call the ‘founding articulation’ of community detection:
“Consider for a moment the case of social networks—networks of friendships or other acquaintances between individuals. It is a matter of common experience that such networks seem to have communities in them: subsets of vertices within which vertex-vertex connections are dense, but between which connections are less dense. […] Communities in a social network might represent real social groupings, perhaps by interest or background”. 30
In this description of communities, Girvan and Newman call to the experience of other network scientists who have noticed similar patterns of dense subgraphs in social interaction networks before, to suggest that a metaphorical or “commonsense” framing of community can be translated into network science.31 While ‘community’ refers to the groups of nodes, the problem of finding communities in networks is called ‘community detection’.32 Interestingly, both terms were first introduced by physicists and not social scientists, but have become hegemonic since then.33
With the increase in available computational power, researchers from statistical physics moved into the field of network science and started to use their own techniques, in particular the statistical modelling of real-world networks, the description of networks as historically evolving structures and a dynamical systems approach for studying dynamic interactions between nodes, culminating in a ‘new science of networks’. 34 This also lead to some amount of re-invention of parts of the social science literature and the relabelling of concepts like ‘community detection’ can thus be understood as a revival of social network analysis as ‘network science’ under the influence of physics.35 Only afterwards did some of the discourse in physics link up with the social science contributions, although Newman wrote several papers with social sciences references to address this less cited literature.36
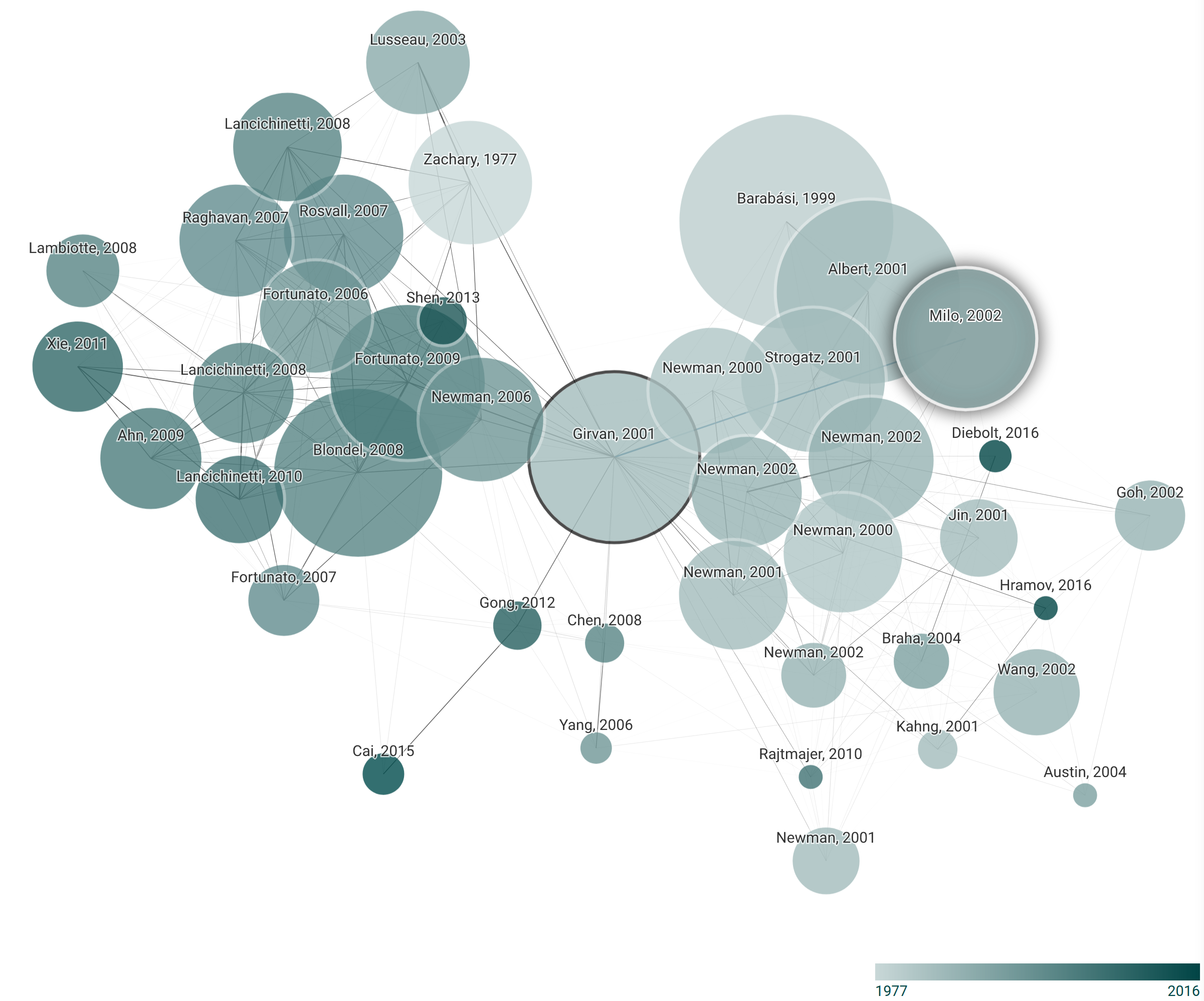
Figure 1: Bibliographic graph for Girvan and Newman’s original paper produced with the ‘Connected Papers’ tool. A bibliographic similarity graph is obtained for the original paper by Girvan and Newman placed in the center, using the online tool ‘Connected Papers’ in April 2022. Nodes in the network represent the most important prior or derivative publications and edges are drawn according to similarity between papers, as determined by the ‘Connected Papers’. We observe that the influence of the social science literature on the field is not reflected in this bibliographic graph.
After the formulation of the community detection problem, many functions were developed for computationally evaluating the quality of network partitions. One such evaluation function is that of ‘modularity’ proposed by Newman and Girvan, who developed a framework of ‘modularity optimisation’ to quantify the density of edges within communities as compared to a random edge configuration model. 37 Since then, a large body of literature has evolved and there are substantial investments in the maintenance and development of techniques for community detection. 38 However, the field remains contested and recent approaches, such as ‘inferential methods’ drawn from Bayesian statistics, challenge traditional techniques like modularity optimisation, which some authors even depreciate as merely ‘descriptive’. 39 Despite such controversies, the modularity optimisation based ‘Louvain algorithm’, introduced in 2008 40 and named for the university at which it was developed, remains one of the standard methods for community detection. We provide a short analysis of the operation of this algorithm in the Section 2.3.
There is an enormous bibliography associated with community detection which makes a detailed genealogy of the field difficult, especially because of the overlapping historical lineages we described above. Similarly, Fortunato suggests that “the field has grown in a rather chaotic way, without a precise direction or guidelines”. 41 A network science approach to this task could be to analyse the citation graph of, e.g., all scientific publications that cite the original article by Girvan and Newman and other works in the canon. A rigorous study of such citation graphs could be performed using the Academic Graph API by Semantic Scholar 42 and applying community detection on this citation graph of community detection papers would be an amusing meta-exercise, although lying beyond the scope of this paper.43 We restrict ourselves here to presenting a bibliographic graph obtained with the ‘Connected Papers’ online tool based on the Academic Graph API that claims to construct a similarity graph consisting of the most important prior and derivative publications starting from a paper specified by the user. 44 Figure 1 visualises this bibliographic graph as produced for the original paper by Girvan and Newman, 45 which is placed at the centre. We observe that the graph over-represents the influence of physics literature on the field and renders the early influences from the social sciences that are outlined above invisible. Hence, the diagram constitutes an interesting cultural artefact that shows the current hegemony of physics in the network analysis field despite its partially sublimated but non-contiguous ‘origin’ in the social sciences.
What has transformed over the course of the manifold set of lineages outlined in this section? Aside from the changes in size of the networks to be graphed and of computational power, the transition has also entailed a general loosening from specifically addressing ideas of the social. We can say that the techniques move from an abstraction from social groups involving techniques of observation, recording, encoding, and analysis into graphs that offer the production of a more generalisable formal structure. This form then provides a means of addressing many different kind of entity. It also provides a conceptual scaffold and technical substrate for new kinds of social relation to be grown.
2.2 Notions of Community in Network Science
To understand how community figures in network science we continue by approaching the concept of community as used by network scientists whose mathematical definitions rely on graph theoretic formalisms. For a very comprehensive introduction to network science, the reader is referred to Katharina Zweig’s book ‘Network analysis literacy’, 46 where the use of mathematical formalism is promoted because it abbreviates statements and makes them less ambiguous.
To give a flavour of the network science formalism, we guide the reader through some of the basic definitions with a running example at hand—a friendship network derived from anonymised Facebook data provided by Julian McAuley and Jure Leskovec. 47 Note that detailed reading of the mathematical formalism in the following is not essential for the understanding of this article and we only come back to it in our case study in Section 2.3. We use the Python package ‘NetworkX’ for computations and visualisation, 48 and Figure 2 depicts the example network that we denote by the symbol \(G\). The network consists of \(4,039\) Facebook users that are represented by points in the diagram called vertices (or nodes) and of \(88,234\) friendships between users represented by lines in the diagram called edges (or links). To formalise this mathematically, each vertex is assigned a unique integer from \(1\) to \(4,039\) and the collection of all these distinct integers composes the set of vertices that we denote by the symbol \(V\). For an integer \(i\), e.g. \(i=1\), the notation \(i\in V\) signifies that \(i\) is a vertex in the graph \(G\) or equivalently, an element of the set of vertices \(V\). Accordingly, the symbol \(\in\) is read as ‘element of’. To encode the relations between the vertices, i.e. the social relation of friendships in our example, we define an (undirected) edge between vertices \(i\) and \(j\) denoted by the symbol \(\{i,j\}\) whenever \(i\) and \(j\) are ‘friends’ on Facebook. The set of edges, i.e. all friendships in our example, is denoted by the symbol \(E\). Hence, our network \(G\) consists of a finite set of vertices \(V\) and a set of edges \(E\) and this is often summarised by the notation \(G=(V,E)\).49

Figure 2: Community detection in a Facebook friendship network. We visualise the social network \(G=(V,E)\) where vertices \(i\in V\) (the points in the diagram) correspond to Facebook users and edges \(\{i,j\}\in E\) (the lines in the diagram) are drawn between users that are ‘friends’ on Facebook. Community detection using the Louvain algorithm is applied to the friendship network and nodes are coloured with respect to their assigned community, which network scientists would interpret as a friendship group. The network is derived from annonymised data provided by Julian McAuley and Jure Leskovec and we use the Python package ‘NetworkX’ for computations and visualisation. We present this visualisation as an example of the diagrams produced in network science.
For network scientists, the term community now serves as an abstraction often used to describe a group of vertices that have stronger relations among themselves than to the rest of the network, 50 e.g. they share many friends or they play similar roles in the network. In particular, a community is determined entirely by its edges. The usual assumption is that networks can be divided into mutually exclusive or highly differentiated communities, where the number of communities is intrinsic to the network, and hence communities are understood to form the network’s building blocks. The collection of these communities as building blocks is also called a network partition and algorithms that are designed to find such partitions into communities are called community detection algorithms. Figure 2 visualises community detection with the so called ‘Louvain algorithm’ 51 (see Section 2.3) applied to our example network and the nodes in the figure are coloured with respect to their assigned community. The communities in the social network derived from Facebook could now be interpreted as different groups of friends and as we saw in the previous section, the notion of community is indeed motivated by the study of the social in a way that emphasises its interpretation as a concatenation of networks. One problem here is that it remains unclear if and to what extent community detection really operationalises the sociological concept of ‘community’ and while Girvan and Newman are cautious to make this claim 52, other researchers use community detection algorithms exactly for that purpose.53
Today, community detection algorithms find applications in data from disciplines as diverse as biology, computer science, engineering, sociology or politics. 54 Despite the high interest in community detection, there is—perhaps surprisingly—no generally accepted definition of what a community exactly constitutes in network science and so Michael Schaub et al. suggest that “community detection should not be considered as a well-defined problem, but rather as an umbrella term with many facets”. 55 They distinguish four different approaches:56
i. Minimisation of violation constraints: When referred to as partitioning, the goal of community detection is to cut a network into several parts with the least cost, e.g. by breaking the least number of edges.
ii. Maximisation of internal density: In computer science, community detection is often treated as a discrete version of the data clustering problem and the goal is to find communities that have a very high internal density of edges but are less strongly connected across different communities. Girvan and Newman follow this clustering perspective.57
iii. Identification of structurally equivalent vertices: In the social sciences, community detection is often used to identify individuals in social networks that play the same role and so the goal is to find communities that consists of structurally equivalent nodes.
iv. Dynamic model reduction: Instead of focusing on the static network structure one can also study diffusion dynamics of e.g. information flows or an epidemic on the network and from a model reduction perspective, community detection then aims to determine a reduced graph that shows the same response to the dynamics as the original graph.
