To exist is to be indexed by a search engine.
Introna & Nissenbaum, 20001
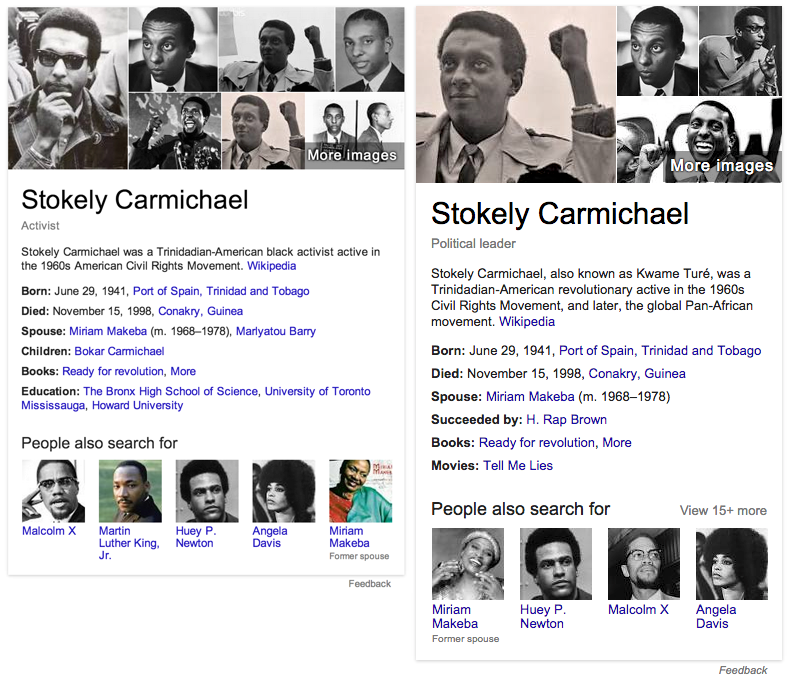
Figure 1: Google’s Knowledge Graphs for Stokely Carmichael, c. March, 2014 (Left) and c. September, 2015 (Right)
On May 16th, 2012, Google officially announced the launch of its Knowledge Graph. In the announcement, Google wrote that the Knowledge Graph was introduced to help users “discover new information quickly and easily” and thus satisfy “the basic human need to learn and broaden your horizons.” 2 Google described the Knowledge Graph as able to understand “real-world entities and their relationships to one another,” noting that entities in the knowledge graph were no longer strings – i.e., arbitrary data values in table strings – but instead were things. 3 At its launch, the graph contained information on over 500 million real-world entities and over 3.5 billion facts about their relationships with one another, all extracted from public sources like Freebase, Wikipedia, and the CIA World Factbook. Further, the Knowledge Graph was able to understand which real-world objects your query pertained to – and understand them “the way you do” – and to summarize the most important and relevant relationships that each entity had with other entities. Users could click on any of the related entities in their results and create a new graph of the entities most importantly and relevantly related to them, and thus facilitate discovery, or what is often referred to as ‘serendipitous search’. And finally, based on users’ interactions with either the Knowledge Graph itself or your normal search results, it was able to learn whether it had presented the right entity, and whether it had properly determined the importance and relevance of that entity’s relationships with other entities. 4
The Knowledge Graph was implemented in accordance with one of Google’s foundational principles: “[I]nvariably, simple models and a lot of data trump more elaborate models based on less data.” 5 The driving idea was that the Web was a gigantic repository of knowledge reducible to expository statements of fact, and that all of this factual knowledge contained on the Web could be captured in the form of a particular n-ary tuple, the triple, which is essentially a subject-predicate-object statement. This knowledge was, and still is, largely articulated in natural language. Google thus needed its system to be able to parse semantic content, extract the subjects, predicates, and objects of expository statements, and translate them into machine-readable triples for storage in its database. In order to extract this information at scale, they further had to develop machine learning techniques that began with simple models, applied them to large semantic ‘corpuses,’ automatically and iteratively complexified their models, and were eventually able to learn how to recognize and classify entities and the relations between them, as well as types of entities and types of relations between them.
This paper argues that this process constitutes a machinic rhetoric, by which increasingly autonomous machines are capable of producing their own discursive knowledge-formations, which have aesthetic, ethical, and political implications. In particular, the Knowledge Graph results in what I term the n-arization of thought, which delimits the space of invention and knowledge-production to that which can be made to fit the pattern of its data structure. Graph data is most often structured by what is termed a “triple.” A triple is a relation between two entities all stored in a database, and is most commonly understood as a subject-predicate-object statement. Here, the existence of entities and relations between them are quite literally dependent upon their indexability. The first section of this paper works to adapt rhetorical theory to the critique of new media, and, in particular, posits the existence of a machinic rhetoric. Sections two through five examine the technologies behind Google’s Knowledge graph, moving from the semantic web, to Pregel, to Information Extraction web crawlers, to Google’s TextRunner in particular. The sixth and final section extends an initial critique of Google’s Knowledge graph and articulates some of its potential implications.
Towards a Machinic Rhetoric
Throughout the iterations of this paper, I have engaged in repeated struggle with the simple question: why rhetoric? Put most simply, rhetorical criticism can establish the argumentative structure of any given statement, and thus illuminate the power of and knowledge within the discourse from which that given statement arose. This is because the power/knowledge of any given discourse is itself created by and through its articulation, an idea now held by a significant number of rhetorical scholars. 6 Rhetorical criticism has a long tradition of analyzing and classifying what Richard Lanham describes as “the patterns of speech or writing that provide patterns for thought.” 7 Here an articulation is always patterned, both by the selection of what is – and thus also what is not – to be articulated and by the grammar of its particular medium and mode of expression. The pattern of this articulation subsequently provides the pattern for thought and action in relation to what was articulated, and as such, can be understood as persuading the thinker or actor to comport him or herself towards the articulated in accord with the articulation. We might thus think of a discourse as the grammar that provides patterns for articulating our thoughts and actions in a world. Such a discourse would also include articulations about articulation – or what we might term ‘meta-articulations’ – that exert a persuasive force over future articulations. These meta-articulations constitute a discourse’s grammar, and thus help delimit the range of potential articulations within that discourse, thus ensuring coherency and consistency, but at the expense of foreclosing articulations inconsistent or incoherent to the discourse. As such, the rhetorical component of these meta-articulations would be productive of an entire metaphysics: an aesthetic, an ethic, an epistemology, an ontology. We can thus understand rhetoric to be an inventive force that is mobilized to produce, maintain, and continually update the way we think about and understand the world. In this case, rhetoric can highlight the argumentative force of n-arization, the way its foundational elements – n-ary tuples, and here, triples – make claims about the world and what we can know about it. This is the necessary basis upon which we can investigate how those claims can operate in aggregate to produce particular ontologies, schemas, epistemologies, aesthetics, and politics.
This is a particularly useful tool for a critical code studies that, by its very object, must become speculative. The Knowledge Graph’s database and parsing API are intensely guarded secrets, only to be engaged through blackbox secretions: input data, output information, and publications of code or module fragments scrubbed of internal modifications. Notably, these take the form of articulations and meta-articulations, precisely the objects of rhetorical criticism. Yet rhetoric’s traditional focus on spoken and written (natural human) language needs to be expanded in order to maintain its critical utility in the wake of new media like Google’s Knowledge Graph, a reimagining that many scholars have called for. Lev Manovich argues that rhetoric continually finds itself declining to the point of irrelevance in the wake of new media. 8 While Manovich himself seems inclined to abandon rhetoric, and is often interpreted as explicitly encouraging said abandonment, he does note that any useful revitalization of rhetoric for the digital would likely “have less to do with arranging information in a particular order and more to do simply with selecting what is included and what is not included in the total corpus presented.” 9 However, Manovich offers no such reimagining of rhetorical studies. A number of rhetorical scholars have disagreed with Manovich’s critique of rhetorical studies and/or attempted to reformulate rhetorical critique in light of the media technologies from which Manovich derives his criticism. 10 In Lingua Fracta, Collin Gifford Brooke attempts a reimagining of the rhetorical canons for new media analysis. He writes, “with new media that traditional understanding of arrangement as sequence is more productively conceptualized as arrangement as pattern.” 11 For Brooke, arrangement as pattern is the best way to articulate the interactions between discourse and space in new media, an event that occurs in the practices we employ to “make sense” of new media. This idea of pattern, which is much more flexible than that of sequence, allows for a better critical understanding of digital knowledge production.