While this summary gives an overview of different trends, there are also other categorisations of community detection, e.g. Santo Fortunato distinguishes ‘local definitions’ of communities from ‘global definitions’ and ‘definitions based on vertex similarity’ 58 or Tiago Peixoto divides community detection algorithms into ‘descriptive methods’ and ‘inferential methods’.59 The persistence of multiple categorisations further underlines the way in which community remains an ambivalent concept in network science and cannot be reduced to one precise meaning. In particular, the translation of community into network science is not seamless and Newman himself states that the description of community detection is “vague and open to interpretation”.60 Rather than seeing this as a problem however, we see that there are apt reasons for this relatively vague definitional state of the term. Before elaborating this argument more fully, we map how it plays out in a key algorithm.
2.3 Case Study: Louvain Algorithm
One popular technique in community detection methods is the so-called ‘Louvain algorithm’ developed by Vincent Blondel and colleagues in the University of Louvain, 61 which we will study in more detail here due to its high status and widespread usage. At the point of its development in 2008, the Louvain algorithm outperformed other popular methods for community detection with fast computational times and unprecedented scalability to extensive networks with more than 100 million nodes. 62 Since then it has been widely used, e.g., community detection in the popular Gephi software 63 for network analysis is implemented with the Louvain algorithm. 64 Hence, many researchers from the computational social sciences—among whom Gephi is popular due to its accessibility 65—ubiquitously rely on the Louvain algorithm for their study of social networks.
While the Louvain algorithm remains very popular and has been picked up widely with more than 14,831 citations (as of May 2022) according to Semantic Scholar, 66 there is a plethora of other community detection methods, made available by software projects like the python ‘Community Discovery Library’ (CDlib) that has currently implemented about 100 different methods including Louvain. 67 Community detection in general, and the Louvain algorithm specifically, are thus moving targets for analysis and there are other algorithms in the field, e.g., the recently developed Leiden algorithm has some crucial advantages over the Louvain algorithm in terms of how it evaluates the connection quality within communities. 68 The Leiden algorithm has thus gained in popularity among practitioners with Gephi planning to add it to their software. 69 Nevertheless, since Louvain is so widely used and so extensively implemented it makes an ideal case study for understanding community detection.
The Louvain algorithm was one of the first algorithms to give an efficient optimisation heuristic for the ‘modularity’ measure developed by Newman and Girvan. 70 With the help of modularity, usually denoted by the symbol \(Q\), it is possible to compare the quality of different partitions and high modularity signifies good quality. Hence, the goal of a community detection algorithm based on modularity optimisation is to find a partition that maximises achievable modularity. We will introduce the mathematical formalisation of modularity and discuss some of its philosophical assumptions below. For the moment we remark that modularity optimisation follows the clustering perspective (ii) on community detection as introduced in Section 2.2. The Louvain algorithm is designed as a so called ‘greedy algorithm’, which tries to find an optimal solution for modularity optimisation at each of its iterative steps. 71 We present pseudo-code of the algorithm below and describe its sequence of steps in the following.72 Note that both modularity and the Louvain algorithm can be applied to more general networks, in particular weighted and directed ones, but for the sake of simplicity we only consider unweighted and undirected networks here, as introduced in Section 2.2. The input of the Louvain algorithm is a graph \(G=(V,E)\). After initially assigning each node to a different community (step 1), the Louvain algorithm consists of two routines. In the first routine, one randomly loops over the nodes and a node \(i\in V\) is added to a neighbouring community whenever the modularity \(Q\) increases (step 4). After no further increase of modularity is possible with this strategy, a new ‘meta-network’ is generated in the second routine, where the communities are defined as ‘meta-nodes’ and the edges are aggregated (step 10).73 After this aggregation, the first routine is again applied to the meta-network (step 11) and the meta-nodes are grouped together in communities by the two routines as before. These two routines are now iteratively repeated in a feedback-loop between input and output until no further increase in modularity is possible and the algorithm terminates (step 8). The resulting partition can be derived from the communities of meta-nodes and corresponds to a local maximum of modularity. The optimal partition determined in this way is the output of the Louvain algorithm. To phrase this in a different way, we set the algorithm out in pseudo-code below.
Figure 2 visualises communities obtained from the application of the Louvain algorithm to our example friendship network, where nodes of the same colour are part of the same community.

We used the Fruchterman-Reingold algorithm 74 to draw our network in the two-dimensional plane, which simulates forces of attraction between highly connected nodes and repulsion between disconnected nodes. Note that the close match between the force-directed network layout and community structure is not incidental. In fact, the Fruchterman-Reingold layout can be used to obtain communities via spatial proximity that optimise modularity 75 and it was shown that force-directed layouts based on energy models can subsume the modularity measure. 76
One could now obtain descriptive statistics to gain a better understanding of the community structure, e.g. the network is partitioned into 16 communities of which the largest (red) consists of 548 nodes and the smallest (light green) of 19.77 Note that one of modularity’s features is that the number of communities is intrinsic to the network and can be recovered with the modularity optimisation. This is different to other data clustering algorithms like ‘\(k\)-means clustering’, where the number of clusters has to be specified in advance a priori. 78 We also remark that modularity optimisation is known to have certain technical limitations that have been well studied in the literature—most strikingly the ‘resolution limit’ that prevents modularity finding relatively small community structures .79 Solutions to the different technical drawbacks of modularity optimisation have been proposed in the literature, e.g. the resolution-limit-free ‘Constant Potts Model’, 80 but a review of these techniques lies beyond the scope of this article.
To deepen our understanding of the Louvain algorithm, we now give an introduction to the modularity measure at its core, 81 for which we require an additional mathematical formalism from graph theory.[82 The graph-theoretic formalism used here mainly draws from linear algebra and matrix theory because they allow for an easy description and precise manipulation of graph structures Zweig, Network Analysis Literacy.] We first introduce the so-called ‘adjacency matrix’ of a graph, which is a very useful tool to represent the graph structure. For a graph \(G\) with \(N\) different nodes, e.g. our example graph of friendships on Facebook from Section 2.2 has 4,039 nodes, we define the adjacency matrix denoted by the symbol \(A\) as a quadratic matrix, i.e. a matrix with the same number \(N\) of rows as of columns. The entry of the adjacency matrix at row \(i\) and column \(j\) is denoted by the symbol \(A_{ij}\) and represents a binary encoding for the presence or absence of an edge between nodes \(i\) and \(j\). 82 More specifically, we define \(A_{ij}=1\) if there is an edge between \(i\) and \(j\) and \(A_{ij}=0\) otherwise. Next we define the degree \(d_i\) of a node \(i\in V\) as the number of edges attached to node \(i\) and using the adjacency matrix the degree can be computed as:

where the mathematical notation \(\sum_{j=1}^N\) means that the sum over elements indexed by \(j\) ranging from 1 to \(N\) is computed. As each entry \(A_{ij}\) of the adjacency matrix encodes the presence of an edge attached to \(i\) and another node \(j\), the sum in the above equation counts the number of edges attached to \(i\) as desired. Let us further denote the number of edges in the graph by the symbol \(M\), e.g. the example friendship network has 88,234 edges. Before we can finally give the formula for the modularity, we need to establish a notation that allows us to compare whether two nodes are part of the same community. On that account, we denote the community of node \(i\in V\) by the symbol \(C_i\) and if two nodes \(i\) and \(j\) are in the same community this implies \(C_i=C_j\).
For a given partition of the network into different communities, the modularity denoted by the symbol \(Q\) then measures the density of edges within communities as compared to a random rewiring of edges. Following the presentation by Blondel et al. 83 and using our notation developed above, we finally define the modularity Q as:
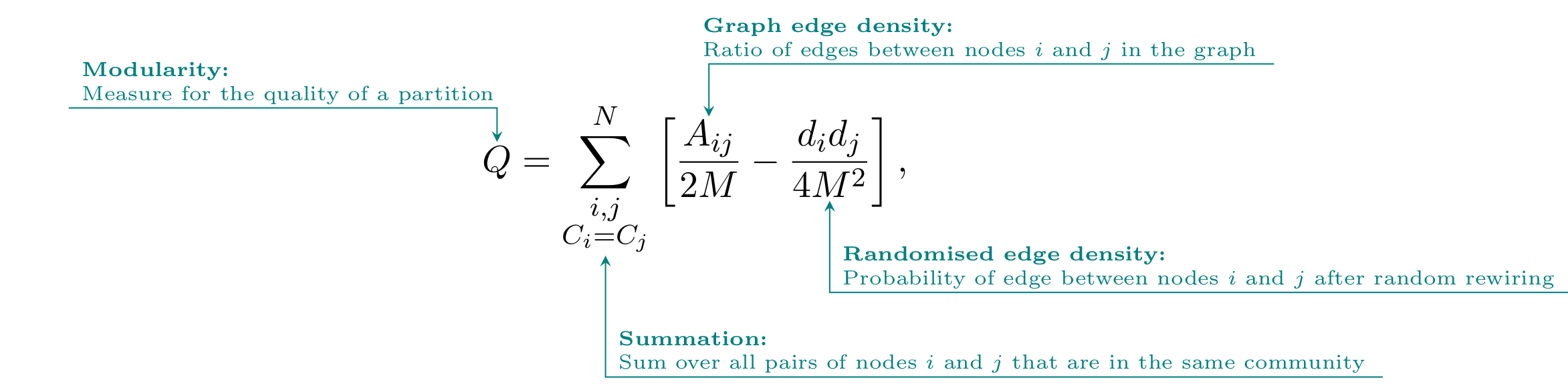
where the sum is executed over all pairs of nodes that are part of the same community. While the first term in brackets corresponds to the ratio of edges between nodes \(i\) and \(j\), the second term computes the probability of an edge being present between nodes \(i\) and \(j\) after a rewiring of the graph that only preserves the node degrees.
We summarise that in the modularity-optimisation approach as realised by the Louvain algorithm, a community constitutes a group of nodes with a high density of internal edges. In particular, neighbouring nodes are said to share a community when their connection is stronger than it would be were links to be simply randomly rewired. Membership in a community is assumed to be objective and inherently described by node attributes such that an inquiry of the underlying entities replaced by nodes in the network framework (e.g. of the people behind the Facebook accounts in our example friendship network) becomes unnecessary. Moreover, membership in a community is assumed to be a static and unique node attribute and this leads to an essentialisation of community membership as a node feature. Hence, community detection applied to social networks contrasts with a view of a community as something that emerges from imaginal and material social relations shaped by historical and ecological conditions. Community detection, for the purpose of finding communities in social networks, certainly entails the reduction of complex social relations into sets of discrete edges in a network. Still, community detection is widely appreciated as a ‘good enough’ tool and this leads us to analyse community detection algorithms as a form of heuristics in Section 3.3. In order to understand why this might be useful, we need to understand the vagueness of community as a term.
3. Vague Operators
3.1 Community as a Vague Operator
Although the algorithms designed for community detection mostly build on an ad hoc and non-committal understanding of a community, the term community also refers to a complex sociological concept that is often politically loaded and whose understanding can abruptly differ between, say, different scholarly or activist traditions, amongst other kinds of uses of the term. The word community thus serves as a conceptual boundary object that mediates, for instance, between the social and the computational sciences. The way that it does so is however quite idiosyncratically nebulous, in a way that invites discussion.
Key to Susan Leigh Star’s and her collaborators’ notion of the boundary object as it iterated over time and across different cases, is the idea of interpretative flexibility, that the same object can be read in many different ways, or for different purposes. An example would be a map of an area, which can be read to plan different journeys, or to carry out operations as diverse as strategising a military campaign, allocating goods or services, or retrospectively tracing the possible routes of a vehicle, amongst many others. Key to such examples is the way in which the precision of the boundary object enables multiple non-exclusive acts of interpretation. In some ways this makes it like other modern phenomena such as an ideal “writerly text”, 84 or what curator Lawrence Alloway called the “multi-evocative” 85 . Star’s formulation is aimed at discerning cooperation without consensus where an object is shared or generated by users who don’t necessarily agree on its nature or what it is for. By comparison, some of the tension between a formalism (like “community”) and its uses can be found in another context, one quite similar to that of certain implementations of network science—in that users may, as their name implies, see a use in a network, whilst the data on their interactions are the subject of exchange—is the distinction between exchange value and use value. In this economic faceting, the political contestation embedded in the epistemic comes to the fore. The exchange of a thing only partially determines or encodes its use or interpretation, and more fundamentally, the epistemic formations that go into the genesis of such an entity. Nevertheless, at times such factors can be strongly determining.
In an article reviewing the way in which the boundary object term has been disseminated—and it has been justly influential 86—Star notes aspects of the proposal that have been less widely taken up. One of these is for vague uses that as she says are “NOT interdisciplinary” that is, that whilst such objects might be mutually used or generated by different disciplines, they are not themselves the direct grounds for interaction between the disciplines concerned. 87 Star also notes the vagueness of aspects of some boundary objects as a condition that enables their usefulness in certain contexts. 88 It is this aspect that is applicable here. Community is a central yet vague concept in network science, and it is this vagueness that comes to have subtle importance. This can be nuanced in two ways. Firstly, community detection algorithms are not in themselves vague because algorithms are, in their own terms, precise yet ‘community’ is overloaded as a term, because different ‘community detection algorithms’, each of them precisely defined and implemented, produce or detect different network communities. The differences between them may be subtle or radical depending on their kind and the nature of the data that they interact with. Secondly, these different algorithms refer back to the term ‘community’ as a kind of boundary object, which holds many different meanings, but it is its affordance of vagueness that becomes productive.
In an earlier article (on a museum of zoology) Star and James R. Griesemer develop the idea of the boundary object to rework some of Bruno Latour, Michel Callon and John Law’s formulations around contests of meaning in the intersection points of ‘diverse social worlds’, where there is competition over the meaning of terms and the establishment of the means by which interpretations and significance can be established. 89 The boundary object becomes more or less fixed but only through what they call “ecological” means which are dynamic and multi-dimensional tussles over terms and practices. By contrast, in the uses of the term community that we encounter in network science, there is a rather different way of operating. There is an indifference to recruiting other users as allies in the same usage of the word. We also note that there is sparse construction of “obligatory points of passage” 90 in a mechanics formed by the interplay of ‘interests’ 91 since there is no competition on these grounds and no threat of displacement from one meaning to another without the risk of producing ‘interpretative flexibility’ since the object is vague rather than precise. Rather, than being fought over, ‘community’ is used, in this context, as something like an aggregate of hints, none of which necessarily ‘cash out’ as more than an atmospheric term or loose identifier of a broad category. In this sense, community acts as a further kind of boundary object, that could be called, following Star’s recognition of vagueness, a vague operator.
Vagueness can be useful, that is, put to many uses, some of which are tangential to each other and are not answerable to each other. We aim to map some of these uses, noting the way that as a vague operator, the term ‘community’ allows for different ideational, discursive, technical and mathematical operations to co-exist in an overlapping and often mutually indifferent way. Such uses indeed indicate aspects of the nature of a community, but in the sense that they can also cut across and interfere with each other, create detours in meaning and derive different results, so we are also dealing with a community of meanings that may be linked by curious means. As such, a vague operator is different to a boundary object because it may act as a means of inclusively obfuscating the terms of what is being conjoined, in this case, under the term ‘community’. We do not mean to claim that this is done for nefarious means—although this is likely the case at times with a term as loaded as ‘community’—but more that by mobilising a term that has multiple simultaneous meanings, uncontested vagueness, rather than a clear boundary or a multidimensional struggle over meaning, may have certain kinds of effects. It is these that come to the fore in the literature under discussion.
At the same time as it is a vague concept, community is one that also has a conceptual allure since whilst it operates as a vague technical description in different scientific idioms, community also has many other dimensions to its meaning. The idea of community as a good, or as a unit of analysis, is also an object of desire in some sense, not as an object, but what is sought after—as a condition of value. One kind of tension to bear in mind however would be that exemplified in the difference between the data on a social media platform being seen by the platform owners as units of analysis and exchange whilst being understood by the platform’s users as elements of use.
Furthermore, the term ‘community’ also mediates between the designers of algorithms and software users who might bring their own equally ad hoc and vague understandings of a community. As such, the term community comes with slippage when the computational object is seamlessly replaced with a sociological category in software systems that implement community detection algorithms. The often invisible translation of concepts from the non-digital to the digital world can be problematic as Richard Harper et al. note: “Boundary objects succeed when they allow both sides to get on with their concerns without interfering with the other. They start to fail when the clarity of this distinction blurs”.92 Vague operators, by comparison to other kinds of boundary objects, perhaps start to succeed when the clarity of the distinction blurs, allowing different kinds of claim to be made without too many questions being asked about their nature. This is not to imply that they are to be treated as inherently loaded, or that their use implies a sleight of hand. Rather, that their vagueness is the result of a certain kind of precision available to mathematical description that makes the words associated with it have a rather secondary quality. This factor indeed tilts the axis of our discussion away from that between boundary objects and vague operators to a broader consideration of the nature of mathematical knowledge in action.
In his essay on the Semiotics of Mathematics Brian Rotman points out that mathematics has the unusual property that “its signs seem to be constructed […] so as to sever their signifieds, what they are supposed to mean, from the real time and space within which their material signifiers occur”. 93 This gives mathematics its unique and highly valuable ability to be both about anything at all—in that, one way or another, anything can be described, however partially, by number—and, with equal intensity, mathematics is also able to perpetually rework itself through unlimited terrains of abstraction since the one thing a number can be about most acutely, is other numbers. In the case of community detection this means that the behaviours of systems typically studied by physics if described in certain limited and mathematical ways can also produce descriptions or mappings that are transferable to, or relevant in, other contexts, such as social ones.
A further dimension here is that many of the things treated as communities by such approaches do not pre-exist in a non-digital state. They are natively digital as Richard Rogers puts it to describe processes and entities that come into being in computational systems. 94 But, as such, they are also part of a wider category—the natively artificial. The artifice involved is not only computational, but also mathematical and cultural. Whereas calling something natively digital describes it in relation to a media, the natively artificial describes a state of genesis and possibility. Thus, the terms of community’s artificiality deserve probing and the recognition that they can perhaps be redesigned. Artificiality can provide grounds for a work of variation in which the presumptions and determinants of many kinds of communities can be reworked rather than being treated as an identifiable given.
Indeed, under the name community detection, what might often be sought after is not community in the social sense, but a more general class of processual things of which a social community can said to be an example—things which in combination produce a unity. Processual things as a broader class of self-regulating entities entail complexes of relation whose interaction of parts emergently develop a contingent whole where sets of relatively simple entities combine to produce a more complex state. This new state may be describable as another kind of entity or idiom—a change from nodes to networks for instance. Community detection aims at divining the structure of such a movement. In turn, numerous kinds of entities, including social media, e-commerce and other platforms, attempt to determine the underlying patterns of such emergence and by doing so to harness and entrain them to certain kinds of programme (see Section 3.2). Creating the right harness for the capacity of self-regulation, of something more complex to come out of the interaction of simpler states of things as they emerge into other states, is, as Alexander Kluge and Oskar Negt argue in “History and Obstinacy” something that characterises much of the work of politics, psychology and economy. 95 Their book charts the ways in which technologies address, grip and reframe human bodily, psychic and social capacities starting with such states of emergence.
The quality of emergence, which is brought into community detection from those trained in physics as we saw in Section 2.1, is what is hankered for. Changes in the state of a thing, of apple juice into cider, a child into an adult, or the mutually coordinated arrangement of birds into a flock are typical kinds of emergence. 96 The mapping of an implicit collective into a graph marking simple transmissions of information and the ability of that mapping to register a movement towards a point at which these transmissions ‘go viral’, betokens a capacity to abstract such emergence. They are both moments of transition at which value of many different sorts can be gained. The craft of the algorithm writer 97, or the user of a community detection algorithm, in this context is to find a way of cleaving to the moment of developing self-regulation or emergence in a way that is meaningful. It should allow emergence to be described, without killing it off. In the context of a graph used in social media this delicacy would be required to avoid creating something alienating yet whilst—in an echo of another kind of capture of energies, labour and materials that is not without violence and domestication—successfully ‘milking’ it for meaning and value. One might imagine other formations in which a successful ‘hack’ lies in re-reading or transcoding information that is available ‘for free’ in one context, but re-contextualising it via other abstractions. The art is indeed in engendering reciprocal exchanges in which forms of feedback between the mapped entities and the forms of mapping themselves generate other conditions of emergence.
One of the things effected by this vagueness of the term community, but also its significance as a thing that may refer to value-bearing entities and processes is the distinction between the discrete and continuous typical of digital systems.98 Here, vagueness facilitates the possibility of the idea that community is based on discrete connection rather than something describable in more continuous terms, or by means of translation, such as overhearing, innuendo or implication, a general sense of something. At the same time, this movement can be reversed; nebulous continuities preceding the possibility of the discrete. The craft of the algorithm designer thus has something to do with recognising partiality, the inadequacy of description in a vague operator, as being potentially productive, whilst negotiating the way in which this quality also plays out in relation to other consistencies, such as available computational resource. To this end, an understanding of the development of algorithms involved in community detection such as we offer above is pertinent, as too is an engagement with the controversies running through them.
3.2 Controversies arising from Community Detection
It may seem as if we have earlier identified vague operators as some kind of idyllically woozy and indeterminate form that lends itself to a plurality of interpretation and use in a way that evades some of the problems of identification. However, what might pass as virtues in some contexts, or in another facet of the same broader context, can operate as difficulties in others, by providing different kinds of usefulness. Controversies may arise in part due to the way the term community acts as a vague operator.
In this section we briefly identify some of the ambiguous applications of community detection, in particular ‘recommender systems’ and ‘anomaly detection’, and discuss problems arising with them. Here, the epistemic dimension of community detection as an approach to describing and implementing things in the world, creates particular interpretative tensions and imperatives as they interlace with certain kinds of contemporary power in their application. In such cases vague operators work in another way, as what Alfred Sohn Rethel 99 and subsequently Alberto Toscano 100 name ‘real abstractions’. Real abstractions are a means of making a materialist account of ideas and formalisms as they enter into relations with other kinds of stuff, such as goods, persons, and economic structures. A crucial form of real abstraction is the instantiation of the split between exchange value and use value mentioned earlier where exchange value is the real abstraction. It is called real since it has effects independently of the ideas we might have about it. Marx discusses the almost mystical state of the commodity or of money in its ‘pure’ form, waiting to be exchanged, to be used. 101 We can say that mathematical entities, in the terms that Rotman sets up, have something of the same quality. A number does not take with it any traces of its previous uses, it springs into the world each time afresh. This is what is often so pleasing about them, and to connect with another thread of this argument, makes them useful, replete with affordances of possible use. And they are also real abstractions in the sense that, as they migrate out of the ideational phase of mathematical practice and into relations with other parts of the world they start to gain traction on things, as explanations, indexes, veils and objects in themselves. Computer systems indeed can be seen as dynamic nested hierarchies of real abstractions, and as such they may embody and mediate tensions, potentialities and conflicts at other levels of abstraction.
Recommender Systems
Community detection is widely used in the design of recommender systems, 102 i.e. algorithms that recommend products in online marketplaces or prompt actions such as following a person on a social networking site based on a user’s history on that site or, via third party means, across others. In particular, community detection (e.g. with the Louvain algorithm) is used to obtain groups of users with “similar social characteristics” 103 to either directly perform link prediction, 104 where a user might be recommended to follow another user analysed as belonging to the same community, or to enable the application of more resource-intensive recommendation algorithms on smaller-scale communities. 105 Here, community detection tracks a history of relations between entities and connects to other mechanisms, such as cookies, that describe a state of operations: whether an action such as a purchase has been carried out, how long a browser window was open onto certain data, whether there is a return to particular objects or sources such as a playlist of tracks and so on. The use of recommender systems poses two problems that have been widely recognised, that of reinforcement or channeling, and that of reduction.

Figure 3: Reinforcing loop of community detection and recommender systems. Community membership leads to network structure by link recommendation based on recommender systems. From the network structure, new community memberships are deduced using community detection algorithms. Accelerated through this feedback loop, social networks become polarised and community detection might reinforce difference and segregation.
The first aspect of the problem acts as a kind of self-fulfilling prophecy (see Figure 3), or what Dan McQuillan calls “reinforcing loops”: 106 ever tightening loops between detection and recommendation that produce the by know well-known effects of filter bubbles and echo-chambers. But these effects also consist at another level in proposals to counter them by “normative” means that aim to rework them by a higher level of statistical generality. Bubbles and echo-chambers are anticipated and worked in advance, by approved parameters. Here “corporate ethics” and regulatory policies, moderation systems, and other tricky apparatuses come into play. The second aspect of this problem occurs through the operation of community as a form of real abstraction with jointly epistemic and material consequences. Here, the biologist C.H. Waddington’s notion of chreodisation or channelling is useful. 107 Waddington proposes attention to the ways in which patterns of development take place in a ‘landscape’, which may be more or less recursively responsive, and which shape the range of actions that can be taken within it leading to the development of divergent and self-reinforcing branching structures or ‘chreods’. Herbert Simon’s formulation of the evolution of ideas in a society 108 or organisation being partially determined by their niche and Sohn Rethel’s Marxist arguments about the formation of epistemic entities within the dialectical formation of history 109 are also relevant in mapping the kinds of processes in play. In all of these cases a reduction, for instance a sign or token, stands in for the real as a part of particular practices and activities. Over time, or inherently to a process, that reduction is taken for the real and it is then used not only to refer to but to structure reality. As a result, it may become or replace the real, depleting it. This is of course a wider problem within modern societies where what might be called a “reverse schizomogenesis” occurs. In this sense, computing can tend in some ways towards a monoculture. To follow Yuk Hui’s call for “technodiversity” we might try to counter such tendencies by recognising the diversities within mathematics and in mathematics as culture. 110
Following Wendy Chun, who identifies ‘homophily’, the principle that “similarity breeds connection”, 111 as one of the main drivers of ‘pattern discrimination’ in network science, 112 we can consider community detection as a method for performing ‘pattern discrimination’. Similar to homophily, the ‘performativity’ of community is revealed in its capacity to draw boundaries and aggravate echo chambers in social networking sites as argued above. When following clustering perspectives (ii) presented in Section 2.2, one could interpret ‘community’ as a reciprocal concept to ‘homophily’ because 1) nodes in the same community are more densely connected and thus interpreted as similar and 2) similar nodes are expected to be densely connected and thus clustered in the same community. Community thus becomes a means for critically diagnosing homophily and also for implementing it. As a vague operator, it allows for entities in a network to exist in both of these complementary and mutually reinforcing states simultaneously whilst maintaining the duality of potential interpretations that also pulls them apart somewhat depending upon the interpretative niche or dialectical tension to which they are subject. The vague operator of community here allows for the effective glossing of this state.