It is common across new media scholarship to situate new media within the social need to create ever-faster and scalable technologies for navigating the exponentially increasing amount of data available to us. 12 One of the primary ways of accommodating this need is the production of databases, which are essentially structured collections of data that, as Manovich explains, allow for quick access, sorting, and reorganizations at scale of a range of media types, with the capacity for multiple indexes, meta-data, and dynamic fields for the input of user-defined values. 13 In contrast to the sequential logic of spoken and written language, Manovich argues that there is nothing in the logic of databases themselves that would foster the generation of a narrative. 14 He argues, “As a cultural form the database represents the world as a list of items, and it refuses to order this list,” and, as such, “narrative becomes just one method of accessing data among many.” 15
Reversing the previous narrative relationship of spoken and written words, databases make paradigmatic choices through the models by which they collect and store data, which are given material existence, whereas the potential syntagmatic choices by which those data may be articulated into a linear narrative is rendered virtual and held in reserve. 16 Here the syntagmatic arrangement of data into human-knowable information is generated on the fly by a user-interface interaction, while the paradigmatic choices are preset to the extent that they are determined by the module that processes and stores data in the database initially. Thus data structures here present us with a mediated knowledge both of human experience and of complex interrelations between empirical entities that would otherwise be unknowable. This mediation is the result of any given system’s particular paradigmatic patterns of selecting, stressing, marking, effacing, and storing data, as well as the interfaces by which that data is translated into information that can be known, experienced, and interacted with by humans. 17 As Victoria Vesna writes, “Data are the raw forms that are shaped and used to build architectures of knowledge.” 18 I call this mediation n-arization, and understand its architecture of knowledge through my concept of the n-arization of thought. As we’ll see, here the entire systemic production of knowledge is n-arized in accord with the triple.
It is telling that Marius Paşca, a Senior Research Scientist in Google’s Research Group, explicitly employs terms for speech acts to describe our interactions with search algorithms and databases. Paşca understands web documents as ‘expository statements’ or ‘facts,’ search queries as ‘interrogations,’ and most importantly, relationships between entities as ‘“hidden” arguments,’ with their own implicit typologies. 19 It is important to note that a machine – and here I employ that term to refer to any individual piece or combination of hardware, software, or bulk synchronous processing mechanisms that span the two – understands all relationships to be facts, and all facts to be probabilistic. The triple is the basic structure by which the machine can n-arize these facts about entities’ interrelations, and the ‘hidden’ arguments about the typologies of those relations. The probability of any fact’s truth, or its ‘confidence value,’ is calculated on the fly based on the particular perspective produced by the path being taken through the data. These perspectives can be produced based on a wide variety of protocols, ranging from input seeds and machine learning to pivots in relational databases to named graphs or entities in graph databases. Thus, the machine here is no longer a true/false machine, a (0,1) machine. It employs fuzzy logic to assign confidence values between (0, …, 1) to each relational fact based on perspective, and, upon query, for instance, the machine ranks potential answers’ suitability to the query based on these confidence values.
William Harpine has set out to bracket objectivity from rhetorical criticism, arguing that rhetoricians have long held that rhetoric establishes the probable – rather than necessary – truth of claims. 20 This is precisely what such a machine does in responding to a query. When queried – especially in natural language – the machine chooses the relation that it has determined has the highest probability of matching the request, attempts to verify it, and then serves it up. In serving this particular relationship, the machine has made an argument. It argues not only that the relationship it serves up exists, but also that it is the best response to the particular query at hand. However, more interestingly, because these arguments have their own typologies, the machine has not only produced an argument about a single relationship and its query. The machine also makes an argument about all relationships, about argumentation and articulation itself: a meta-articulation. As we’ll see in the case of Google’s Knowledge Graph and in the semantic web more broadly, this is nowhere so true as in the case of extracted, iterative, and machine learned ontologies, where – given a modest number of seed relations – the machine is able to learn how to extract patterns, construct relations between relations, typologies of relations, relations between typologies of relations, and thus finally, an ontology itself.
Here machines are iteratively learning to produce their own structured experiences of their world. The world which they have learned to experience is a ‘corpus’ of hundred of billions of Web documents. This machinic ontology already contains trillions of signs, billions of relations, and thus differentially probable facts, and tens of millions of entities that these machines have learned (in)to exist(ence). They have learned to produce their own aesthetic for signification, called a schema and identification, respectively, which employs things like values, types, and keys for nesting processes capable of producing classificatory typologies ranging from absolute specifics and human-knowable literals to the most abstract conceptual generalities. And they have learned to produce their own ethic, as their iteratively produced ontological axioms create a schematic axiology for the computation, attribution, and correlation of values. I take all of this to be evidence of the birth of a machinic rhetoric and the agency of increasingly autonomous rhetorical machines. And it is precisely their n-arized form of knowledge that is made available to us and is increasingly being positioned as the future of thought, specifically in terms of our practices of making sense of the digital.
Typed Links, Metadata, and the Semantic Web
As early as the first World Wide Web Conference in 1994, Tim Berners-Lee was arguing that semantics were the future of the web. In his plenary talk, Berners-Lee said, “Adding semantics to the web involves two things: allowing documents which have information in machine-readable forms, and allowing links to be created with relationship values. Only when we have this extra level of semantics will we be able to use computer power to help us exploit the information to a greater extent than our own reading.” 21 In a canonical article co-authored with James Hendler and Ora Lassila, Berners-Lee would go on to argue, “The Semantic Web will enable machines to comprehend semantic documents and data, not human speech and writings.” 22 For Google Researchers, it is unfruitful to debate whether or not this vision of the semantic web meets different disciplinary interpretations of semantics. What is essential is that the semantic web operates by producing typed links and metadata. 23 Thus, Google’s vision of the semantic web is one in which machines learn to translate certain structures of the web into machinic knowledge. This machinic knowledge is always an argument about what entities and relationships between them on the web are knowable – in short, about what constitutes knowledge – and this argument is always structured by the link typology and metadata that the given machine is programmed to extract. Here the machine is producing an entire world – an ontology, epistemology, aesthetic, ethic, and politic – in large part by and for itself, and therefore, by and for machines in general. At its most basic, typed links and metadata are the bedrock of n-arized thought in graph databases, and they serve as the a priori knowledge claims that found the form of the triple.
At Google, the typology of links is the defining characteristic of the semantic web. They describe the difference mathematically as follows: “A network can be defined as a structure G = (V, E), consisting of a set of nodes (or vertices) V and a set of links (or edges) E ⊆ V x V that connect the nodes,” whereas “A semantic network […] Gm = (V, E) consists of a set of nodes V and a set of link sets E={E1, …, Et}, where Ej ⊆V x V (j=1, …, t). Each link set in E represents a relation of a different type or category. There are t link sets or link types in the network.” 24 Further, these edges are vectors, such that ∀E = ?n (Vn , Vn+1). This is because edges represent relationships, and two interlinked vertices might have different types of relationships with one another. The fact that edges in the semantic web are directional creates a particular structure for all relationships. Having roots in first-order predicate logic, this structure is essentially a subject-predicate-object statement. The subject is the vertex from which the edge issues, the predicate is the particular type of edge, and the object is the vertex at which the edge terminates. Take for example the following triple: subject{Stokely Carmichael} predicate{WasBornInCity} object{Port of Spain}. One can easily see here why an edge must be directed. If the same predicate (i.e., edge type) were preserved for the inverse, it would state: subject[Port of Spain] predicate{WasBornInPlace} object{Stokely Carmichael}. This statement is nonsensical. What it ought to state is something like: subject{Port of Spain} predicate{IsBirthPlaceOf} object{Stokely Carmichael}.
The fundamental data structure here requires three pieces of data, two vertices and a (vector) edge, which serve as a subject-predicate-object statement. Databases store statements like these as n-ary tuples. In mathematics and computer science – as well as linguistics and analytic philosophy – a tuple is simply an ordered sequence or list of n items, as opposed to a set, which is unordered. As the building blocks of the database, these tuples n-arize its knowledge production by their very form. A tuple containing three items is referred to as a ‘triple’. While triples may seem all too simplistic to capture the semantic activity on the Web, they actually can become quite complex in aggregate. Triples can form sets when they share common vertices, and these sets are referred to as ‘graphs.’ 25 In a graph, each vertex and each edge is assigned an identifier, such as a Uniform Resource Identifier (URI) or an International Resource Identifier (IRI), and it is these identifiers that actually stand in for the subject, type of predicate, 26 and object in any given triple. The primary purpose of these identifiers is to make graphs machine-readable, and what the machine actually reads is a tuple of three of these identifiers. Thus, the most basic unit of the machinic epistemology here is essentially a constative claim, a subject-predicate-object statement. There is an implicit argument that these triples are the building blocks of all knowledge, and in combination, the complex graphs that occur between a large number of them can produce the answer to any query.
One of the most important affordances of identifiers in graphs is the join function, which merges any two triples, or any two sets of triples, that have an identified vertex in common into a single graph. There are, however, two things that can be present in a graph without their own identifiers. The first is called a ‘literal,’ which is generally an unidentified alphanumeric string that makes more sense to humans – such as the characters in the name [Stokely Carmichael] or his date of birth [June 29, 1941] – which can only ever serve as a vertex in a triple. Literals are often marked up with a datatype to make them machine-readable, and often serve as the more human friendly output of graphs upon being queried. The second is called a ‘blank node,’ and can serve as an intermediary between two triples, functioning at once as the object of the first triple and the subject of the second. The W3C Working Group writes, “Blank nodes are like simple variables in algebra; they represent some thing without saying what their value is.” 27 They also provide an example, reproduced in Figure 2.