Anomaly detection
An additional problem we want to note is one indicated by an explicitly political use of network science models of community. Matteo Pasquinelli proposes that algorithmic vision has two epistemic poles: of pattern recognition and anomaly detection.113 In network analysis, pattern recognition corresponds to community detection as described above. “On the other side, anomalies are results that do not conform to a norm. The unexpected anomaly can be detected only against a pattern regularity”. 114 Consequently, anomaly detection in social network analysis can also be performed with community-based network outlier detection methods that identify ambiguous nodes at the border between different communities. 115 Moving between the poles of pattern recognition and anomaly detection, algorithmic vision within social network analysis aims to identify important actors in the network, their influence and interactions across different communities or to predict structural weak spots. 116 The network structure of digital control societies allows for extensive networked surveillance. Consider as an example the military Anomaly Detection at Multiple Scales (ADAMS) project funded by the US Defense Advanced Research Projects Agency (DARPA) with $35 million that aims to surveille large-scale communication networks of e-mails and text messages for the identification of anomalies and security threats, especially whistleblowers:
“Each time we see an incident like a soldier in good mental health becoming homicidal or suicidal or an innocent insider becoming malicious we wonder why we didn’t see it coming. […] ADAMS aims to rectify this situation by developing technology for the automated support of proactive use of the massive data sets being collected. […] ADAMS will characterize graphs containing up to billions of nodes by structural feature sets calculated using recent breakthroughs in graph analytic techniques. ADAMS will use these features as the basis for novel anomaly detection algorithms.” 117
Here, the network graph is used as part of an apparatus aimed at establishing deep forms of control over behaviours and the graphed entities that exhibit them. Different to the use of such techniques of identification in social media, the phenomena undergoing emergence here is one to be quashed rather than capitalised upon. The reasons for defection from military logics are not examined, but optimised against. There is a further lineage here, that of colonial and imperialist anti-insurgency techniques where populations are grouped and their connections are monitored. 118 In both cases control over the identification and calculation of variation within what is established as a networked social form are key. We can observe, in the passage cited above, that what might prompt variation from the enchannelled range of possible variation is dubiously explained as a phenomena of mental health rather than of ethics or politics. Good mental health, in behavioural terms such as these, becomes something identifiable through adherence to a set of norms of expression and behaviour. Here, the notion of mental health operates as another kind of vague operator, but one identifiable through analysis of a ‘community’ of actions, comunications and statements transcribed by the day-to-day working systems used by the militarised person.
These controversies exemplify some of the tensions in the computation of culture and society. The push to forms of what are judged to be optimisation that they epitomise risks depleting the capacity for difference— in a form of devastation 119 via logical restructuring—that chains the much prized emergence that is sometimes limned by network analysis to a monotonous kind of ordering. The vague operator can play an enabling role in this. In order to mediate that condition, we want to go a little further to suggest a practical means of reframing the problem by reorienting a potential within it. How might it be possible to think and work critically with algorithmic processes whilst recognising the ways in which they are shaped by conditions of vague operation? One of the ways of doing so would be to think through the question of heuristics.
3.3 Algorithms as Heuristics
Blondel et al. call the Louvain algorithm a “heuristic method that is based on modularity optimization”120 by following a ‘greedy strategy’ of local optimisation at each step. In the discussion of their paper they also suggest other ‘heuristics’ (like thresholding for early stopping or excluding nodes with only one link from the analysis) to speed up their algorithm. 121Heuristics are used because the problem of community detection is ‘hard’ and, in fact, it was shown by Brandes et al. that the task of modularity optimisation is indeed NP-hard. 122 This means that there is no polynomial-time algorithm for exact modularity optimisation and this serves as a “justification to use approximation algorithms and heuristics to cope with the problem”.[124 Ulrik Brandes et al., “Maximizing Modularity Is Hard” (August 30, 2006), p. 9, arXiv: physics/0608255.] In that sense, the Louvain algorithm is an ‘approximation algorithm’ that gives an efficient heuristic for community detection via modularity optimisation. The more recent Leiden algorithm seeks to optimise the exact same quality function (modularity) but uses a different optimisation heuristic that produces better-connected components and runs faster. 123
These considerations of the Louvain and Leiden algorithms as heuristics serve as an impetus to study the deeper connections between algorithms and heuristics. We further propose that there is an affinity between operating via heuristics and understanding, configuring or playing along with something as a vague operator.
The term heuristics first arises in modern mathematics in the work of George Pólya who draws on ancient sources, and the early modern systematisers Descartes and Leibniz, to contextualise his study of mathematical problem solving. Pólya’s 1945 book “How to Solve It” is a rich pragmatics of techniques for helping to get to solutions in a “provisional and plausible” way.124 Pólya sees a heuristic as being of great use, but largely as a scaffold towards a rigorous proof. The term is taken up in the 1950s in the work of economist and artificial intelligence researcher Herbert Simon, 125 where its potential application is broadened. 126 In this incarnation it describes the kinds of economic decisions that can be made with limited information in the condition of what Simon called ‘bounded rationality’. A choice or decision always happens in some particular context, that of an organisation or administration, one of available data and the means to evaluate it, or a social context that drives and imposes certain notions of what is satisfactory. The question of what is satisfactory also prompts the development of another related term, ‘satisficing’, where ‘satisfying’ concerns finding a “good enough move”, 127since, “an organism that satisfices has no need of estimates of joint probability distributions, or of complete and consistent preference orderings of all possible alternatives of action.” 128
The need for heuristics or techniques of satisficing in this area of research is set out in Simon’s work on economic behaviour where he counters “Olympian” models of human reasoning 129 that aim to act from the possession of all facts. Heuristics are a way of working round this requirement for an absolute formal foundation, by making a more or less arbitrary ‘cut’. The problem for a heuristic is to find an appropriate cut between smaller and larger amounts of information and information about that information. Approaches based in heuristics allow for approximate rather than absolute information to be the basis of a decision. It is important to note that the use of heuristics is not a question of being anti-reductivist. Rather, the question is one of developing an effective technique that acknowledges the inevitability of reduction in the development of an abstraction or formalism and thus lowers the expectations of it from an “Olympian” scale, to a more pragmatic one. In a sense, heuristics could thus be understood as “humble reductions”. This formulation however returns the question of the scope and nature of the pragmatics involved and how it plays out in specific contexts and set-ups.130
As Celia Lury has argued in a recent discussion of his work, 131 Herbert Simon was particularly alert to the wider ways in which the construction of the form of efficacy has consequences for the formation of understanding. In common with many researchers working in frameworks developed after cybernetics, Simon experiments with linguistic and conceptual moves that seem to move between both naturalising technologies and technologising natural entities and processes, such as organisms; the concern is to tease out abstractions that work across these registers. Entities, whether ants, humans, organisations or societies are viewed as dynamic structures whose behaviour may be traced and modelled. These behaviours are seen as produced at the interface between the internal state of a system and its environment. 132 It may not be possible to fully describe all possible states of the interaction between such an entity and its environment, but approximation to them may be drawn up. Lury sets this work up as part of a disposition towards problems, drawing on the epistemological discussion of the problematic, but seen through the perspective of the particularities of the co-constitution of research methods and the material that they treat.
Algorithms of course don’t work or even exist on their own. They are manifest in different modes of inscription or media, such as formulae or as pseudo-code for instance, and as something written into specific pieces of code running on particular systems at particular moments in time. They are further worked into and compose things such as social processes, database formats, and file structures amongst other things and in different contexts are something more or less indirectly experienced or undergone. They are worked through servers, by business plans and institutions, and are steeped in different kinds of politics of access. In turn, what is delivered by an algorithm producing a graph in a mathematical form requires further software to be visualised. Layout algorithms embedded in particular applications or libraries, are used—for instance, the Fruchterman-Reingold algorithm 133mentioned in Section 2.3 —to place a diagram with intersecting edges on a two-dimensional plane. The account of the Louvain algorithm offered in this article attempts to show such variation by articulating it in different forms, as too does the use here of different kinds of graphing embedded in specific libraries or particular informational products. Each carries with it and sets-up different kind of imaginary and capacity to register or entail.
Here, Lury’s formulations become particularly useful in that problematics are also intricately formed in techniques. The history of different rules of thumb or methods of approximation will themselves play out variably in different environments. Their particular acuities or fallibilities may become more marked, fraught, or less significant in different contexts. The relative size, granularity and qualities of data sets, the terms of the approximation, their fine detail and so on may provide significant aspects of such an environment, as might the more or less explicitly political dimensions of the milieus in which they form. Amidst all of this, the great usefulness of vague operators is partly in reworking the tensions between such scales and terms. In this condition we need a critical heuristics to handle the multiply nested arrangement of such things in a landscape of vague operators.
4. Gesticulations towards a critical heuristics of community detection
When a beetle topples over and lies upon its back waving its legs to the world, the arcs its limbs make in the air may have meaning, perhaps to the beetle, perhaps to entities in its environment, but those limbs may not meet resistance. Applied mathematics or network science, when its world is too easy, too readily arranged for its interpretation, may remind us of a beetle upon its back. This resemblance is due to the conventionalisation of real abstractions, the too apparent applicability of many computing tools makes them verge on the edge of the illusory. Computational ease tends to align with existing formations of power and concentrations of data-wealth that render certain things more possible than others, despite the great potential plasticity of computing. 134 In a sense, we are back to Rotman’s note on numbers as ‘severed signifiers’ and the alternation between the grasp and construction of things by different forms of evaluation as variously decsribed by Lury or Sohn-Rethel. At the same time, such signifiers are immensely potent when they are not “de-severed”, but plugged into problems that can be addressed by their capacity for abstraction. Network science can both contribute to setting up the conditions by which a population can be treated as tokens in a game of behavioural psychological warfare in advertising or political machinations as illustrated in Section 3.2, but it can also work to test the spread of an epidemic. 135 Both of these are immensely useful, in certain ways, but simple facility is insufficient to judge their wider validity.
As we move towards the end of this article we want to draw on heuristics as a means of mediation between a formalism or an abstraction and those things such as data, or various forms of real on which, by means of various layers of translation and mediation, it gains traction or resistance. A heuristic is supposed to be a pragmatic cut, the result of a process of parlaying between the possible and the probable it is a ‘reasonable adjustment’ subject to more or less equally reasonable doubt. In the way that Blondel et al. use it in the design of the Louvain algorithm, 136 heuristics are used in a way that acknowledge their own limits as a limited and contextualised exercise. What if a heuristic could also become speculative or critical rather than primarily pragmatic in the sense that it ‘works’? Some of the existing literature in network science and related fields prompts us to talk about this.
In their text, “Clustering: Science or Art?” 137 Ulrike von Luxburg, Robert C. Williamson and Isabelle Guyon suggest that clustering should be evaluated according to the downstream task where there are clearer-cut criteria for suitability. Similarly, in their article, “Community Structure in Graphs”, 138 Santo Fortunato and Claudio Castellano argue that there is no ‘silver bullet’ in community detection and no perfect algorithm exists for the task. This is formalised by Leto Peel, Daniel Larremore and Aaron Clauset who prove a ‘free lunch theorem’ stating that community detection algorithms perform equally well when averaged over all possible problems and only on a subset of problems can one algorithm be preferred. 139 These different formulations all draw similar conclusions, if you want to do more than exploratory data analysis you have to tailor to the specific system at hand, or attend to the problem being addressed by producing more specialised algorithms. The criteria for this evaluation might come from the problem being examined, but also from what counts in understanding the gestation of the problem and what counts as adequate means to formulate some kind of its knowing.