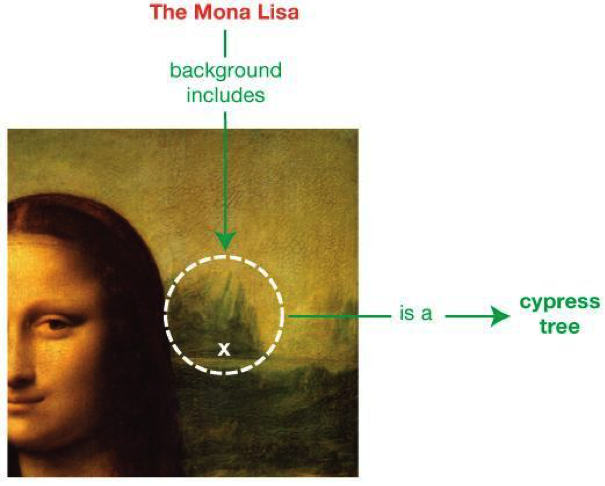
Figure 2: W3C Example of Blank Node 28
These blank nodes drastically increase the flexibility of graphs to capture semantic content in triples by producing a bridging vertex that connects two identified vertices by a two-edge path. Without literals and blank nodes, one might easily critique graph databases as being much too limited for producing elaborate statements and complex knowledge. Their reliance on reaching a critical mass of entities or relation types in order to produce genera that these singular entities and relations might be subsumed under and identified by would serve as a stumbling block to their ability to produce new knowledge. However, here we can see that when an unknown entity or relation impinges on the machine’s epistemic production, it can appropriate that entity or relation by bracketing its identity, allowing it to serve, however temporarily, as a known unknown, or a not-yet-known. It is in this way that the machinic epistemology is dynamized and is afforded the capacity to continually expand the frontiers of its epistemology into the unknown as not-yet-known, which, as I’ll return to later on, is done with a peculiar and unsettling violence.
Semantic web metadata is precisely this assignation of identifiers to graphed vertices and edges. Jane Greenberg describes metadata as “structured data about an object that supports functions associated with the designated [vertex].” 29 These functions can be radically diverse and specific to the life of whatever vertex they designate. 30 As Miguel-Angel Sicilia notes, “Structure in metadata entails that information is organised systematically, and this is nowadays primarily achieved by the use of metadata schemas.” 31 The systematicity behind structured metadata is produced and ensured by schemas and ontologies, which themselves are nothing but more metadata in the form of metamodels or meta-metadata, if you will.
A schema is what is used to write an ontology, and an ontology is what recursively gives meaning to the schema that was used to write it. In the case of the semantic Web, a schema is what ensures consistency in the form of representation. For example, in the case of a single edge type, a schema ensures that its identifiers across all its instances in a graph are uniform. An ontology, on the other hand, is what determines what can and is to be represented, by which identifiers, what it means to be that particular represented thing or that particular identifier, and how these identifiers can be used, and specifically combined. It transforms formal consistency into conceptual consistency. 32 In the previous example, an ontology is what determines which relationships constitute edges, which edges ought to receive that uniform identifier, what it means to be an edge of that type, and what vertices and paths that edge can interact with. 33
Thomas Gruber writes, “A body of formally represented knowledge is based on a conceptualization: the objects, concepts, and other entities that are presumed to exist in some area of interest and the relationships that hold them… An ontology is an explicit specification of a conceptualization…. For knowledge-based systems, what ‘exists’ is exactly that which can be represented.” 34 In the case of database query, an ontology is the pattern that determines which answers are presented, and to which a query must conform in order to elicit those answers. In order to function coherently and consistently, the entire system must either commit to a singular ontology, including its meta-arguments about what types of objects exist and how they can be related, or an intermediating system must be developed that can translate metadata between ontologies, this latter option being less desirable in its potential introduction of latency and/or error. However, commitment to a single ontology does not necessitate a data closure or completeness, 35 and this is primarily for two reasons that will be demonstrated in the next two sections. First, implicit data can always be parsed and reorganized into new information, and graph databases are particularly good at this. Google’s graph database uses a variety of functions to query its data, modify, add or delete vertices and edges, locate paths through and regions of its graph, aggregate specific vertices and edges to collectively perform operations, and to mutate its graph topology to accommodate a desired perspective. Second, an ontology can be produced, maintained, and updated iteratively via machine learning techniques. Here you might think of an ontology as a ‘living document,’ whose vocabulary and schema can be continually reinterpreted, remodeled, expanded, etc. Google has developed a series of sophisticated Web crawlers to perform automated Information Extraction (IE), included in which are Named-Entity Recognition (NER) and Relation Extraction (RE). These algorithms are capable of maintaining an iterative database, schema, and ontology by continually crawling the Web for new entities and new types of relations between entities, as well as new abstracted typologies of entities and relations between them.
Here we can see that the machinic epistemology is no longer quite so simple as assembling a gigantic index of singular facts that can be supplied when specifically queried. The centerpiece of a machinic epistemology is not the literals that are related, but instead is the genera that it is able to iteratively learn and extract into an epistemic schema and ontology. The machine here produces an entire taxonomy, a classificatory graph differentiated by identifiers of entity and relationship types. It is important to note here that all of this is afforded only atop the statistical analysis of triples at Web scale, and thus the entire schema and ontology are n-arized in accordance with that form. What the graph gains by this practice is the possibility for analogical knowledge, whereby genera are leveraged to calculate similarities between any singular entities or relations. What it loses in exchange is knowledge of the singularity of each entity and relation in its absolute specificity. And further, each detected entity and relation between entities must either be classified according to the machine’s schema and ontology, or bracketed until such a time when the machine learns a new classification for the bracketed entity or relation and adjusts its schema and ontology such that it can extract and appropriate knowledge from the not-yet-known.
Pregel, a Graph Database at Web Scale
While Google has not yet confirmed public speculation, it is largely assumed that its Knowledge Graph is powered by Pregel, Google’s graph database. 36 Pregel is named after the river in the historical mathematical problem ‘The Seven Bridges of Königsberg,’ whose solution by Leonhard Euler led to the foundations of graph theory. As Google has publicly acknowledged, Pregel was inspired by Leslie Valiant’s proposal for a Bulk Synchronous Parallel (BSP) Model for abstract computation across distributed, and often heterogeneous, hardware. 37 In his proposal for the BSP model, Valiant described it as a “unifying bridging model for parallel computation,” existing as something between hardware and software, both connecting and insulating them, that allowed high-level programs’ processing tasks to occur simultaneously across distributed machines. 38 The BSP Model consists of three primary attributes. First, a distributed set of components that engage in processing and/or memory functions. Second, a router whose sole function is to communicate messages between component pairs, and thus implements “storage access between distinct components.” 39 And third, a synchronization mechanism that determines progression between ‘supersteps’. Valiant writes, “In each superstep, each component is allocated a task consisting of some combination of local computation steps, message transmissions and (implicitly) message arrivals from other components.” 40 For Valiant, this synchronization mechanism is a user input periodicity of L time units. After each period of L elapses, the BSP computer checks if the superstep is completed, and either proceeds to the next superstep or initiates a new period in which to complete the superstep in process. Interestingly, Valiant also notes that an alternative synchronization mechanism could continuously check whether all the components had completed the superstep, and initiate the proceeding superstep when they had, which is exactly how Pregel was designed. 41
Pregel refers to Valiant’s ‘components’ as ‘vertices,’ and sometimes refers to ‘supersteps’ as ‘iterations’. As Pregel is a graph database, these vertices are connected by edges, along which messages can be routed. Google Researchers write, “Programs [in Pregel] are expressed as a sequence of iterations, in each of which a vertex can receive messages sent in the previous iteration, send messages to other vertices [which will be received in the proceeding iteration], and modify its own state and that of its outgoing edges or mutate graph topology.” 42 At each superstep in a Pregel algorithm, each vertex can vote to halt, and the algorithm proceeds to the next superstep when every vertex has done so. Halted vertices will not be reactivated by the algorithm unless they receive an incoming message from the previous superstep. If there are no messages, and thus all vertices are halted without possibility of reactivation, the algorithm is completed. Figure 3, below, is an instructive example:
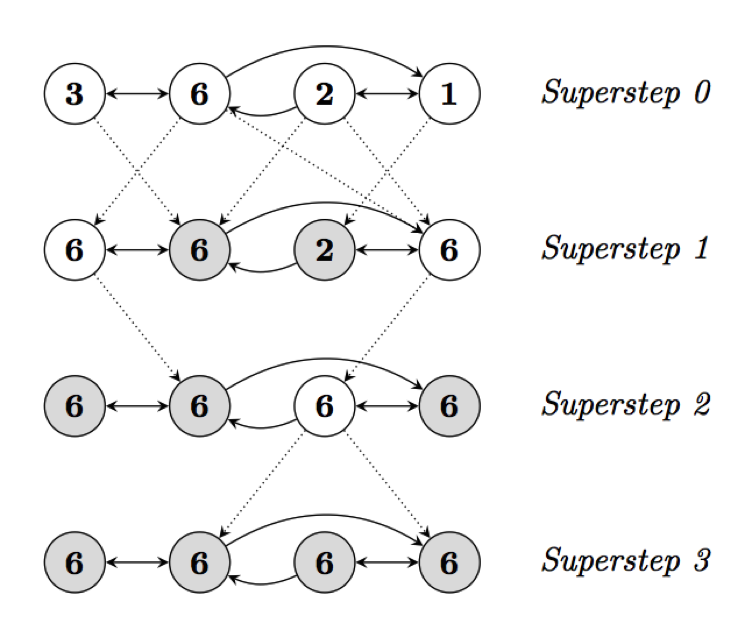
Figure 3: Google’s Visualization of a Maximum Value Algorithm 43
Here each circle is a vertex containing a numerical value, and shaded vertices have voted to halt. Solid vectors are edges, and dotted vectors are messages sent along edges to be received at the next superstep. In this particular algorithm, at Superstep 0 each vertex sends its value along its outgoing edges. At each subsequent Superstep, each vertex receives any incoming messages. If the value each vertex receives is lower than its own, it halts. If it is higher than its own, it changes to that value, sends its new value as a message along all of its outgoing edges, and then halts. Halted vertices are reactivated upon receiving a message, but again, only send out messages upon receiving a value higher than their own. At Superstep 3 all vertices have halted without sending any new messages, and thus the algorithm is completed.