One mode would be to attempt to formulate a provisional “quasi-universal” in which the problem can be subsumed, to aggregate more information to dissolve the particulars of the problem in a conceptual substance supple and granular enough to absorb and rework its specificities in an enquiry driven by these. Another, is to separate out the problem, and only treat the immediate point in the established pipeline at which one is positioned through mental compartmentalisation and technical segmentation. Another is to both critically engage with the epistemic and political dimensions of the problem at the same time as humbly and playfully working with heuristics. It is the latter option that we aim to gesticulate toward in four ways to imagine a ‘critical heuristics’ that embraces partiality, works by means of epistemic humbleness, and offers capacities of reflexivity and artificiality. In this of course we recognise that heuristics, just like absolutely rigorous proof, on its own does not ‘solve’ the problems within which mathematics is embedded. At the same time, it may provide a means of examining the difficulties in, and reworking and moving amidst and across, vague operations.
Partiality
It is worth teasing out some possible use of the heuristic mode. One way is to recognise the terms network and community themselves as forms of heuristic descriptor or rough approximation, both as heuristics and as vague operators with the different valences of interpretation that these terms imply. Often, in application, the term community can only be partially relevant, but as a vague operator it is more or less adequate, and it is that partiality that is interesting. It is sometimes a partiality that does the work of convincing users that in some contexts it is a ‘good enough’ description of a community as such, or at other times, the partiality that does the work of articulating sets of certain kinds of relations in something that is not quite a community, but that can be more or less usefully described as such.
What is interesting here is the generative deployment of partiality: partiality as a form of productive discrepancy, partiality as constructive misreading, partiality as mistranslation layered upon others, partiality as a retraining of social forms into something ‘more computable’. In applied mathematics it is generally understood that such partialities are produced by idealisations or representations that to some extent always mistranslate. Partiality introduces the possibility for recursive operations of misplaced concreteness, as something that more or less maps onto something that has already been mediated into a graph.
Such partialities or approximations can make for a certain kind of forgiving or playful conviviality, but they have to be tuned into; as when Annie Ernaux talks of the “approximate” quality of conversations between lovers whose linguistic terrains only partially overlap. 140 One can say this about such things as the different figures, formulae, analyses and modes of encoding that jostle together in this article. Here, the romantic formulation of the illusory nature of exactitude (as for instance in Schopenhauer or Nietzsche) and its more recent reworkings comes into play. Partiality, being partial to something, can then be the grounds for congenial relations. The patterns of interference between different modes and sample-rates of such partialities are also the grounds for a creative micro-politics, and, equally importantly, for the recognition of cruelties in what is rendered inexpressible, or what is sheared off.
Epistemic humbleness
The vertex and the line act as forms of index, they refer to something such as a relation or an entity. The idea of the index, even by something as severed as a number is a problem of representation. To establish this, we can ask, “What would the movement of the beetle’s legs look like in a frictionless medium?” In other words, can we imagine an absolutely isomorphic mapping of an entity in a way that is only describable in the terms of edges and vertices, an object of enquiry that literally calls for such graphing because it can have no other manifestation? This is what exists in purely mathematical terms, but when they come into combination with entities and processes that they translate, some things may be missed, become vague, amplified or crossed out. A critical heuristics would pay attention to what is rendered mute in such a condition, that which is lost, relations that are inexpressible or set to invisible, what is sloughed off as defiant of reason, rule or representability. It would recognise the crudeness of the abstractions it offers and work with them as a kind of Art Brut rather than as a revelation of Platonic verity or an unfortunate condition of “things as they are”. For instance, due to their ability to map relations only in one-to-one terms, one node to another in pairwise interactions, it is difficult to express relations between individuals and collectives using network graphs. Such a relationship might include that between a person and a state and its agents, such as the police, or between one class and another. Graphs also cannot sense relations based upon exclusions, voids or devastations, what is not there.
A critical heuristics enquires into what entities warrant transubstantiation into nodes, which relations are describable as vertices, whose data is rendered accessible, what data is legible to which systems. It works as part of an enquiry into what is rendered economically interoperable through the perspectival operations of what is rendered as a perdurable glitch. 141 It looks incessantly for what is deemed to be outside the scope of the problem, that can provide resistance or footholds in terrains that may be social or political, ecological, conceptual or mathematical. (In this way concern with the ecological costs of computing might prompt a return to the proper veneration of terse and elegant algorithms and sparse use of computational resources for instance.) A critical heuristics might, in making propositions, subtly shift out of what can be the sometimes overly reactive trap of the critical mode. It would also shift the game of heuristics. One of the implicit claims of a heuristic is that it is a humble mode of thought and action. Heuristics are humble because they acknowledge the reduction they make and recognise its provisionality and partiality. Too often, this humbleness passes off as an excuse not to think as users bracket the provisionality of heuristics off when employing them. Might we imagine an actually humble heuristics?
Reflexivity
Instead of means to recognise the wider dimensions of relationality suggested in the note on humbleness we live amidst social graphs or office graphs that often use similar graphing structures not to bring more things into account in recognising the complexity of an event or a person, but to accumulate more kinds of things under the same representational regime and to entrain them to it. If we return to the use of heuristics in the case of the Louvain algorithm, whilst Louvain is described as a heuristic by its authors, its use might be quite different. The communities it graphs might be taken to be frictionlessly real, rather than something at least partially brought into being by the contact with and provision of resistance to the algorithm and the systems through which it operates. When communities are taken as simple reals it is tempting to forget the heuristic nature of their manifestation and the vague operation of their translation.
In order to interrogate this forgetting, often integral to the segmentation of a problem within modernity, there can be intuitively imagined a ‘pipeline’ between different stages of the development of a technique. This pipeline, say, for an algorithm for network analysis, would run through: mathematics, where the approach is posed; computer science, where it is formalised; software engineering, where it is implemented; the domain of users, where it is deployed in software that they use to work on specific cases; finally, one end of the pipeline that occasionally appears is very much the last dribble of its flow, and is composed of critical readers or those who are seen as ‘complainers’ who try to evaluate or ‘undermine’ the entire effort, but whose work can be safely ignored at any stage of the pipeline.142 Our intent with this article is to suggest a closing of the loop of this piped construction and to work the epistemic and political analysis in with the mathematical, with software and its uses and interpretations. A critical heuristics might be helpful in making this line into a loop by introducing reflexivity into the pipeline such that practices are de-segmented and epistemically evaluated throughout, leading to a gurgling cascade rather than a streamlined flow.
Further, reflexivity can also be found in the form that, since social network analysis has become a ‘fact of life’, through the various implementations of social media, or through dubious tools of control such as the London Metropolitan Police’s “Gangs Matrix” or its successor systems, 143 and through citation analyses such as the h-index for academics, reflexivity is to be found simply in peoples’ navigation of a social and informational domain in which these are operative and structurally significant factors. There is scant opportunity for ‘naive’ behaviour under such conditions, so network analysis can be said to map only those behaviours that are given under conditions of network analysis. Reflexivity thus may also be found in the irony and cynicism induced by a metricised society of analysis.
Artificiality
The problem of describing communities per se is not simply one of applying numbering techniques to something that naturally elides them. Numbers and numbering practices are not simply thin shadows of something already in the world that is more robust, meaningful and concrete, although they may sometimes be so. Nor are they automatically reducible themselves to certain functions such as reification, this depends on the particular conjunction. Rather, they can also be recognised as something artificial and novel existing and working in the world irreducibly 144. Numbers have their own specific qualities, the uses and implications of which vary across, cultures, polities, technologies and implementation, in other words in historical terms.
Calculative practices and technologies can be inventive, arranging new entities and novel conjunctures. They also exist amidst thousands of other such things, allowing for the formation of computations traversing assemblages of different kinds. For instance, in this context the connection between modularity and community is one of these expressive conjunctions in that modularity is a function that is hard to optimise since it is NP-hard, whilst community is much vaguer. The overlap between these terms is slippy, a vague operation, the simultaneously ideational and material play in which offers itself to numerous kinds of use, a condition that demands epistemic and political work that embraces artificiality. 145 A heuristics that is able to play with and to speculate through this condition of artificiality is also one that is able to work through the pluralities of artificiality, including those that are deemed to be perverse, unwholesome, too recondite, obscure or geeky, that is, perhaps of decadent as well as inventive kinds. It may also provide the grounds for testing the ways in which it is too readily put to work, to reclaim the productive fragility of precise knowledge in its dance with vagueness.
5. Conclusion
We propose that an expanded heuristics can provide a route to reflecting on the limits and wider dispositions of algorithmic knowledge. This motivates us to focus on community detection as a set of mathematical heuristics that can be used in ways that are potentially attuned to their limitations. This combination of descriptive thinness and capacious applicability makes, we suggest, the term community a vague operator (a particular kind of boundary object). Building on this, we propose a critical heuristics in network science that has the capacity to both recognise and profit from its constructed nature and to proceed via humble epistemological claims. A heuristics that is more tactical, provisional and contingent may also offer a recognition of the tensions and absences involved in such kinds of knowledge and real abstraction. In a sense we want to suggest that a ‘no free lunch’ argument, in which every algorithm has its idiosyncratic costs and predelictions, can also be made at an epistemological and political level. Here, the various kinds of interplay between the hyper-precise and the vague that are embodied in the conjuncture of particular algorithms and specific problems to be worked on are to be kept in mind as well as being implicitly mobilised in techniques.
Acknowledgements
We would like to thank Michael Schaub and Mauricio Barahona for insightful discussions about community detection in network science and its different lineages. No errors here are ascribable to them. We would also like to thank the Centre for Digital Inquiry at Warwick University and the Digital Democracies Institute at Simon Fraser University for giving us the opportunity to present parts of this article in their respective seminars. Finally, we thank our anonymous reviewers for their very useful suggestions. Funding in direct support of this work: JS acknowledges support from the EPSRC (PhD studentship through the Department of Mathematics at Imperial College London).
References
Akoglu, Leman, Hanghang Tong, and Danai Koutra. “Graph-Based Anomaly Detection and Description: A Survey.” April 28, 2014. arXiv: 1404.4679 [cs].
Alloway, Lawrence. “Eduardo Paolozzi.” October 136 (2011): 29–31. JSTOR: 23014863.
Ammar, Waleed, Dirk Groeneveld, Chandra Bhagavatula, Iz Beltagy, Miles Crawford, Doug Downey, Jason Dunkelberger, et al. “Construction of the Literature Graph in Semantic Scholar.” In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 3 (Industry Papers), 84–91. New Orleans – Louisiana: Association for Computational Linguistics, 2018.
Amnesty International UK. Trapped in the Matrix: Secrecy, Stigma, and Bias in the Met’s Gangs Database. London: Amnesty International UK, May 2018.
Barthes, Roland. S/Z. 1st American ed. Translated by Richard Miller. New York: Hill and Wang, 1974.
Bastian, Mathieu, Sebastien Heymann, and Mathieu Jacomy. “Gephi: An Open Source Software for Exploring and Manipulating Networks.” In Proceedings of the Third International Conference on Weblogs and Social Media, ICWSM 2009, San Jose, California, USA, May 17-20, 2009, edited by Eytan Adar, Matthew Hurst, Tim Finin, Natalie S. Glance, Nicolas Nicolov, and Belle L. Tseng. The AAAI Press, 2009.
Blondel, Vincent D., Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. “Fast Unfolding of Communities in Large Networks.” Journal of Statistical Mechanics: Theory and Experiment 2008, no. 10 (October 2008).
Brandes, Ulrik, Daniel Delling, Marco Gaertler, Robert Gorke, Martin Hoefer, Zoran Nikoloski, and Dorothea Wagner. “Maximizing Modularity Is Hard.” August 30, 2006. arXiv: physics/0608255.
———. “On Modularity Clustering.” IEEE Transactions on Knowledge and Data Engineering 20, no. 2 (February 2008): 172–188.
Breiger, Ronald L, Scott A Boorman, and Phipps Arabie. “An Algorithm for Clustering Relational Data with Applications to Social Network Analysis and Comparison with Multidimensional Scaling.” Journal of Mathematical Psychology 12, no. 3 (August 1, 1975): 328–383.
Brockmann, D., and D. Helbing. “The Hidden Geometry of Complex, Network-Driven Contagion Phenomena.” Science 342, no. 6164 (December 13, 2013): 1337–1342.
Callon, Michel, and John Law. “On Interests and Their Transformation: Enrolment and Counter-Enrolment.” Social Studies of Science 12, no. 4 (1982): 615–625. JSTOR: 284830.
Cartwright, Dorwin, and Frank Harary. “Structural Balance: A Generalization of Heider’s Theory.” Psychological Review (US) 63, no. 5 (1956): 277–293.
Chun, Wendy Hui Kyon. “Queerying Homophily.” In Pattern Discrimination, 59–98. In Search of Media Series. meson press, 2018.
DARPA. Anomaly Detection at Multiple Scale (ADAMS) – Broad Agency Announcement, October 22, 2010.
DeLanda, Manuel. Materialist Phenomenology: A Philosophy of Perception. Theory in the New Humanities. London: Bloomsbury academic, 2022.
De Sola Pool, Ithiel, and Manfred Kochen. “Contacts and Influence.” Social Networks 1, no. 1 (January 1, 1978): 5–51.
Eitan, Alex Tarnavsky, Eddie Smolyansky, Itay Knaan Harpaz, and Sahar Perets. “Connected Papers: Find and Explore Academic Papers,” 2022.
Ernaux, Annie. Simple Passion. London: Fitzcarraldo, 2021.
Fazi, M. Beatrice. Contingent Computation: Abstraction, Experience, and Indeterminacy in Computational Aesthetics. Media Philosophy. Lanham: Rowman & Littlefield International, 2018.
Forsyth, Elaine, and Leo Katz. “A Matrix Approach to the Analysis of Sociometric Data: Preliminary Report.” Sociometry 9, no. 4 (1946): 340–347. JSTOR: 2785498.
Fortunato, Santo. “Community Detection in Graphs.” Physics Reports 486, nos. 3-5 (February 2010): 75–174.
Fortunato, Santo, and Claudio Castellano. “Community Structure in Graphs.” In Computational Complexity: Theory, Techniques, and Applications, edited by Robert A. Meyers, 490–512. New York, NY: Springer, 2012.
Freeman, Linton. “Going the Wrong Way on a One-Way Street: Centrality in Physics and Biology.” Journal of Social Structure – JoSS, January 1, 2008.
Fruchterman, Thomas M. J., and Edward M. Reingold. “Graph Drawing by Force-Directed Placement.” Software: Practice and Experience 21, no. 11 (1991): 1129–1164.
Fuller, Matthew. “In Praise of Plasticity: Underspecification, Anarchism, Machine Learning.” In Data Publics. Routledge, 2020.
Fuller, Matthew, and Olga Goriunova. Bleak Joys: Aesthetics of Ecology and Impossibility. Posthumanities 53. Minneapolis ; London: University of Minnesota Press, 2019.
Gasparetti, Fabio, Giuseppe Sansonetti, and Alessandro Micarelli. “Community Detection in Social Recommender Systems: A Survey.” Applied Intelligence 51, no. 6 (June 1, 2021): 3975–3995.
Gephi. Gephi Tutorial Quick Start. March 5, 2010.
Girvan, M., and M. E. J. Newman. “Community Structure in Social and Biological Networks.” Proceedings of the National Academy of Sciences 99, no. 12 (June 11, 2002): 7821–7826.
Granovetter, Mark S. “The Strength of Weak Ties.” American Journal of Sociology 78, no. 6 (May 1973): 1360–1380.
Guo, Zhuang, Jiachao Zhang, Zhanli Wang, Kay Ying Ang, Shi Huang, Qiangchuan Hou, Xiaoquan Su, et al. “Intestinal Microbiota Distinguish Gout Patients from Healthy Humans.” Scientific Reports 6, no. 1 (1 2016): 20602.
Hagberg, Aric A., Daniel A. Schult, and Pieter J. Swart. “Exploring Network Structure, Dynamics, and Function Using NetworkX.” In Proceedings of the 7th Python in Science Conference (SciPy 2008), edited by Gaël Varoquaux, Travis Vaught, and Jarrod Millman, 11–15. Pasadena, CA USA, 2008.
Hage, Per, and Frank Harary. Structural Models in Anthropology. 1st ed. Cambridge University Press, February 24, 1984.
Harper, Richard, Eno Thereska, Siân Lindley, Richard Banks, Phil Gosset, William Odom, Gavin Smyth, and Eryn Whitworth. “What Is a File?” In 2013 Conference on Computer Supported Cooperative Work, 1125–1136. Microsoft Research, February 2013.
Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning. Springer Series in Statistics. New York: Springer New York, 2009.
Hobbs, Robert Carleton. Mark Lombardi: Global Networks. In collaboration with Independent Curators International. New York: Independent Curators International, 2004.
Holland, Paul W., Kathryn Blackmond Laskey, and Samuel Leinhardt. “Stochastic Blockmodels: First Steps.” Social Networks 5, no. 2 (June 1, 1983): 109–137.
Hui, Yuk. The Question Concerning Technology in China: An Essay in Cosmotechnics. Redacted by Robin Mackay. Urbanomic / Mono. Cambridge, MA, USA: Urbanomic, September 2, 2016.
Jacomy, Mathieu. “A Twitter Controversy about Community Detection: Empirical Material.” Reticular, December 12, 2021.
———. “Gephi Code Sustainability Retreat 2021: Debriefing.” Gephi blog, December 6, 2021.
———. “The Gephi Paper Gets the ICWSM Test of Time Award.” Gephi blog, June 12, 2019.
Javed, Muhammad Aqib, Muhammad Shahzad Younis, Siddique Latif, Junaid Qadir, and Adeel Baig. “Community Detection in Networks: A Multidisciplinary Review.” Journal of Network and Computer Applications 108 (April 15, 2018): 87–111.
Keuchenius, Anna, Petter Törnberg, and Justus Uitermark. “Adoption and Adaptation: A Computational Case Study of the Spread of Granovetter’s Weak Ties Hypothesis.” Social Networks 66 (July 1, 2021): 10–25.
Kluge, Alexander, and Oskar Negt. History and Obstinacy. Brooklyn, NY: Zone Books, 2014.
Lancichinetti, Andrea, and Santo Fortunato. “Community Detection Algorithms: A Comparative Analysis.” Physical Review E 80, no. 5 (November 30, 2009): 056117.
Latour, Bruno. The Pasteurization of France. First Harvard University Press paperback ed. Cambridge, Mass.: Harvard Univ. Press, 1993.
Law, John. “Technology, Closure and Heterogeneous Engineering: The Case of the Portuguese Expansion.” In The Social Construction of Technological Systems: New Directions in the Sociology and History of Technology, edited by Wiebe E. Bijker, Thomas Parke Hughes, and Trevor Pinch, 111–134. Cambridge, Mass: MIT Press, 1987.
Lee, Clement, and Darren J. Wilkinson. “A Review of Stochastic Block Models and Extensions for Graph Clustering.” Applied Network Science 4, no. 1 (1 2019): 1–50.
Lepore, Jill. If Then: How One Data Company Invented the Future. London: John Murray, 2020.
Luce, R. Duncan, and Albert D. Perry. “A Method of Matrix Analysis of Group Structure.” Psychometrika 14, no. 2 (June 1, 1949): 95–116.
Lury, Celia. Problem Spaces: How and Why Methodology Matters. Cambridge, UK ; Medford, MA: Polity Press, 2021.
Luxburg, Ulrike von, Robert C. Williamson, and Isabelle Guyon. “Clustering: Science or Art?” In Proceedings of ICML Workshop on Unsupervised and Transfer Learning, 65–79. JMLR Workshop and Conference Proceedings, June 27, 2012.
Mandelbrot, Benoı̂t B. The Fractalist: Memoir of a Scientific Maverick. First vintage books edition. New York: Vintage Books, 2013.
Marx, Karl. Capital: Volume I. In collaboration with David Fernbach. Translated by Ben Fowkes. v. 1: Penguin classics. London ; New York, N.Y: Penguin Books in association with New Left Review, 1981.
Mayer, Katja. “On the Sociometry of Search Engines: A Historical Review of Methods.” In Deep Search. The Politics of Search beyond Google, edited by Konrad Becker and Felix Stalder, 54–72. Edison, NJ: Transaction, December 9, 2009.
McAuley, Julian, and Jure Leskovec. “Discovering Social Circles in Ego Networks.” January 10, 2013. arXiv: 1210.8182 [physics].
McPherson, Miller, Lynn Smith-Lovin, and James M Cook. “Birds of a Feather: Homophily in Social Networks.” Annual Review of Sociology 27, no. 1 (2001): 415–444.
McQuillan, Dan. Resisting AI: An Anti-fascist Approach to Artificial Intelligence. BRISTOL: Bristol University Press, July 15, 2022.
Milgram, S. “The Small World Problem.” Psychology Today 2 (1967): 60–67.
Moreno, Jacob Levy. Who Shall Survive? A New Approach to the Problem of Human Interrelations. Washington: Nervous and Mental Disease Pub. Co., 1934.
Newell, Allen, and Herbert Alexander Simon. “The Logic Theory Machine–A Complex Information Processing System.” IRE Transactions on Information Theory 2, no. 3 (September 1956): 61–79.
Newman, M. E. J. “Modularity and Community Structure in Networks.” Proceedings of the National Academy of Sciences 103, no. 23 (June 6, 2006): 8577–8582.
———. Networks. Second edition. Oxford, United Kingdom ; New York, NY, United States of America: Oxford University Press, 2018.
Newman, M. E. J., Albert-László Barabási, and Duncan J. Watts, eds. The Structure and Dynamics of Networks. Princeton Studies in Complexity. Princeton: Princeton University Press, 2006.
Newman, M. E. J., and M. Girvan. “Finding and Evaluating Community Structure in Networks.” Physical Review E 69, no. 2 (February 26, 2004): 026113.
Noack, Andreas. “Modularity Clustering Is Force-Directed Layout.” Physical Review E 79, no. 2 (February 2, 2009): 026102.
Onnela, J.-P., J. Saramäki, J. Hyvönen, G. Szabó, D. Lazer, K. Kaski, J. Kertész, and A.-L. Barabási. “Structure and Tie Strengths in Mobile Communication Networks.” Proceedings of the National Academy of Sciences 104, no. 18 (May 2007): 7332–7336.
Pasquinelli, Matteo. “Anomaly Detection: The Mathematization of the Abnormal in the Metadata Society.” Panel presentation at Transmediale Festival, Berlin, Germany, 2015.
Peel, Leto, Daniel B. Larremore, and Aaron Clauset. “The Ground Truth about Metadata and Community Detection in Networks.” Science Advances 3, no. 5 (May 5, 2017): e1602548.
Peixoto, Tiago P. “Descriptive vs. Inferential Community Detection: Pitfalls, Myths and Half-Truths.” January 10, 2022. arXiv: 2112.00183 [physics, stat].
Polya, George. How to Solve It: A New Aspect of Mathematical Method. Princeton Science Library. Princeton, NJ: Princeton University Press, 2014.
Rieder, Bernhard. “What Is in PageRank? A Historical and Conceptual Investigation of a Recursive Status Index.” Computational Culture, no. 2 (September 28, 2012).
Rogers, Richard. Digital Methods. Cambridge, Massachusetts: The MIT Press, 2013.
Rossetti, Giulio, Letizia Milli, and Rémy Cazabet. “CDLIB: A Python Library to Extract, Compare and Evaluate Communities from Complex Networks.” Applied Network Science 4, no. 1 (1 2019): 1–26.
Rotman, Brian. “Towards a Semiotics of Mathematics.” In Mathematics as Sign: Writing, Imagining, Counting, 1–43. Stanford: Stanford University Press, 2000.
Russell, Legacy. Glitch Feminism: A Manifesto. London ; New York: Verso, 2020.
Sampson, Tony D. Virality: Contagion Theory in the Age of Networks. Minneapolis: University of Minnesota Press, 2012.
Schaub, Michael T., Jean-Charles Delvenne, Martin Rosvall, and Renaud Lambiotte. “The Many Facets of Community Detection in Complex Networks.” Applied Network Science 2, no. 1 (December 2017): 1–13.
Scott, John, and Peter J. Carrington, eds. The SAGE Handbook of Social Network Analysis. London ; Thousand Oaks, Calif: SAGE, 2011.
Sennett, Richard. The Craftsman. New Haven: Yale University Press, 2008.
Simon, Herbert Alexander. Models of Man: Social and Rational; Mathematical Essays on Rational Human Behavior in Society Setting. Wiley, 1957.
———. Models of My Life. 1st MIT Press ed. Cambridge, Mass: MIT Press, 1996.
———. “Rationality and Teleology.” In Reason in Human Affairs, 37–74. Stanford: Stanford University Press, 1983.
———. Reason in Human Affairs. Stanford: Stanford University Press, 1983.
———. The Sciences of the Artificial. 3rd ed. Cambridge, Mass: MIT Press, 1996.
Sohn-Rethel, Alfred. Intellectual and Manual Labour: A Critique of Epistemology. Critical Social Studies. London: Macmillan, 1978.
Song, Yi, and Stéphane Bressan. “Force-Directed Layout Community Detection.” In Database and Expert Systems Applications, edited by Hendrik Decker, Lenka Lhotská, Sebastian Link, Josef Basl, and A. Min Tjoa, 419–427. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, 2013.
Star, Susan Leigh. “This Is Not a Boundary Object: Reflections on the Origin of a Concept.” Science, Technology, & Human Values 35, no. 5 (September 2010): 601–617.