Pregel is a giant graph of these vertices, edges, and messages being sent between supersteps that can accept user input commands from a C++ implemented API. By 2010, it was already capable of graphing relationships between more than a billion vertices. 44 This allows Google to, for instance, present you with a famous actor’s most important relationships, such as biographical information (e.g., place and date of birth, education, parents, spouse, children, etc.) and films the actor is associated with. These filmic associations could be determined either by direct relationships (a single edge, connoting things like ‘Starred In,’ ‘Co-Starred In,’ ‘Appeared In,’ etc.) or, less likely, by indirect relationships (paths between actors and films that consist of a specified number of edges 45). Further, it can perform operations on this subsection of the graph, which in this simple example might be things like calculating the number of films the actor has starred in. The most fundamental aspect of this example though is that Pregel is able to determine that a particular thing is an actor, and thus that these types of relationships constitute the most important information to present.
What is most important in the case of Pregel is that, while the natural language terminology for the entities and relations remains stored in the database as literals, their surrounding context is discarded. The operations on the graph database occur outside of reference even to these literals, let alone their original context. As such, any new knowledge that is produced by manipulating the graph database is always-already limited by the particular constraints of its data structure (here vertex-edge type-vertex triples), and its schema and ontology (e.g., its taxonomy of genera). The critique of any such graph database thus always requires a critique of its inputs in addition to its outputs. However, before moving on to an examination of the preparation of data for Pregel input below, it ought to be pointed out that the limitations in terms of Pregel’s outputs specifically is near impossible to rigorously articulate, even speculatively. This is because, while one can read about the functions and operations that can be performed atop the Pregel database via extensions, there is no open sourced alternative NoSQL graph database that operates at Pregel’s scale, or that offers similar C++ implemented extensions instead of using SPARQL command prompts.
Information Extraction on the Web
In order to accurately determine what a particular thing is, what aspects of it are important, and thus which relationships to present, Pregel requires both a huge data set and a sophisticated query mechanism. While graph databases can operate accurately at small scales with very slim and well-defined schemas and ontologies, Pregel is designed for gigantic graphs of heterogeneous relations that constantly expand. To function accurately at that scale, Google needed to build a gigantic Pregel data set of vertices and edges. To do so, they developed a number of other applications that would allow them to crawl the Web and extract structured information that could be translated into vertices and edges. This required a series of experiments with machine learning and verification procedures to produce accurate, structured data ready for importation. And further, because the data set was meant to be heterogeneous, Google needed to extend this machine learning to the production of an iterative schema and ontology.
Since its inception, Google has been invested in developing technologies for machine learned ‘Information Extraction’ (IE) techniques for application to unstructured Web documents. Even before the publication of the PageRank algorithm, Google cofounder Sergey Brin was working on the unsupervised extraction of binary relations. 46 Google understands the Web as a gigantic collection of textual documents, and argues “the human knowledge encoded within the documents can be seen as a hidden, implicit Web of classes of objects (e.g., named entities), interconnected by relations applying to those objects (e.g., facts).” 47 For more than a decade, Google has been intensively researching methods for IE, first by ‘Named Entity Recognition’ (NER) and its capacity for classifying objects, and second by ‘Relation Extraction’ (RE) and its capacity for discovering and proliferating connections between those objects. Their immediate concern is improving Web search, but, as they argue, this process of IE “also fits into the far-reaching goal of automatically constructing knowledge bases from unstructured text.” 48 As we’ve seen, for Google the Web is a gigantic repository of expository statements about the world that users wish to interrogate, and it is their goal to have machines build their own n-arized machinic representation of that world in order to make fuzzy logic based arguments about it upon human interrogation.
However, there is a price that any information extraction algorithm must pay in order to produce data sets given to complex natural language queries. The goal is to produce a data set that can respond to queries analogically, such that users don’t need to already know the specific answer that they are seeking in order to input their query. Instead, the database needs to simulate serendipitous discovery, which means comparing possible answers and determining which ones are similar enough to the structure of the question and its implied answer. This detection of similarity is achieved by n-arization, the machinic construction of vast schemas and ontologies for the generalization of entities and relations into conceptual taxonomies, and the establishment of probabilistic analogies between different genera in that taxonomy. While this process affords great flexibility to query and renders statistical analogies that otherwise might be unavailable to human knowledge, it also necessitates a flattening of entities and relations in their singularity and absolute specificity that becomes most apparent at the level of generic triples. The individuality of a person’s birth into a particular place and world is flattened into the generic triple of [Person][WasBornIn][Place], despite the absolute singularity of a person’s being born in a particular place and world. A graph database attempts to account for this loss within an n-ary stream of thought by supplementing the triple with yet more triples, by forming paths, regions, and entire graphs. It attempts to flesh out and perfect its representation of a real life by connecting all sorts of other constative claims, like where that person went to school, what texts they may have produced, who their family members and friends might have been, ad inf. Yet, the individuality of a life is not reducible to the constellation of facts, or as rhetorical scholars might term it, the situation, from which it emerged.
Almost immediately after its proposal, 49 the use of machine learning for IE was applied to constructing machine-readable semantic lexicons, 50 NER, 51 binary relation extraction, 52 and mobilizing that data for Question Answering based query. 53 The biggest limitations of these experiments were their reliance on ‘clean text collections’ – and especially news corpora – rather than ‘noisy Web documents,’ 54 their expense, and their closed, and thus limited, schemas and ontologies to which data were made to fit or disregarded. 55 For Google, the massive amounts of errors and non-standard language usages on the Web capture divergent aspects of human behavior that are not only important for capturing the diverse knowledge contained in the Web, but also for more practical purposes, such as providing accurate search results to queries containing errors and non-standard language usage. Google’s solution: big data. Google Researchers write, “[A]ll the experimental evidence from the last decade suggests that throwing away rare events is almost always a bad idea, because much Web data consists of individually rare but collectively frequent events.” 56 Once your corpora enters a scale of billions of examples, you obtain an approximate set of all human distinctions between entities without need to start from generative rules. 57 For Google, the limitations of n-arization always disappear at greater scales, and thus the solution for any quirk in the graph is always more data.
Here Google Research is following a trend in IE called ‘Statistical Relational Learning’ that leverages large corpora for statistical machine learning of patterns and construction of models, the outcome of which is the ability to probabilistically represent relations between entities – even so-called ‘deep’ relations – based on first-order predicate logic. 58 In “The Unreasonable Effectiveness of Data,” Google Researchers argue that the “first lesson of Web-scale learning is to use available large-scale data rather than hoping for annotated data that isn’t available,” and close with a call to action: “So, follow the data… [G]o gather some data, and see what it can do.” 59 This is precisely the path that Google has taken. Google employs machine learning and Web crawlers for performing NER and RE on unstructured Web documents (TextRunner), formatted tables (WebTables), 60 query logs, 61 and the deep Web, 62 continually modified, verified, and shored up by Click Through Rate (CTR) tracking on all of their search traffic. While each of these crawlers is programmed differently, they basically perform the same function on different sets of data that is either unstructured or not structured in accordance with Pregel’s schema and ontology. This function is the extraction of triples suitable for input as Pregel vertices and edges. As such, I examine TextRunner as a representative example.
However, before moving on it is worth pointing out that while statistical relational learning is certainly a promising form of machine learning and epistemic production at web-scale, there is again a necessary loss implied by n-arization that offsets this promise. No matter how complex the machinic structure becomes, if it is laid atop the foundation of statistical relational learning through n-ary tuples, this loss is not ever fully recoupable. The loss I am referring to is again the absolute specificity of a singular entity or a singular relation between entities. Statistical relational learning is predicated on the production of taxonomies of genera for entities and relations. While machine learning allows for the introduction of new genera to the schema and ontology, this introduction only occurs once the machine has reached a critical mass of mined entities and relations that match the new genera. These limits vary by machine, but by definition, taxonomical generalization never maintains a one-to-one correspondence between singular entities/relations and their genera. Despite Google’s drive to surpass the limits of n-arization by ever-increasing amounts of data, like the maps of Jorge Luis Borges or Lewis Carroll, the endpoint of that (impossible) trajectory is a graph that is simply the world-in-itself.
At this point for the graph, the life of a person is not even a constellation of facts, but instead is a (probabilistic) constellation of genera, itself relative (probabilistically) to the type of entity that person is identified as (e.g., the life of an actor will be understood as being constituted by a different constellation of genera than that of a political activist). Thus, the machine is making an argument not only about what sorts of facts are knowable and important, but also about what constellation of genera constitutes the identity of a particular entity. In short, the machine is determining which of types of relations are important in regards to certain types of entities, and in so doing, setting up an entire n-ary representational logic for analogical thought. It is as if the machine here is engaging in the millennia old task of producing, updating, and maintaining Aristotelian distinctions between things by way of species and genera automatically, at a frenetic pace, and with all empirical things, be they material or immaterial, in its purview. Through this process of machinic nomination, the machine itself draws the line for us between the effable and the ineffable, between the known, the unknown, and the unknowable.
TextRunner and Unstructured Web Documents
Despite the frustrating lack of access to accurate materials on the actual graph operations being processed behind the Knowledge Graph, a clearer picture of the functioning of n-arization can be had by examining the inputs to the graph. By way of a detour through the history of Google’s research into TextRunner, we can see the foundation of the n-arization of knowledge, the formation of the basic building blocks of the graph – triples – that necessarily delimit the entire field of the knowledge a priori for the blackboxed, though presumedly very advanced, graph functions and operations being processed in Pregel. As we’ll see, the experiments begin with an assumption that knowledge is distributed on the Web in the form of metadata and typed links that can be formalized as triples. Rapid success was quickly achieved by n-arizing language itself to facilitate the extraction of vertices and edges from Web documents containing natural language. But the call for speed and accuracy, and thus for smaller storage spaces and faster parsing algorithms, quickly lead to a shedding of all contextualization and specificity, even of the individual facts themselves.
In 2006 Google Researchers entered a set of 10 randomized seed facts, n-arized into triples of the type Person-BornIn-Year, into a machine-learning algorithm set to crawl 100 million Web documents 63, and was able to grow them into 1 million facts of the same type. The algorithm was set to learn sentence level basic contextual extraction patterns, which in essence are triples that allow for NER. These pattern triples come in the form of (Prefix, Infix, Postfix), which are each a sequence of a fixed number of terms that surround the subject and object of an expository statement. In English sentences, the prefix almost always comes just before the subject, and the postfix just after the object. 64 Take, for example, the sentence “The famous Civil Rights Activist Stokely Carmichael was born in 1941, in Port of Spain, Trinidad and Tobago.” This sentence produces the prefix {…Civil Rights Activist}, the infix {…was born in}, and the postfix {in Port of Spain…}, which isolate the subject {Stokely Carmichael} and the object {1941}.
In the first part of the process, the documents were crawled in parallel, sentence by sentence, for sentences that contained both entities from any of the 10 seed facts. The algorithm then took the (Prefix, Infix, Postfix) triple from any of the sentences that it had located, which constituted the specific patterns in which the seed facts had occurred, and aggregated prefixes, infixes, and postfixes into broader classes based on their distributional similarity. 65 Once distributionally similar prefixes, infixes, and postfixes had been grouped into classes, the algorithm yielded a smaller set of general pattern triples – i.e., (PrefixClass, InfixClass, PostfixClass). There were obviously fewer general patterns than basic patterns, but their coverage of sentences containing the targeted relation between entities was significantly increased. In the second part of this process, these general pattern triples were matched to sentences to extract new candidate facts – i.e., people and their birth years not included in the seed facts. In the third part of this process, candidate facts were validated based on statistical scores produced by their word-to-word similarity to candidate facts, the similarity of the infixes of the sentences from which they were extracted, and the probability that both entities in a candidate fact were complete (e.g., Stokely or S. Carmichael vs. Stokely Carmichael), all three of which were calculated via distributional similarity. Those candidate entities that met a certain score threshold were then retained. This entire three-part process is referred to as an ‘acquisition iteration’. In this experiment, Google was able to produce its 1 million facts over a series of only two acquisition iterations, and found their results to have an 88.38% precision rate. At the time of the study, this extracted fact set was several orders of magnitude larger than any other extracted fact set in history. 66
As you can see, this revolutionary IE process rested on Google’s capacity to calculate distributional similarities at almost every step. At the time of the study, Google had already spent three years indexing the distributional similarity of words occurring in a corpus of approximately 50 million news articles. 67 A database of distributional similarities of words is an n-arization of language, and serves as the foundation of the statistical language models leveraged for large scale IE processes. 68 Such a database is produced through what is called ‘n-gram analysis’ performed on large data sets. An n-gram is a sequence of n successive grams, where each gram is one instance of the linguistic unit being analyzed and n is the number of units included in the sequence. Single gram sequences are referred to as ‘unigrams,’ followed by ‘bigrams,’ ‘trigrams,’ ‘four-grams,’ ‘five-grams,’ and so on. In this case, n-gram analysis is a calculation of the probability that particular words will occur in a particular order – here you might think of n-grams as phrases. In the same year that Google Researchers published the experiment outlined above, Google made public a database of a trillion words and n-gram analyses of the frequencies of all sequences of these trillion words up to five words in length. 69 What this meant was that given any sequence’s first word, Google could calculate the most likely second, third, fourth, and fifth words of that sequence, with decreasing accuracy. And further, the more words of a given five-gram sequence that were given, the more accurately Google could calculate the following word. An expedient example of an application of n-gram analyses is the increasing accuracy of Google’s top 10 autocomplete suggestions for your search query as you type each word of your query.
This example is expedient because it overlooks some of the more impressive pieces of information contained in n-gram frequencies. For any sequence of words greater than five, the frequencies of potential unigrams, bigrams, trigrams, four-grams, and five-grams can be used to calculate the probable shifts between n-grams in the sequence. For example, given five words, if there is a high frequency of co-occurrence between the first three words and the last two words, but the fourth word rather infrequently follows the third word, it will be more likely that those five words are a trigram followed by a bigram, rather than a five-gram. In essence, this allows parts of speech to be separated. But further, statistical analysis of how often and in what order n-grams occur together in a sentence produces much more robust applications. In essence, this second level of analysis allows the determination of ‘semantic similarity’ between n-grams – be they single words or phrases – which includes synonymy, meronymy, hyponymy, antonymy, as well as words or phrases that are simply related to one another. 70 This determination of semantic similarity allows n-grams to be classified into types, which can then be rather easily affiliated with things like parts of speech to extract (Prefix, Infix, Postfix), and thus (Subject, Predicate, Object) triples.
Once this level of statistical data has been achieved, distributional analysis becomes so powerful that named entities can be continually identified without need of prefixes and postfixes. Here distributional similarity can be measured accurately enough to identify an entity by its internal distribution and its border with its infix alone. Eliminating prefix and postfix patterns improves recall, and can be shored up by a variety of verification mechanisms. 71 These mechanisms include things like the validation procedure described above, which can compare candidates to one another, to a seed, and to a type, correlating extracted candidates to datasets extracted from other sources on the Web, and tracking search users’ interactions with structured data presented as answers to their queries. The end result of this system is TextRunner, which crawls the Web, performs IE in batch mode to generate an iterative schema and ontology and a detailed index for future queries. 72 Notably, entities and relations that do not meet established validation standards are discarded, and thus do not contribute to the iterative development of the schema and ontology, nor do they appear in the index.
With TextRunner, we can again see that the constraints of storage space and parsing speed lead to the discarding of the context in which the extracted information originally occurred. While the same critiques outlined above certainly continue to apply here, we find a new problem here in statistical relational learning, which only admits new entities and relation types when they occur in a frequent and distributed enough fashion to meet its given learning threshold. This problem is twofold: (1) the extracted information will be the norms of the most frequent and distributed content producers on the Web, which leads to all sorts of implicit imbalances in terms of socio-economic class, nationality, ethnicity, race, gender, etc., and (2) the extracted information will be that which is stable enough to be recognized as ‘truth,’ and thus more singular instances of poetic language use will either be passed over, discarded, and excluded from machine learning and machinic epistemologies, or they will be flattened into their most analogically similar genera and forfeit their poetic force. What cannot be n-arized cannot be thought: it is nonsense. The protocols for machine learning and extraction always function by way of selection, and thus by both inclusion and exclusion, remembering and forgetting, storing and discarding, as well as arrangement, a process which inflects all of the information it extracts. Extraction is always a reduction and an abstraction that, while functional, demands continuous and constant critical awareness of its stakes and implications.