Star, Susan Leigh, and James R. Griesemer. “Institutional Ecology, ’Translations’ and Boundary Objects: Amateurs and Professionals in Berkeley’s Museum of Vertebrate Zoology, 1907-39.” Social Studies of Science 19, no. 3 (1989): 387–420. JSTOR: 285080.
Toscano, Alberto. “The Open Secret of Real Abstraction.” Rethinking Marxism 20, no. 2 (April 2008): 273–287.
Traag, V. A., P. Van Dooren, and Y. Nesterov. “Narrow Scope for Resolution-Limit-Free Community Detection.” Physical Review E 84, no. 1 (July 29, 2011): 016114.
Traag, V. A., L. Waltman, and N. J. van Eck. “From Louvain to Leiden: Guaranteeing Well-Connected Communities.” Scientific Reports 9, no. 1 (March 26, 2019): 5233.
Waddington, Conrad Hal. Tools for Thought. St. Albans: Paladin, 1977.
Wasserman, Stanley, and Katherine Faust. Social Network Analysis: Methods and Applications. 8. Cambridge ; New York: Cambridge University Press, 1994.
Watts, Duncan J., and Steven H. Strogatz. “Collective Dynamics of ‘Small-World’ Networks.” Nature 393, no. 6684 (6684 1998): 440–442.
Weiss, Robert S., and Eugene Jacobson. “A Method for the Analysis of the Structure of Complex Organizations.” American Sociological Review 20, no. 6 (1955): 661–668. JSTOR: 2088670.
Zhang, Guo, and Elin K. Jacob. “Community: Issues, Definitions, and Operationalization on the Web.” In Proceedings of the 21st International Conference on World Wide Web, 1121–1130. WWW ’12 Companion. New York, NY, USA: Association for Computing Machinery, April 16, 2012.
Zweig, Katharina Anna. Network Analysis Literacy: A Practical Approach to the Analysis of Networks. Lecture Notes in Social Networks. Wien: Springer, 2016.
Notes
- M. E. J. Newman et al., eds., The Structure and Dynamics of Networks, Princeton Studies in Complexity (Princeton: Princeton University Press, 2006). ↩
- Linton Freeman, “Going the Wrong Way on a One-Way Street: Centrality in Physics and Biology,” Journal of Social Structure – JoSS, January 1, 2008. ↩
- Robert Carleton Hobbs, Mark Lombardi: Global Networks, in collab. with Independent Curators International (New York: Independent Curators International, 2004). ↩
- Zhuang Guo et al., “Intestinal Microbiota Distinguish Gout Patients from Healthy Humans,” Scientific Reports 6, no. 1 (1 2016): 20602. ↩
- M. Girvan and M. E. J. Newman, “Community Structure in Social and Biological Networks,” Proceedings of the National Academy of Sciences 99, no. 12 (June 11, 2002): 7821–7826. ↩
- Vincent D. Blondel et al., “Fast Unfolding of Communities in Large Networks,” Journal of Statistical Mechanics: Theory and Experiment 2008, no. 10 (October 2008). ↩
- Trevor Hastie et al., The Elements of Statistical Learning, Springer Series in Statistics (New York: Springer New York, 2009). ↩
- Tony D. Sampson, Virality: Contagion Theory in the Age of Networks (Minneapolis: University of Minnesota Press, 2012). ↩
- It has for instance introduced pathways to certain kinds of mathematical objects whose development only took off with sufficient capacity of calculation. An example would be the development of a renewed interest in what came to be called fractals, (re)emerging with the PCs of the 1980s. Benoı̂t B. Mandelbrot, The Fractalist: Memoir of a Scientific Maverick, First vintage books edition (New York: Vintage Books, 2013) ↩
- Newman et al., The Structure and Dynamics of Networks. ↩
- Katja Mayer, “On the Sociometry of Search Engines: A Historical Review of Methods,” in Deep Search. The Politics of Search beyond Google, ed. Konrad Becker and Felix Stalder (Edison, NJ: Transaction, December 9, 2009), 54–72. ↩
- Bernhard Rieder, “What Is in PageRank? A Historical and Conceptual Investigation of a Recursive Status Index,” Computational Culture, no. 2 (September 28, 2012). ↩
- Santo Fortunato, “Community Detection in Graphs,” Physics Reports 486, nos. 3-5 (February 2010): 75–174. ↩
- Stanley Wasserman and Katherine Faust, Social Network Analysis: Methods and Applications, 8 (Cambridge ; New York: Cambridge University Press, 1994). ↩
- R. Duncan Luce and Albert D. Perry, “A Method of Matrix Analysis of Group Structure,” Psychometrika 14, no. 2 (June 1, 1949): p. 97 f. ↩
- Fortunato, “Community Detection in Graphs”; Robert S. Weiss and Eugene Jacobson, “A Method for the Analysis of the Structure of Complex Organizations,” American Sociological Review 20, no. 6 (1955): 661–668, JSTOR: 2088670. ↩
- Elaine Forsyth and Leo Katz, “A Matrix Approach to the Analysis of Sociometric Data: Preliminary Report,” Sociometry 9, no. 4 (1946): 340–347, JSTOR: 2785498; Jacob Levy Moreno, Who Shall Survive? A New Approach to the Problem of Human Interrelations. (Washington: Nervous and Mental Disease Pub. Co., 1934). ↩
- Dorwin Cartwright and Frank Harary, “Structural Balance: A Generalization of Heider’s Theory,” Psychological Review (US) 63, no. 5 (1956): 277–293. ↩
- Per Hage and Frank Harary, Structural Models in Anthropology, 1st ed. (Cambridge University Press, February 24, 1984). ↩
- Clement Lee and Darren J. Wilkinson, “A Review of Stochastic Block Models and Extensions for Graph Clustering,” Applied Network Science 4, no. 1 (1 2019): 1–50. ↩
- Ronald L Breiger et al., “An Algorithm for Clustering Relational Data with Applications to Social Network Analysis and Comparison with Multidimensional Scaling,” Journal of Mathematical Psychology 12, no. 3 (August 1, 1975): 328–383. ↩
- Paul W. Holland et al., “Stochastic Blockmodels: First Steps,” Social Networks 5, no. 2 (June 1, 1983): 109–137. ↩
- Wasserman and Faust, Social Network Analysis. ↩
- Hage and Harary, Structural Models in Anthropology. ↩
- Mayer, “On the Sociometry of Search Engines,” p. 54. ↩
- Ithiel de Sola Pool and Manfred Kochen, “Contacts and Influence,” Social Networks 1, no. 1 (January 1, 1978): 5–51. ↩
- S. Milgram, “The Small World Problem,” Psychology Today 2 (1967): 60–67. ↩
- Mark S. Granovetter, “The Strength of Weak Ties,” American Journal of Sociology 78, no. 6 (May 1973): 1360–1380. ↩
- Duncan J. Watts and Steven H. Strogatz, “Collective Dynamics of ‘Small-World’ Networks,” Nature 393, no. 6684 (6684 1998): 440–442. ↩
- Girvan and Newman, “Community Structure in Social and Biological Networks,” p. 7821, our emphasis. ↩
- The term ‘community’ was also coined as an alternative to ‘cluster’, a popular notion to describe groups of points in computer science, because the ‘clustering coefficient’ was already an established concept with a different meaning in network science. ↩
- M. E. J. Newman, Networks, Second edition (Oxford, United Kingdom ; New York, NY, United States of America: Oxford University Press, 2018) ↩
- The 2002 article by Girvan and Newman has become very influential in the field with 13,876 citations (as of May 2023) according to Semantic Scholar. Waleed Ammar et al., “Construction of the Literature Graph in Semantic Scholar,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 3 (Industry Papers) (New Orleans – Louisiana: Association for Computational Linguistics, 2018), 84–91 Moreover, Santo Fortunato further popularised the term ‘community’ with several reviews on the subject that have ‘community’ in their titles, Andrea Lancichinetti and Santo Fortunato, “Community Detection Algorithms: A Comparative Analysis,” Physical Review E 80, no. 5 (November 30, 2009): 056117; Fortunato, “Community Detection in Graphs”; Santo Fortunato and Claudio Castellano, “Community Structure in Graphs,” in Computational Complexity: Theory, Techniques, and Applications, ed. Robert A. Meyers (New York, NY: Springer, 2012), 490–512 where he also justifies the concept of community by referring to social networks as “paradigmatic examples of graphs with communities”. Fortunato, “Community Detection in Graphs ↩
- Newman et al., The Structure and Dynamics of Networks. ↩
- The popularity of Mark Granovetter’s “weak-ties argument”—the hypothesis that large-scale social network cohesion depends on weak links between different communities—among physicists has also contributed to their increased interest in network science and physicists referencing Granovetter “might be considered innovators in (the complex network) community”. Anna Keuchenius et al., “Adoption and Adaptation: A Computational Case Study of the Spread of Granovetter’s Weak Ties Hypothesis,” Social Networks 66 (July 1, 2021): p. 21 To test Granovetter’s hypothesis, physicists analysed community structures of real-world networks and, for example, Jukka- Pekka (JP) Onnela et al. showed that in mobile communication networks “removal of the weak links will delete the bridges that connect different communities”. J.-P. Onnela et al., “Structure and Tie Strengths in Mobile Communication Networks,” Proceedings of the National Academy of Sciences 104, no. 18 (May 2007): p. 7334 ↩
- Freeman, “Going the Wrong Way on a One-Way Street.” ↩
- M. E. J. Newman and M. Girvan, “Finding and Evaluating Community Structure in Networks,” Physical Review E 69, no. 2 (February 26, 2004): 026113; M. E. J. Newman, “Modularity and Community Structure in Networks,” Proceedings of the National Academy of Sciences 103, no. 23 (June 6, 2006): 8577–8582. ↩
- Fortunato, “Community Detection in Graphs.” ↩
- Tiago P. Peixoto, “Descriptive vs. Inferential Community Detection: Pitfalls, Myths and Half-Truths” (Jan- uary 10, 2022), arXiv: 2112.00183; Mathieu Jacomy, “A Twitter Controversy about Community Detection: Empirical Material,” Reticular, December 12, 2021. ↩
- Blondel et al., “Fast Unfolding of Communities in Large Networks.” ↩
- Fortunato, “Community Detection in Graphs,” p. 161. ↩
- Ammar et al., “Construction of the Literature Graph in Semantic Scholar.” ↩
- We notice that ‘friendship networks’ of scientists are present in the stories of the genealogy of the field. Therefore, a network analysis of the collaboration and institutional affiliation networks of researchers working on community detection would also be illuminating to disentangle the different lineages from physics and the social sciences. ↩
- Alex Tarnavsky Eitan et al., “Connected Papers: Find and Explore Academic Papers,” 2022. ↩
- Girvan and Newman, “Community Structure in Social and Biological Networks.” ↩
- Katharina Anna Zweig, Network Analysis Literacy: A Practical Approach to the Analysis of Networks, Lecture Notes in Social Networks (Wien: Springer, 2016). ↩
- Julian McAuley and Jure Leskovec, “Discovering Social Circles in Ego Networks” (January 10, 2013), arXiv:1210.8182. ↩
- Aric A. Hagberg et al., “Exploring Network Structure, Dynamics, and Function Using NetworkX,” in Proceedings of the 7th Python in Science Conference (SciPy 2008), ed. Gaël Varoquaux et al. (Pasadena, CA USA, 2008), 11–15. ↩
- For the sake of simplicity we only defined the simplest form of networks here, the undirected and unweighted graph, meaning that the edges between nodes have no orientation but are symmetric and all edges have the same importance. However, it is also common to direct the edges and to weight them by a number that signifies the strength or importance of the connection, see Zweig, Network Analysis Literacy for further information. ↩
- Fortunato, “Community Detection in Graphs.” ↩
- Blondel et al., “Fast Unfolding of Communities in Large Networks.” ↩
- Girvan and Newman, “Community Structure in Social and Biological Networks.” ↩
- See for an example of such use that is by no means unusual Guo Zhang and Elin K. Jacob, “Community: Issues, Definitions, and Operationalization on the Web,” in Proceedings of the 21st International Conference on World Wide Web, WWW ’12 Companion (New York, NY, USA: Association for Computing Machinery, April 16, 2012), 1121–1130. ↩
- Fortunato, “Community Detection in Graphs.” ↩
- Michael T. Schaub et al., “The Many Facets of Community Detection in Complex Networks,” Applied Network Science 2, no. 1 (December 2017): p. 1. ↩
- We refer to Schaub et al. for a close-reading of the underlying mathematical formalisation of the four different approaches to community detection. ↩
- Girvan and Newman, “Community Structure in Social and Biological Networks.” ↩