The N-Arization of Knowledge
A number of rhetorical scholars have argued that the self is not a transhistorical phenomenon with some sort of universal or transcendental substance. Instead, the self is concretely historical, situated, and constituted or brought into being by rhetorical invention. 73 The self and its knowledge of the world are both inflected by the particular pattern through which they were constituted, stabilized, and maintained. For Ronald Greene, “The critic locates his/her ethical-political judgment in how a constitutive outside (or other) becomes the source of possibility for the stabilization of a subject.” 74 Here the post-structural critical project is an illumination of these patterns, a Nietzschean reminder that truth is a poetic and rhetorical construct that has forgotten itself, which might set the self free to determine its own constitutions, stabilizations, maintenance, and iterative modifications. But even more so, it is this freeing up of collective selves, to make these determinations in common. It is a demonstration to any group of selves who are in a world together that they might constitute, stabilize, maintain, and iteratively update their common world. What is at stake here is the very futurity, and through it, the agency in the present moment, of any given me, we, or world.
As we’ve seen in first section of this article, rhetorical criticism helps highlight the n-arization of knowledge at work in Google’s Knowledge Graph. In the second section we saw that the machinic n-arization of thought in the Knowledge Graph took the form of Google’s only holy trinity, the triple. Google understands the world as a vast sea of expository utterances to be mined for knowledge. It understands knowledge to be a triadic movement between vertices, and thus thought is this forging of paths between discrete points. As we saw in the third section, these paths can produce sequences, outline regions, navigate between abstract generality and absolute specificity, even human-knowable literals. They can be traversed by messages or architecturally maintained as edges. What this means in terms of an inter-machinic metaphysics is outside the purview of this paper, and perhaps impossible to know barring public access to Google’s proprietary algorithms and server farms. In the fourth section, we saw that what we do have some access to is the inputs and outputs to Pregel, the graph database (likely) powering the Knowledge Graph. These outputs are the automatically populated content boxes that sometimes appear alongside users’ search results. The inputs are the result of IE techniques that Google has been honing for nearly two decades, all in accord with the company credo of simple models and billions of data. Google maintains this stance despite the limitations of TextRunner, as we saw in the fifth section, which n-arized a corpus of trillions of words in order to facilitate the abstraction of things and relations between them into vertices and generic edges between them for inputs to the Knowledge Graph. What this means for humans, then, is that all human-knowable information derived from the graph is nothing but strings of n-ary tuples abstracted from their context and specificity, nothing but paths, paths, paths.
Provided that it is understood as a way of thinking and understanding open to collective and continued influence, rather than solidified into a regime of truth, a graph database like the Knowledge Graph is an extremely impressive experiment in epistemic rhetoric, with many significant contributions to its world. These contributions range from the concrete demonstration that machines can perform rhetorical acts to the ease with which anyone can draw on a large collective’s triadic knowledge formations quickly, mobilely, and accurately. It certainly does achieve what it purports to, at least to the best of its current ability, which is the facilitation of (limited) discovery. It allows users to make simple graph queries in natural language – which is no small feat if given the complexity of coding SPARQL queries – that can mutate graph topologies, and present them with a perspective of the graph, a carousel for interfacing with the probabilistically related items from that perspective. The user can move from vertex to vertex, mutating graph topology on the fly with a single click, discovering entities that are sequentially related, but may be collectively disparate. In so doing, users can start from any vertex of the graph and create paths of relation that highlight sequences, outline regions, or move vertically between abstraction and specificity.
There are numerous potential criticisms, many of which are of utmost importance, but at the same time, not criticisms per se of the immanent logic of the machinic rhetoric itself. I see two primary dangers that are internal to graphical knowledge production itself. The first, and perhaps more obvious, is the danger of a rhetorical production of knowledge that takes itself to be a production of objective truth. There is a danger in that shift from producing one way of knowing to producing the one way of knowing. Google publicizes the graph as an exercise in discovery, or what is often termed ‘serendipitous search.’ It is meant to be a journey into the unknown. But that journey is n-arized into a staggered, sequential, triadic path, moving in fits and starts, and at each resting vertex along the path, the next steps open for the journey are those probabilistically determined to be most suitable. While it would be useful to empirically examine the number of vertices an average Knowledge Graph user moves through and the graphical and/or relational distance and displacement they achieve, it should be expected that the ‘unknown’ that user discovers would be rather ordinary and easily appropriated, not so far off his or her beaten path, so to speak. If n-arized knowledge is one knowledge among many, then this constitutes a relatively small problem, as in that case it would be a rhetorical multiplication of ways to know and knowledge itself. However, if this becomes the mode of knowing and discovering, rhetorical criticism demonstrates that it is inherent to its protocol – its process of selecting, marking, arranging, storing, discarding, etc. – that this knowledge will always be perspectival, reductive in its generalizations, a failed representation that loses the specificity of singularity in its movement towards analogy. In short, it will always be a false universalism. And further, in this instance, it is likely that our n-arized journeys will be confined to relatively small regions with only minor discoveries of rather easily appropriated unknowns.
It is likely the case that the Knowledge Graph and its successors become powerful enough to make a bid at becoming the one way of knowing. Google continually dominates global Web traffic, navigating knowledge on behalf of a large portion of the world, and reaping huge financial benefits as well. With Google’s resources, there is little doubt that the Knowledge Graph project will continue to be developed and more deeply embedded into everyday life, to the point that, at least for some, it will be their episteme. Yet, Google Researchers are well aware of the Knowledge Graph’s current limitations, which are, precisely, the absolute specificity of a singular thing. As we’ve seen, a number of Google Researchers passionately believe that simple models for statistical analysis at Web scale (or larger) are the way to examine the unique, the aberrant, and the unclassified, because at such scales there is the largest possibility of subduing them to a representational logic by way of n-arized analogy. But this is an indefinite – if not infinite – task of adjusting strings to better match things, and a reinvigoration of the millennia old impulse to pursue perfect simulacra. This task requires one to truly believe in the potential equivalence of strings and things, of the human and the machine. And it is precisely the belief in this equivalence that forecloses the inventive force of graphical knowledge being one new way of knowing among many others, a way of exploring the differentiations across human and machinic worldings.
The second and most frightening danger of n-arized knowledge to me, though, is at work in the blank node. In general, the graph’s response to what is unknowable to it, given its schema, ontology, and extraction procedures, is to simply not experience it, to discard it between steps. In these instances the graph is surely selectively exclusive and inclusive, discriminating against inventive practices that do not (yet) operate at a statistically probable scale to meet the threshold for machine learning and extraction. However, in the case of the blank node, the machine has found some thing that it cannot know, and yet that remains essential to its ability to further its purpose of forging paths of triadic connections between entities. Here its knowledge-production practices are confronted by something that is unidentifiable, but no longer outside its experience. It experiences the intense negativity of an otherness, of a void, that it can infer, almost sense, but does not know. And its response to this presence of non-presence – this negativity of the unknown other – is to tether it, to move through it by circumscribing it and allotting it a blank or null identifier.
References
Agichtein, E., and Gravano, L. (2000). Snowball: Extracting Relations From Large Plaintext Collections. In Proceedings of the 5th ACM Conference on Digital Libraries (DL-00): 85–94.
Berners-Lee, T. (1994). W3 Future Directions. Plenary talk. W3. Retrieved from http://www.w3.org/Talks/WWW94Tim/
Berners-Lee, T., Hendler, J., and Lassila, O. (2001). The Semantic Web. Scientific American, 284(5), 28–37.
Biesecker, B. (1989). Rethinking the Rhetorical Situation From Within the Thematic of Différance. Philosophy and Rhetoric, 22, 110-130.
Bizzell, P., Herzberg, B., & Reynolds, N. (1991). A Brief History of Rhetoric and Composition. The Bedford Bibliography for Teachers of Writing, 1-7.
Bollegala, D., Matsuo, Y., & Ishizuka, M. (2007). Measuring Semantic Similarity Between Words Using Web Search Engines. WWW 7: 757-766.
Brin, S. (1998). Extracting Patterns and Relations from the World Wide Web. In Proceedings of the 6th International Conference on Extending Database Technology (EDBT-98), Workshop on the Web and Databases: 172–183.
Brooke, C.G. (2009). Lingua Fracta: Toward a Rhetoric of New Media. Creskill, NJ: Hampton Press.
Cafarella, M.J., Halevy, A., Wang, D.Z., Wu, E. and Zhang, Y. (2008). Webtables: Exploring the Power of Tables on the Web. Proceedings of the VLDB Endowment 1(1): 538-549.
Cafarella, M. J., Madhavan, J., & Halevy, A. (2009). Web-Scale Extraction of Structured Data. ACM SIGMOD Record, 37(4), 55-61.
Charland, M. (1987). Constitutive Rhetoric: The Case of Peuple Quebecois. Quarterly Journal of Speech, 73, 133-150.