- Fortunato, “Community Detection in Graphs.” ↩
- Peixoto, “Descriptive vs. Inferential Community Detection.” ↩
- Newman, Networks, p. 498. ↩
- Blondel et al., “Fast Unfolding of Communities in Large Networks.” ↩
- Blondel et al. ↩
- Mathieu Bastian et al., “Gephi: An Open Source Software for Exploring and Manipulating Networks,” in Proceedings of the Third International Conference on Weblogs and Social Media, ICWSM 2009, San Jose, California, USA, May 17-20, 2009, ed. Eytan Adar et al. (The AAAI Press, 2009). ↩
- Gephi, Gephi Tutorial Quick Start (March 5, 2010). ↩
- Mathieu Jacomy, “The Gephi Paper Gets the ICWSM Test of Time Award,” Gephi blog, June 12, 2019. ↩
- Ammar et al., “Construction of the Literature Graph in Semantic Scholar.” ↩
- Giulio Rossetti et al., “CDLIB: A Python Library to Extract, Compare and Evaluate Communities from Complex Networks,” Applied Network Science 4, no. 1 (1 2019): 1–26. ↩
- V. A. Traag et al., “From Louvain to Leiden: Guaranteeing Well-Connected Communities,” Scientific Reports 9, no. 1 (March 26, 2019): 5233. ↩
- Mathieu Jacomy, “Gephi Code Sustainability Retreat 2021: Debriefing,” Gephi blog, December 6, 2021. ↩
- Newman and Girvan, “Finding and Evaluating Community Structure in Networks”; Newman, “Modularity and Community Structure in Networks.” ↩
- Blondel et al., “Fast Unfolding of Communities in Large Networks.” ↩
- Python code for the Louvain algorithm is available as part of the NetworkX package, see https://networkx.org/documentation/stable/modules/networkx/algorithms/community/louvain.html#louvain partitions ↩
- The aggregation of edges in the meta-network is a non-trivial step that we cannot present in full detail here. In principal, edges within communities are aggregated to self-loops of the meta-nodes, where a self-loop refers to an edge starting and ending at the same node, and edges between communities are aggregated to edges between meta-nodes. However, the aggregation requires a weighting of the edges in order to represent the different edge densities correctly. We refer the reader to the original article for more detail. Blondel et al., “Fast Unfolding of Communities in Large Networks” ↩
- Thomas M. J. Fruchterman and Edward M. Reingold, “Graph Drawing by Force-Directed Placement,” Software: Practice and Experience 21, no. 11 (1991): 1129–1164. ↩
- Yi Song and Stéphane Bressan, “Force-Directed Layout Community Detection,” in Database and Expert Systems Applications, ed. Hendrik Decker et al., Lecture Notes in Computer Science (Berlin, Heidelberg: Springer, 2013), 419–427. ↩
- Andreas Noack, “Modularity Clustering Is Force-Directed Layout,” Physical Review E 79, no. 2 (February 2, 2009): 026102. ↩
- We note that the colour gradient used in Figure 1 is unfortunately very fine due to the high number of communities. This can make the visual differentiation of communities challenging. ↩
- Hastie et al., The Elements of Statistical Learning. ↩
- Fortunato, “Community Detection in Graphs.” ↩
- V. A. Traag et al., “Narrow Scope for Resolution-Limit-Free Community Detection,” Physical Review E 84, no. 1 (July 29, 2011): 016114. ↩
- Newman and Girvan, “Finding and Evaluating Community Structure in Networks”; Newman, “Modularity and Community Structure in Networks.” ↩
- Zweig, Network Analysis Literacy. ↩
- Blondel et al., “Fast Unfolding of Communities in Large Networks.” ↩
- Roland Barthes, S/Z, 1st American ed., trans. Richard Miller (New York: Hill and Wang, 1974). ↩
- Lawrence Alloway, “Eduardo Paolozzi,” October 136 (2011): 29–31, JSTOR: 23014863. ↩
- Susan Leigh Star, “This Is Not a Boundary Object: Reflections on the Origin of a Concept,” Science, Technology, & Human Values 35, no. 5 (September 2010): 601–617. ↩
- Star, pp. 604-5, capitalisation in original. ↩
- Star, p. 607. ↩
- Susan Leigh Star and James R. Griesemer, “Institutional Ecology, ’Translations’ and Boundary Objects: Amateurs and Professionals in Berkeley’s Museum of Vertebrate Zoology, 1907-39,” Social Studies of Science 19, no. 3 (1989): 387–420, JSTOR: 285080. ↩
- John Law, “Technology, Closure and Heterogeneous Engineering: The Case of the Portuguese Expansion,” in The Social Construction of Technological Systems: New Directions in the Sociology and History of Technology, ed. Wiebe E. Bijker et al. (Cambridge, Mass: MIT Press, 1987), p. 111. ↩
- Michel Callon and John Law, “On Interests and Their Transformation: Enrolment and Counter-Enrolment,” Social Studies of Science 12, no. 4 (1982): 615–625, JSTOR: 284830. ↩
- Richard Harper et al., “What Is a File?,” in 2013 Conference on Computer Supported Cooperative Work (Microsoft Research, February 2013), p. 4. ↩
- Brian Rotman, “Towards a Semiotics of Mathematics,” in Mathematics as Sign: Writing, Imagining, Counting (Stanford: Stanford University Press, 2000), p. 5. ↩
- Richard Rogers, Digital Methods (Cambridge, Massachusetts: The MIT Press, 2013). ↩
- Alexander Kluge and Oskar Negt, History and Obstinacy (Brooklyn, NY: Zone Books, 2014). ↩
- Manuel DeLanda, Materialist Phenomenology: A Philosophy of Perception, Theory in the New Humanities (London: Bloomsbury academic, 2022). ↩
- Richard Sennett, The Craftsman (New Haven: Yale University Press, 2008). ↩
- M. Beatrice Fazi, Contingent Computation: Abstraction, Experience, and Indeterminacy in Computational Aesthetics, Media Philosophy (Lanham: Rowman & Littlefield International, 2018). ↩
- Alfred Sohn-Rethel, Intellectual and Manual Labour: A Critique of Epistemology, Critical Social Studies (London: Macmillan, 1978). ↩
- Alberto Toscano, “The Open Secret of Real Abstraction,” Rethinking Marxism 20, no. 2 (April 2008): 273– 287. ↩
- Karl Marx, Capital: Volume I, in collab. with David Fernbach, trans. Ben Fowkes, v. 1: Penguin classics (London ; New York, N.Y: Penguin Books in association with New Left Review, 1981). ↩
- Fabio Gasparetti et al., “Community Detection in Social Recommender Systems: A Survey,” Applied Intelligence 51, no. 6 (June 1, 2021): 3975–3995. ↩
- Gasparetti et al. ↩
- Muhammad Aqib Javed et al., “Community Detection in Networks: A Multidisciplinary Review,” Journal of Network and Computer Applications 108 (April 15, 2018): 87–111. ↩
- 106. Gasparetti et al., “Community Detection in Social Recommender Systems.” ↩
- Dan McQuillan, Resisting AI: An Anti-fascist Approach to Artificial Intelligence (BRISTOL: Bristol Univer- sity Press, July 15, 2022). ↩
- Conrad Hal Waddington, Tools for Thought (St. Albans: Paladin, 1977). ↩
- Herbert Alexander Simon, “Rationality and Teleology,” in Reason in Human Affairs (Stanford: Stanford University Press, 1983), 37–74. ↩
- Sohn-Rethel, Intellectual and Manual Labour. ↩
- Yuk Hui, The Question Concerning Technology in China: An Essay in Cosmotechnics, red. Robin Mackay, Urbanomic / Mono (Cambridge, MA, USA: Urbanomic, September 2, 2016). ↩
- Miller McPherson et al., “Birds of a Feather: Homophily in Social Networks,” Annual Review of Sociology 27, no. 1 (2001): 415–444. ↩
- Wendy Hui Kyon Chun, “Queerying Homophily,” in Pattern Discrimination, In Search of Media Series (meson press, 2018), 59–98. ↩
- Matteo Pasquinelli, “Anomaly Detection: The Mathematization of the Abnormal in the Metadata Society,” Panel presentation at Transmediale Festival, Berlin, Germany, 2015, ↩
- Pasquinelli, p. 6. ↩
- Leman Akoglu et al., “Graph-Based Anomaly Detection and Description: A Survey” (April 28, 2014), arXiv: 1404.4679. ↩
- John Scott and Peter J. Carrington, eds., The SAGE Handbook of Social Network Analysis (London ; Thousand Oaks, Calif: SAGE, 2011). ↩
- DARPA, Anomaly Detection at Multiple Scale (ADAMS) – Broad Agency Announcement, October 22, 2010, p. 2f. ↩
- Jill Lepore, If Then: How One Data Company Invented the Future (London: John Murray, 2020). ↩
- Matthew Fuller and Olga Goriunova, Bleak Joys: Aesthetics of Ecology and Impossibility, Posthumanities 53 (Minneapolis ; London: University of Minnesota Press, 2019). ↩
- Blondel et al., “Fast Unfolding of Communities in Large Networks,” p. 1. ↩
- Blondel et al. ↩
- Ulrik Brandes et al., “On Modularity Clustering,” IEEE Transactions on Knowledge and Data Engineering 20, no. 2 (February 2008): 172–188. ↩
- Traag et al., “From Louvain to Leiden.” ↩
- George Polya, How to Solve It: A New Aspect of Mathematical Method, Princeton Science Library (Princeton, NJ: Princeton University Press, 2014). ↩
- Herbert Alexander Simon, Models of Man: Social and Rational; Mathematical Essays on Rational Human Behavior in Society Setting (Wiley, 1957). ↩
- In his memoir, Simon notes that his long-term collaborator, Allan Newell, who was a student of Pólya’s introduced him to the term. See, Herbert Alexander Simon, Models of My Life, 1st MIT Press ed (Cambridge, Mass: MIT Press, 1996) ↩
- Simon, Models of Man, p. 205. ↩
- Simon, p. 205. ↩
- Herbert Alexander Simon, Reason in Human Affairs (Stanford: Stanford University Press, 1983). ↩
- In military-funded work designed to address the construction of the automatic proof of logical statements Simon writes with Allen Newell to affirm that, “all we are concerned with is that we have some criteria that ‘work’ ”. Allen Newell and Herbert Alexander Simon, “The Logic Theory Machine–A Complex Information Processing System,” IRE Transactions on Information Theory 2, no. 3 (September 1956): p. 69 The pair further reinforce the position by arguing that, “The method is a heuristic one, for it employs cues, based on the characteristics of the theorem to be proved, to limit the range of its search; it does not systematically enumerate all proofs. This use of cues represents a great saving in search, but carries the penalty that a proof may not in fact be found. The test of a heuristic is empirical: does it work?” Newell and Simon, p. 71 A crucial part of the context within which satisficing must occur are the available quantities of computational resource and time, but also of the problem of trying to get something done to push forward a research agenda in a generally productive direction. ↩
- Celia Lury, Problem Spaces: How and Why Methodology Matters (Cambridge, UK ; Medford, MA: Polity Press, 2021). ↩
- Herbert Alexander Simon, The Sciences of the Artificial, 3rd ed (Cambridge, Mass: MIT Press, 1996), Chapter 2. ↩
- Fruchterman and Reingold, “Graph Drawing by Force-Directed Placement.” ↩
- Matthew Fuller, “In Praise of Plasticity: Underspecification, Anarchism, Machine Learning,” in Data Publics (Routledge, 2020). ↩
- D. Brockmann and D. Helbing, “The Hidden Geometry of Complex, Network-Driven Contagion Phenomena,” Science 342, no. 6164 (December 13, 2013): 1337–1342. ↩
- Blondel et al., “Fast Unfolding of Communities in Large Networks.” ↩
- Ulrike von Luxburg et al., “Clustering: Science or Art?,” in Proceedings of ICML Workshop on Unsupervised and Transfer Learning(JMLR Workshop and Conference Proceedings, June 27, 2012), 65–79. ↩
- Fortunato and Castellano, “Community Structure in Graphs.” ↩
- Leto Peel et al., “The Ground Truth about Metadata and Community Detection in Networks,” Science Advances 3, no. 5 (May 5, 2017): e1602548. ↩
- Annie Ernaux, Simple Passion (London: Fitzcarraldo, 2021), p.25. ↩
- Legacy Russell, Glitch Feminism: A Manifesto (London ; New York: Verso, 2020). ↩
- This image of the pipeline should not be taken in an ethnographic sense, or one that endorses any hierarchy of knowledge or practices, but simply as an illustration of another kind of diagram, of socio-technical relations and practices. Actual conditions can involve more branching and looping, returning to a means to recognise the way a calculation comes into being through what it comes into composition with in the condition of emergence of a graph. ↩
- Amnesty International UK, Trapped in the Matrix: Secrecy, Stigma, and Bias in the Met’s Gangs Database (London: Amnesty International UK, May 2018). ↩
- Bruno Latour, The Pasteurization of France, First Harvard University Press paperback ed (Cambridge, Mass.: Harvard Univ. Press, 1993). ↩
- Simon, The Sciences of the Artificial. ↩