Collins, M., and Singer, Y. (1999). Unsupervised Models for Named Entity Classification. In Proceedings of the 1999 Conference on Empirical Methods in Natural Language Processing and Very Large Corpora (EMNLP/VLC-99): 189–196.
Cucerzan, S., and Agichtein, E. (2005). Factoid Question Answering Over Unstructured and Structured Content on the Web. In Proceedings of the 14th Text REtrieval Conference (TREC-05).
Czajkowski, G. (2009, June 15). Large-Scale Graph Computing at Google. Google Research Blog. Retrieved from http://googleresearch.blogspot.com/2009/06/large-scale-graph-computing-at-google.html
Fleischman, M., Hovy, E., and Echihabi, A. (2003). Offline Strategies for Online Question Answering: Answering Questions Before They are Asked. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics (ACL-03): 1–7.
Galloway, A.R. (2012). The Interface Effect. Malden, MA: Polity Press.
Getoor, L. and Taskar, B. (2007). Introduction to Statistical Relational Learning. Cambridge, MA: The MIT Press.
Greene, R. (1998). The Aesthetic Turn and the Rhetorical Perspective on Argumentation. Argumentation & Advocacy, 35(1), 19.
Gruber, T. R. (1993). A Translation Approach to Portable Ontologies. Knowledge Acquisition, 5(2): 199-220.
Hasegawa, T., Sekine, S., and Grishman, R. (2004). Discovering Relations Among Named Entities from Large Corpora. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04): 415–422.
Halevy, A. Norvig, P. and Pereira, F. (2009). The Unreasonable Effectiveness of Data. Intelligent Systems, IEEE 24(2): 8-12.
Halpin, H. (2013). Social Semantics: The Search for Meaning on the Web. New York, NY: Springer.
Hogue, A. (2011). The Structured Search Engine. Youtube. Retrieved from http://youtu.be/5lCSDOuqv1A
Introducing the Knowledge Graph: Things, Not Strings. (2012, May 16). Google: Official Blog. Retrieved from http://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html
Introna, L.D. and Nissenbaum, H. (2000). Shaping the Web: Why the Politics of Search Matters. The Information Society 16: 169-185.
Lanham, R.A. (2006) The Economics of Attention: Style and Substance in the Age of Information. Chicago, IL: University of Chicago Press.
Lita, L., and Carbonell, J. (2004). Instance-Based Question Answering: A Data Driven Approach. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP- 04): 396–403.
Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, I., Leiser, N., and Czajkowski, G. (2010, June). Pregel: a system for large-scale graph processing. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (pp. 135-146). ACM.
Manovich, L. (2001). The Language of New Media. Cambridge, MA: The MIT Press.
Miller, C. R., and Shepherd, D. (2004). Blogging as Social Action: A Genre Analysis of the Weblog. Into the Blogosphere: Rhetoric, Community, and Culture of Weblogs, 18.
Paşca, M. (2007, May). Organizing and Searching the World Wide Web of Facts – Step Two: Harnessing the Wisdom of the Crowds. In Proceedings of the 16th international conference on World Wide Web (pp. 101-110). ACM.
Pasca, M., Lin, D., Bigham, J., Lifchits, A., and Jain, A. (2006, July). Organizing and Searching the World Wide Web of Facts – Step One: The One-Million Fact Extraction Challenge. In AAAI (6): 1400-1405.
Paul, C. (2007). The Database as System and Cultural Form: Antinomies of Cultural Narratives. In V. Vesna (Ed.). Database Aesthetics: Art in the Age of Information Overflow. Minneapolis, MN, pp. 95-109.
Schoenmackers, S., Etzioni, O., & Weld, D. S. (2008, October). Scaling Textual Inference to the Web. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (pp. 79-88). Association for Computational Linguistics.
Scott, R. L. (1967). On Viewing Rhetoric as Epistemic. Central States Speech Journal, 18, 9-17.
Scott, Robert (chairman). 1971. “Report of the Committee on the Nature of Rhetorical Invention” in The Prospect of Rhetoric. Prentice Hall, 228-236.
Sicilia, M.-A. (2014). Metadata Research: Making Digital Resources Useful Again? In M.-A. Sicilia (Ed.). Handbook of Metadata, Semantics and Ontologies (pp. 1-8). Hackensack, NJ: World Scientific.
Taskar, B., Klein, D., Collins, M., Koller, D., and Manning, C.D. (2004, July). Max-Margin Parsing. In EMNLP 1 (1.1): 3.
Thelen, M., and Riloff, E. (2002). A Bootstrapping Method for Learning Semantic Lexicons Using Extraction Pattern Contexts. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP-02), 214–221.
Valiant, L. G. (1990). A bridging model for parallel computation.Communications of the ACM, 33(8), 103-111.
Vesna, V. (2007b). Introduction. In V. Vesna (Ed.). Database Aesthetics: Art in the Age of Information Overflow. Minneapolis, MN, pp. ix-xx.
—. (2007a). Seeing the World in a Grain of Sand: The Database Aesthetics of Everything. In V. Vesna (Ed.). Database Aesthetics: Art in the Age of Information Overflow. Minneapolis, MN, pp. 3-38.
W3C Working Group. (2014). RDF 1.1 Primer. Retrieved from http://www.w3.org/TR/rdf11-primer/
Notes
- Introna, L.D. and Nissenbaum, H. (2000). Shaping the Web: Why the Politics of Search Matters. The Information Society 16: 169-185. p. 171 ↩
- Introducing the Knowledge Graph: Things, Not Strings. (2012, May 16). Google: Official Blog. Retrieved from http://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html ↩
- Ibid. ↩
- Ibid. ↩
- Halevy, A. Norvig, P. and Pereira, F. (2009). The Unreasonable Effectiveness of Data. Intelligent Systems, IEEE 24(2): 8-12. p. 9 ↩
- Bizzell, P., Herzberg, B., & Reynolds, N. (1991). A Brief History of Rhetoric and Composition. The Bedford Bibliography for Teachers of Writing: 1-7. p. 1 ↩
- Lanham, R.A. (2006) The Economics of Attention: Style and Substance in the Age of Information. Chicago, IL: University of Chicago Press. p. xiii ↩
- Manovich, L. (2001). The Language of New Media. Cambridge, MA: The MIT Press. p. 77 ↩
- Ibid., p. 78 ↩
- For examples, see Bogost, I. (2010). Persuasive Games: The Expressive Power of Videogames. Cambridge, MA: The MIT Press (esp. pp. 1-65), and Losh, E.M. (2009). Virtualpolitik: An Electronic History of Government Media-Making in a Time of War, Scandal, Disaster, Miscommunication, and Mistakes. Cambridge, MA: The MIT Press (esp. pp. 47-95). ↩
- Brooke, C.G. (2009). Lingua Fracta: Toward a Rhetoric of New Media. Creskill, NJ: Hampton Press. p. 92 ↩
- See Manovich, 2001, p. 217; Vesna, V. (2007b). Introduction. In V. Vesna (Ed.). Database Aesthetics: Art in the Age of Information Overflow. Minneapolis, MN, pp. ix-xx. p. xiii ↩
- Manovich, 2001, p. 214 ↩
- Ibid., p. 228; Ibid., p. 220 ↩
- Ibid., p. 225; See also Galloway, A.R. (2012). The Interface Effect. Malden, MA: Polity Press. pp. 71-72; Vesna, V. (2007a). Seeing the World in a Grain of Sand: The Database Aesthetics of Everything. In V. Vesna (Ed.). Database Aesthetics: Art in the Age of Information Overflow (pp. 3-38). Minneapolis, MN: University of Minnesota Press. p. 30 ↩
- Ibid., p. 231 ↩
- It is important to distinguish between data, which maintains structure but in a format not suitable in itself to human knowing, requires translation via interfaces or APIs to become human-knowable information. See Paul, C. (2007). The Database as System and Cultural Form: Antinomies of Cultural Narratives. In V. Vesna (Ed.). Database Aesthetics: Art in the Age of Information Overflow. Minneapolis, MN, pp. 95-109. p. 96 ↩
- Vesna, 2007b, p. xiii ↩
- Paşca, M. (2007, May). Organizing and Searching the World Wide Web of Facts – Step Two: Harnessing the Wisdom of the Crowds. In Proceedings of the 16th international conference on World Wide Web (pp. 101-110). ACM. p. 109 ↩
- Harpine, W. (2004) What Do You Mean, Rhetoric Is Epistemic? Philosophy and Rhetoric 37: 335-352, p. 347 ↩
- Berners-Lee, T. (1994). W3 Future Directions. Plenary talk. W3. Retrieved from http://www.w3.org/Talks/WWW94Tim/http://www.w3.org/Talks/WWW94Tim/ ↩
- Berners-Lee, T., Hendler, J., and Lassila, O. (2001). The Semantic Web. Scientific American 284 (5): 28–37. ↩
- Guns, R. (2013). Tracing the Origins of the Semantic Web. Journal of the American Society for Information Science and Technology 64(10): 2173-2181. p. 2174-2175 ↩
- Ibid., p. 2178. N.b., for simplicity, the term vertex will be my default term for connoting node, entity, etc., and the term edge will be my default term for connoting link, attribute, relation, etc. I will alternately employ subject, predicate, and object when I need to preserve the directionality of an edge. ↩
- Halpin, H. (2013). Social Semantics: The Search for Meaning on the Web. New York, NY: Springer. pp. 59-60 ↩
- W3C Working Group. (2014). RDF 1.1 Primer. Retrieved from http://www.w3.org/TR/rdf11-primer/ (As we’ll see in more detail below, predicates are systematically rendered into types based on a graph’s schema and ontology – as giving every link its own unique type and identifier would produce as much useful information as giving them none – and thus the identifier for an edge operates as a foreign key, itself linked to the edge type definition in the graph’s schema and ontology.) ↩
- Ibid. ↩
- W3C Working Group, 2014. Copyright © 2003-2014 W3C® (MIT, ERCIM, Keio, Beihang), All Rights Reserved. W3C liability, trademark and document use rules apply. ↩
- Greenberg, J. (2003). Metadata and the World Wide Web. Encyclopedia of Library and Information Science 3: 1876-1888. p. 1884 ↩
- Things like use, search, discovery, surfacing relations between disconnected vertices – as with blank nodes – or implicit relations, authentication, and administration are some of the more common functions of objects that metadata support. ↩
- Sicilia, M.-A. (2014). Metadata Research: Making Digital Resources Useful Again? In M.-A. Sicilia (Ed.). Handbook of Metadata, Semantics and Ontologies (pp. 1-8). Hackensack, NJ: World Scientific. p. 4 ↩
- Sicilia, 2014, p. 4 ↩
- Ontologies draw on and appropriate from the world outside themselves to achieve this. Narrower ontologies can be fully written by humans coders. More robust and complex ontologies can be produced iteratively from an initial set of human composed seeds, a machine learning algorithm, and verification procedures along the way. ↩
- Gruber, T. R. (1993). A Translation Approach to Portable Ontologies. Knowledge Acquisition 5(2): 199-220. p. 199 ↩
- Ibid., p. 199-204 ↩
- N.b., It is still unclear whether Pregel’s database maintains all of its own records internally and perpetually, or whether it uses foreign keys, or something akin to them, to call up its vertex and edge values from one of its pseudo-RDBMS’s, like BigTable or Spanner. ↩
- Czajkowski, G. (2009, June 15). Large-Scale Graph Computing at Google. Google Research Blog. Retrieved from http://googleresearch.blogspot.com/2009/06/large-scale-graph-computing-at-google.html ↩
- Valiant, L. G. (1990). A Bridging Model for Parallel Computation. Communications of the ACM, 33(8): 103-111. p. 104 ↩
- Ibid., p. 105 ↩
- Ibid. ↩
- Ibid. ↩
- Malewicz, G., Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, I., Leiser, N., and Czajkowski, G. (2010, June). Pregel: A System for Large-Scale Graph Processing. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of data (pp. 135-146). ACM. p. 135. ↩
- Taken from Ibid., p. 136 ↩
- Ibid., p. 143 ↩
- As it turns out, Pregel is great at calculating things like Erdős numbers or degrees of Kevin Bacon. ↩
- Brin, S. (1998). Extracting Patterns and Relations from the World Wide Web. In Proceedings of the 6th International Conference on Extending Database Technology (EDBT-98), Workshop on the Web and Databases: 172–183. ↩
- Paşca, 2007, p. 101 ↩
- Ibid. ↩
- Riloff, E., and Jones, R. (1999). Learning Dictionaries for Information Extraction by Multilevel Bootstrapping. In Proceedings of the 16th National Conference on Artificial Intelligence (AAAI-99): 474–479. ↩
- Thelen, M., and Riloff, E. (2002). A Bootstrapping Method for Learning Semantic Lexicons Using Extraction Pattern Contexts. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP-02): 214–221. ↩
- Collins, M., and Singer, Y. (1999). Unsupervised Models for Named Entity Classification. In Proceedings of the 1999 Confer- ence on Empirical Methods in Natural Language Processing and Very Large Corpora (EMNLP/VLC-99): 189–196. ↩
- Brin, 1998; Agichtein, E., and Gravano, L. (2000). Snowball: Extracting Relations From Large Plaintext Collections. In Proceedings of the 5th ACM Conference on Digital Libraries (DL-00): 85–94. ↩
- Cucerzan, S., and Agichtein, E. (2005). Factoid Question Answering Over Unstructured and Structured Content on the Web. In Proceedings of the 14th Text Retrieval Conference (TREC-05).; Fleischman, M., Hovy, E., and Echihabi, A. (2003). Offline Strategies for Online Question Answering: Answering Questions Before They are Asked. In Proceedings of the 41st Annual Meeting of the Association for Computational Linguistics (ACL-03): 1–7.; Lita, L., and Carbonell, J. (2004). Instance-Based Question Answering: A Data Driven Approach. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP- 04): 396–403. ↩
- For examples, see Agichtein & Gravano, 2000; Hasegawa, T., Sekine, S., and Grishman, R. (2004). Discovering Relations Among Named Entities from Large Corpora. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04): 415–422. ↩
- Pasca, M., Lin, D., Bigham, J., Lifchits, A., and Jain, A. (2006, July). Organizing and Searching the World Wide Web of Facts – Step One: The One-Million Fact Extraction Challenge. In AAAI (6): 1400-1405. p. 1401 ↩
- Halevy, Norvig & Pereira, 2009, p. 9 ↩
- Ibid. ↩
- Ibid. For more on this trend, see Getoor, L. and Taskar, B. (2007). Introduction to Statistical Relational Learning. Cambridge, MA: The MIT Press.; Taskar, B., Klein, D., Collins, M., Koller, D., and Manning, C.D. (2004, July). Max-Margin Parsing. In EMNLP 1 (1.1): 3.; and Schoenmackers, S., Etzioni, O., & Weld, D. S. (2008, October). Scaling Textual Inference to the Web. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (pp. 79-88). Association for Computational Linguistics. ↩
- Ibid., p. 9, 12 ↩
- See Cafarella, M.J., Halevy, A., Wang, D.Z., Wu, E. and Zhang, Y. (2008). Webtables: Exploring the Power of Tables on the Web. Proceedings of the VLDB Endowment 1(1): 538-549.; Cafarella, M. J., Madhavan, J., & Halevy, A. (2009). Web-Scale Extraction of Structured Data. ACM SIGMOD Record, 37(4): 55-61. ↩
- See Paşca, 2007 ↩
- See Cafarella, Madhaven & Halevy, 2009 ↩
- These documents were in English, cleaned of HTML, tokenized, split into sentences, and were part-of-speech tagged using the TnT tagger. Paşca et al., 2006, p. 1402 ↩
- It is important to note that Google’s extraction method is specifically designed for languages that read from left to right and in which subjects precede their objects. As Google Researcher Andrew Hogue notes, Google has trouble with “Yoda speak,” where objects precede subjects. It is unclear at this point if and how Google modifies TextRunner to perform information extraction on languages that differ from this standard. An alternative may be attaching entity names from other languages to their English synrings and identifiers, and thus providing search results based upon data extracted from English language web documents. As the Knowledge Graph was recently implemented for Japanese Google users, it would be useful to extend this line of inquiry to the Japanese language Knowledge Graph. See Hogue, A. (2011). The Structured Search Engine. Youtube. Retrieved from http://youtu.be/5lCSDOuqv1Ahttp://youtu.be/5lCSDOuqv1A ↩
- N.b., This is a somewhat expedient explanation, as the extraction of (Prefix, Infix, Postfix) triples from sentences containing seed facts makes use of a modified trie designed by Google Researchers. ↩
- Paşca et al., 2006 ↩
- Ibid., p. 1401 ↩
- These databases are also essential for speech recognition and algorithms that translate phrases between languages. See Halevy, Norvig & Pereira, 2009. ↩
- Halevy, Norvig & Pereira, 2009, p. 8 ↩
- Bollegala, D., Matsuo, Y., & Ishizuka, M. (2007). Measuring Semantic Similarity Between Words Using Web Search Engines. WWW 7: 757-766. ↩
- Paşca et al., 2006, p. 1401 ↩
- Cafarella, Madhaven & Halevy, 2009, p. 56 ↩
- Biesecker, B. (1989). Rethinking the Rhetorical Situation From Within the Thematic of Différance. Philosophy and Rhetoric, 22, 110-130.; Charland, M. (1987). Constitutive Rhetoric: The Case of Peuple Quebecois. Quarterly Journal of Speech, 73, 133-150.; Greene, R. (1998). The Aesthetic Turn and the Rhetorical Perspective on Argumentation. Argumentation & Advocacy, 35(1), 19.; Miller, C. R., and Shepherd, D. (2004). Blogging as Social Action: A Genre Analysis of the Weblog. Into the Blogosphere: Rhetoric, Community, and Culture of Weblogs, 18. ↩
- Greene, 1998 ↩